Algorithms cannot determine the importance of a word on their own and hence tokenizers are used. These tokenizers assign scores to the text in which their sequence can be determined along with their worth. The probabilities and further calculations are performed on this score to generate meaningful output.
This article provides a practical demonstration of the usage of the AutoTokenizer in Transformer.
What is the AutoTokenizer in Transformers?
AutoTokenizer originates from the Auto Class. It automatically infers and loads the correct architecture. It can be used with many built-in functions such as from_pretrained() which saves time and effort for the user by providing resources and fast computation to load and train the model.
How to Use AutoTokenizer in Transformers?
In Natural Language Processing, we provide data to algorithms in such a way that can be understood and processed by them. Tokenizers process this raw data into a format that can be understood and processed by the model by allocating them a score value that determines the importance of text in NLP.
Here are some steps mentioned in which we can use the AutoTokenizer class of Transformers:
Step 1: Install Transformers
To install transformers, use the “pip” command as seen in the following command:
Step 2: Import Libraries
From transformers, we can import the pipeline, AutoTokenizer, and AutoModelForSequenceClassification classes by using the following command:
model=AutoModelForSequenceClassification.from_pretrained('distilbert-base-uncased-finetuned-sst-2-english')
tokenizer=AutoTokenizer.from_pretrained('distilbert-base-uncased-finetuned-sst-2-english')

In the above code,
-
- AutoModelForSequenceClassification is a generic class used for specific sequence classification purposes.
- The “from_pretrained()” method returns the correct model by analyzing the model type.
- AutoTokenizer is also one of the generic classes of the Auto class and is instantiated as a tokenizer class.
Step 3: Apply Pipelines
Next, we will apply the pipeline() method to these tokenizer variables to generate human-readable outputs:
output=classifier("The movie could be better")
print(output)

The output of the command is given below. Here, in this tutorial, we have used Sentimental analysis on the sentence and therefore, in the output, it has classified the sentence as “Negative” and has also provided the accuracy of the output:

The link to the Google Colab is also mentioned.
How to Use AutoTokenizers with a Model in Transformers?
After installing the transformers library, provide the following code to use Tokenizers with models:
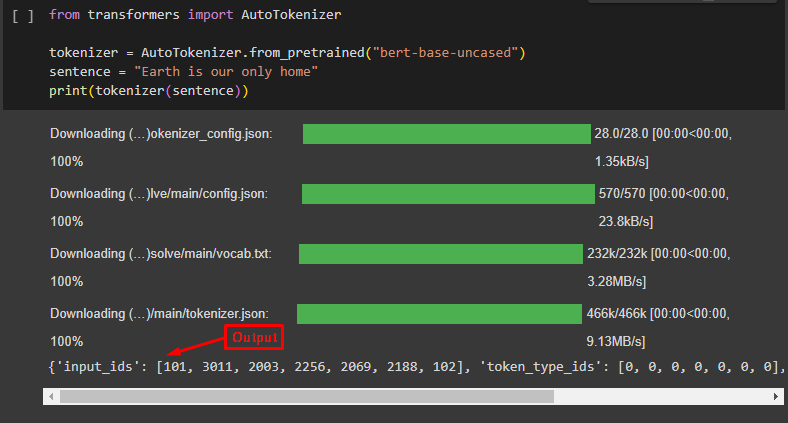
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
sentence = "Earth is our only home"
print(tokenizer(sentence))
The output of the code is given below:
Here is the link to the Google Colab:
Conclusion
To use AutoTokenizers, install the transformers library, import AutoTokenizer from transformers, and specify a model name with the from_pretrained() function. With Tokenization, we can ensure the correct output along with the accurate prediction. This article is a step-by-step tutorial for using AutoTokenizers in Transformers.
About the author
Syed Minhal Abbas
I hold a master's degree in computer science and work as an academic researcher. I am eager to read about new technologies and share them with the rest of the world.