NLP enables the machines to effectively process and understand the intricate nuances of linguistic structures, semantics, and pragmatics which empower them to perform the tasks such as language translation, sentiment analysis, information extraction, and dialogue generation, among others.
It is a fundamental feature in building a question-answering system that allows a machine to generate the answer to a given question in natural human language. You will often find the NLP applications in customer service portals, personalized chatting, and more.
In this article, we will explore how we can configure a basic NLP application using the basic machine learning techniques and the Milvus vector database which plays a crucial role in such applications.
This article demonstrates the implementation of a question-answering system which utilizes the semantic similarity matching. The overall procedure is as follows:
- Acquire a substantial collection of questions and their corresponding answers within a specific domain that constitutes a standardized question set.
- Utilize the BERT (Bidirectional Encoder Representations from Transformers) model to transform these questions into feature vectors which are then stored in Milvus—an open-source vector database. Simultaneously, Milvus assigns a unique vector ID to each feature vector.
- Persist the representative question IDs and their associated answers in PostgreSQL, a powerful relational database management system.
- When a user presents a question:
The BERT model converts the question into a feature vector representation. Milvus performs a similarity search which seeks the most similar feature vector based on its stored collection. MySQL retrieves the corresponding answer that is linked to the identified question ID.
Through this approach, the question-answering system effectively leverages the semantic similarity matching, BERT model embeddings, Milvus vector database, and PostgreSQL to retrieve the answers based on user queries accurately.
The system architecture is as depicted in the following image:
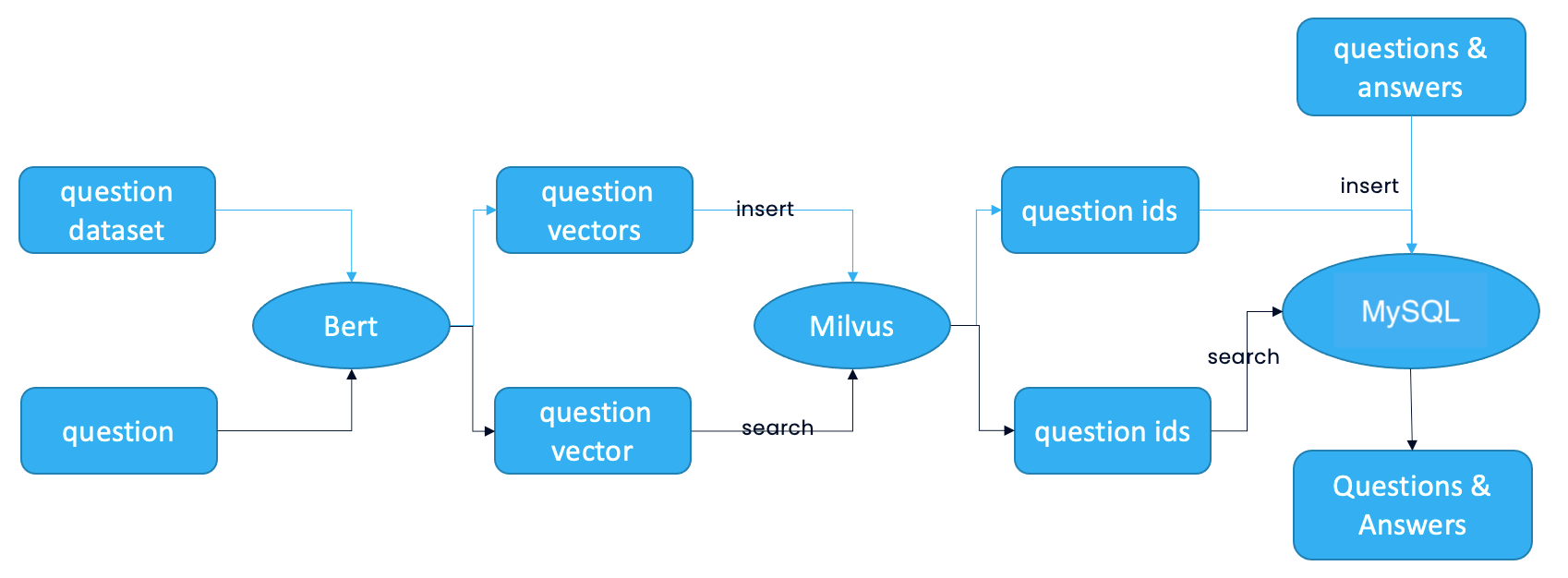
Source: Milvus.
Requirements:
For this project, you are required with the following:
- A Question and Answer Dataset for your application
- Python 3.10+
- BERT
- MySQL
- Jupyter Lab
- Towhee
Data Preparation
The first step is to obtain a dataset that contains the question-and-answer pairs. For this, we use the WikiQA dataset. This dataset contains the questions from the Bing query logs.
You can download the dataset in the following link:
https://www.microsoft.com/en-us/download/details.aspx?id=52419
Installing the Dependencies
The next step is to install the required dependencies. We can use the pip commands as follows:
This should install the required dependencies.
Create a Notebook and Load the Data
Next, open up the Jupyter Notebook and create a notebook to store the code that you will use to train the model. Ensure that it is in the exact location as the “WebQA.tsv” file that you downloaded earlier.
Using Pandas, read the data as follows:
df = pd.read_table("./WikiQA.tsv")
Next, you can check the head of the data as follows:
df.head()
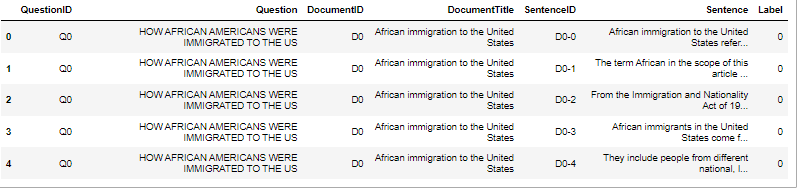
To use the dataset to get the answers, let’s first define the dictionary. The dictionary contains the actual question ID and the answer to that question.
Create the Milvus Collection
The next step is to create a Milvus collection to store the dataset. Assuming that you have Milvus running and you have the Pymilvus SDK installed, we can run the code as follows:
connections.connect(host='127.0.0.1', port='19530')
def create_milvus_collection(collection_name, dim):
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='id', dtype=DataType.VARCHAR, descrition='ids', max_length=500, is_primary=True, auto_id=False),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, descrition='embedding vectors', dim=dim)
]
schema = CollectionSchema(fields=fields, description='reverse image search')
collection = Collection(name=collection_name, schema=schema)
# create IVF_FLAT index for collection.
index_params = {
'metric_type':'L2',
'index_type':"IVF_FLAT",
'params':{"nlist":2048}
}
collection.create_index(field_name="embedding", index_params=index_params)
return collection
collection = create_milvus_collection('question_answer', 768)
Conclusion
We explored how we can build a question-answering system using NLP and Milvus and the basic dataset.