This article provides a comprehensive guideline on how to work with AutoFeatureExtractor in Transformers.
How to Work with AutoFeatureExtractor in Transformers?
A feature extractor works on the audio and vision models and is responsible for recognizing and extracting the input features. These features range from sequence to Log-Mel Spectrogram features, image features extraction, emotions extractions, etc.
Let us explore some steps in which we can implement AutoFeatureExtractor in Transformers:
Step 1: Install Transformer
To get started with AutoFeatureExtractor, we will first install the transformers library using the pip command:
Step 2: Install Pydub Library
In this tutorial, we are working with the audio models. Therefore, install the pydub library that helps in manipulating the audio with a simple and easy-to-use high-level interface. To install this library, provide the following command:
Step 3: Import AudioSegment
After installing the pydub library, import “AudioSegment” from the pydub library. Furthermore, import the numpy library which is used for the computation in Machine Learning and deep learning:
import numpy as np

Step 4: Convert the File
Now, use the AudioSegment() function to convert the MP3 audio file to the “pydub” object which will be further provided to the AutoFeatureExtractor for computation. To convert the file, provide the following command:
print(audio)
In this code, we have uploaded a file to the Google Colab and provided its path to the Audiosegment.from_mp3() function.

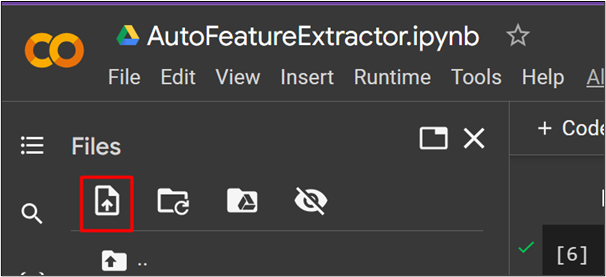
To upload an mp3 file to Google Colab, click on the highlighted option as seen in below screenshot:
After that, select the file and upload it to Google Colab. Note that this file will only retail for the current session of the Google Colab:
Step 5: Convert to Numpy Array
Now we will convert this pydub object to a Numpy array. For this purpose, we have used the bytearray() function which will return a byte array object i.e., array of bytes:

Step 6: Extract Features
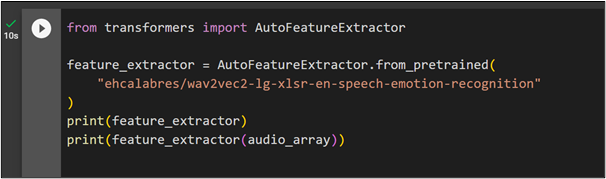
To extract features using AutoFeatureExtractor, first import the “transformers” library. After that, import the AutoFeatureExtractor library. Using the from._pretrained() function, we will first train the model and assign its values to the “feature_extractor” variable. Then, provide the value of “audio_array” to the feature_extractor() method that extracts the features of the audio file:
feature_extractor = AutoFeatureExtractor.from_pretrained(
"ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
)
print(feature_extractor)
print(feature_extractor(audio_array))
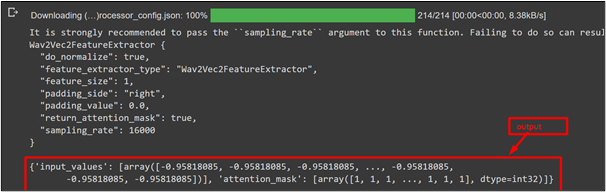
The output is given in the form of numerical values. The model has returned an array. “Attention mask” is also given which is in the form of an array:
That is all from this guide. The link to the above Google Colab is also mentioned.
Conclusion
To implement AutoFeatureExtractor, use AutoFeatureExtractor() from the “transformers” library, and provide a model and a pydub audio object to it. AutoFeatureExtractor is an important utility of the Transformer library, and it falls under the generic category of Auto Class. This article is a step-by-step guide for working with AutoFeatureExtractor in Transformers.