In Python, a “String” is a series/sequences of characters. that can represent text, symbols, or binary data. Strings can be either byte strings or Unicode strings. “Bytes” are sequences of “8” bit integers that represent characters in a specific encoding, and “Unicode” is a standard that represents characters from all languages in the world. Sometimes it is necessary to modify the string to Unicode in Python. To accomplish this, different methods are utilized in Python.
This article presents a detailed guide on converting a string to Unicode in Python using numerous examples.
How to Convert/Transform Python String to Unicode?
To convert string to Unicode in Python, the following methods are used in Python:
Note: Check out this dedicated guide to deeply understand Unicode string literal in Python.
Method 1: Convert String to Unicode in Python Using “format()” and “ord()” Method
The “format()” method is used to format the string by inserting the specified values inside the string. The “ord()” method is utilized to retrieve the Unicode of the specified character/string. Here is an example code:
print(str1,'\n')
print(''.join(r'\u{:04X}'.format(ord(ele)) for ele in str1))
In the above code:
- The regular string “Linuxhint” is assigned to a variable named “str1”.
- The “ord()” method retrieves the Unicode for each string character by iterating over the given string.
- The generator expression then uses the specified formatted string literal to convert the Unicode to a hexadecimal representation with four digits and the prefix “\u”.
- Lastly, the “join()” method joins all these strings with an empty separator and prints the result.
Output
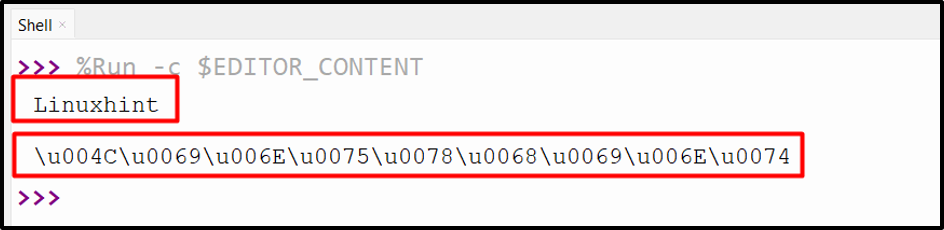
The input string has been converted into a Unicode.
Method 2: Convert String to Unicode in Python Using “re.sub()” and “ord()” Method
The “re.sub()” method is used to find all the specified pattern occurrences/instances in the specified string and replace them. This method can be used along with the “ord()” method and “lambda” function to convert string to Unicode in Python:
str1 = 'Python'
print(str1,'\n')
print(re.sub('.', lambda x: r'\u % 04X' % ord(x.group()), str1))
In the above code:
- The “re” module is imported.
- The “sub()” method takes three arguments.
- The first argument matches any character except a new line, and the second argument is a function that takes a match object (x) and returns a string. The third argument is a string composed of “\u”, a space, and a four-digit hexadecimal number.
- The Unicode number is obtained by applying the “ord()” function to the matched character (x.group()), which returns its Unicode as an integer.
- Lastly, the “sub()” function returns a new string where every character in the input string is replaced by its Unicode representation.
Output
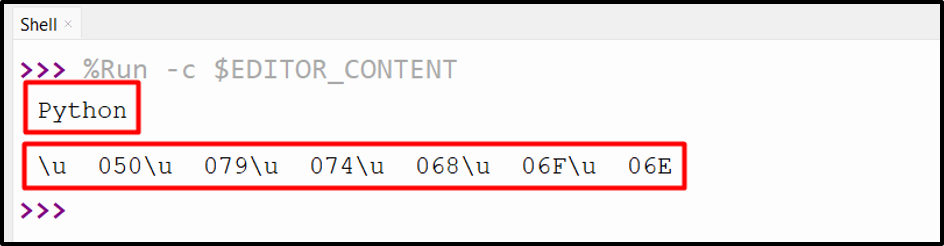
The above output shows that the string has been converted into a Unicode.
How to Convert/Transform a Unicode to a Python String?
The “str()” function in Python is utilized to convert/transform the Unicode string to a string. The following example code will help you understand this better:
print("Converted String: ",str(str1))
In the above code:
- The “u” is placed before the string to create a Unicode string literal.
- The “str()” function converts/transforms the Unicode string to a Python string.
Output
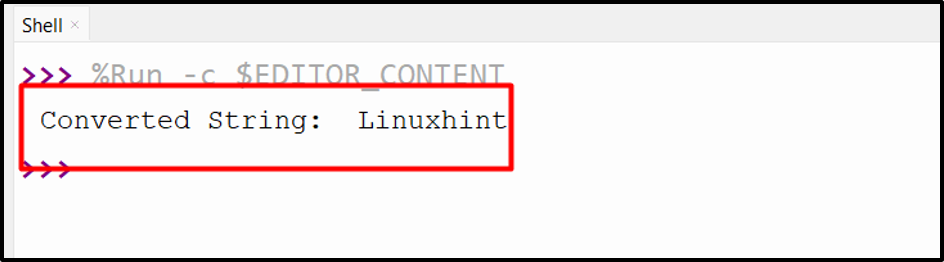
The Unicode string has been converted into a string.
Note: In Python “2.x”, Unicode strings are handled by prefixing them with “u”, but now Python “3.x” uses Unicode by default, so a prefix “u” is not required.
Conclusion
In Python, the “format()” or the “re.sub()” methods are used with the “ord()” method to convert strings to Unicode characters. The “format()”, “ord()”, and “join()” methods are used to convert string literals into Unicode code. The “re.sub()”, “ord()”, and lambda functions can also be used to convert string literals into Unicode code. This tutorial presented a detailed overview of the conversion of string to Unicode in Python using numerous examples.