In this article, we will discuss how to allocate CUDA memory via the “pytorch_cuda_alloc_conf” method.
What is the “pytorch_cuda_alloc_conf” Method in PyTorch?
Fundamentally, the “pytorch_cuda_alloc_conf” is an environment variable within the PyTorch framework. This variable enables the efficient management of the available processing resources which means that the models run and produce results in the least possible amount of time. If not done properly, the “CUDA” computation platform will display the “out of memory” error and affect runtime. Models that are to be trained over large volumes of data or have large “batch sizes” can produce runtime errors because the default settings might not be enough for them.
The “pytorch_cuda_alloc_conf” variable uses the following “options” to handle resource allocation:
- native: This option uses the already available settings in PyTorch to allocate memory to the model in progress.
- max_split_size_mb: It ensures that any code block larger than the specified size is not split up. This is a powerful tool to prevent “fragmentation”. We will use this option for the demonstration in this article.
- roundup_power2_divisions: This option rounds up the size of the allocation to the nearest “power of 2” division in megabytes (MB).
- roundup_bypass_threshold_mb: It can round up the allocation size for any request listing more than the specified threshold.
- garbage_collection_threshold: It prevents latency by utilizing available memory from the GPU in real time to ensure that the reclaim-all protocol is not initiated.
How to Allocate Memory Using the “pytorch_cuda_alloc_conf” Method?
Any model with a sizable dataset requires additional memory allocation that is greater than that set by default. The custom allocation needs to be specified keeping the model requirements and available hardware resources in consideration.
Follow the steps given below to use the “pytorch_cuda_alloc_conf” method in the Google Colab IDE to allocate more memory to a complex machine-learning model:
Step 1: Open Google Colab
Search for Google Colaboratory in the browser and create a “New Notebook” to start working:
Step 2: Set up a Custom PyTorch Model
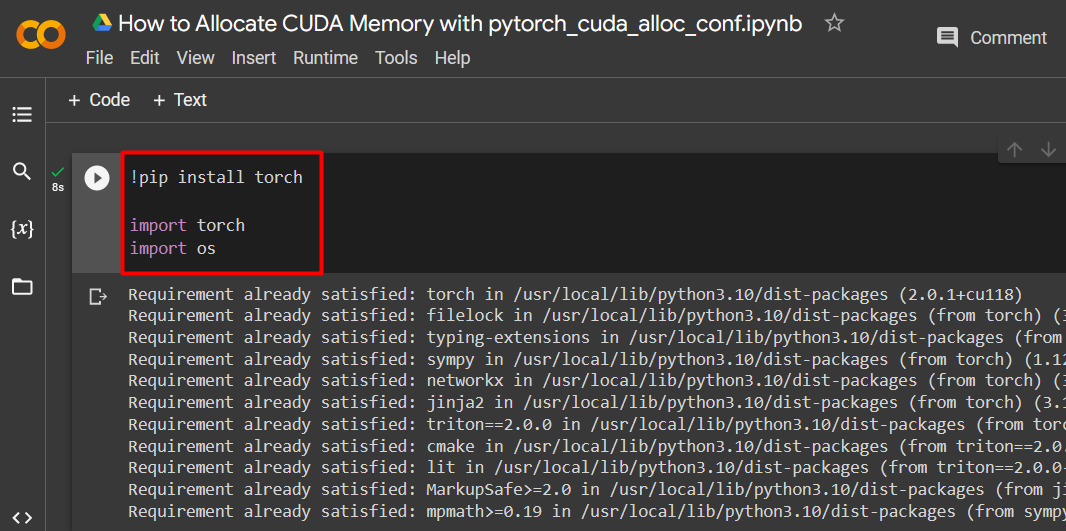
Set up a PyTorch model by using the “!pip” installation package to install the “torch” library and the “import” command to import “torch” and “os” libraries into the project:
import torch
import os
The following libraries are needed for this project:
- Torch – This is the fundamental library upon which PyTorch is based.
- OS – The “operating system” library is used to handle tasks related to environment variables such as “pytorch_cuda_alloc_conf” as well as the system directory and the file permissions:
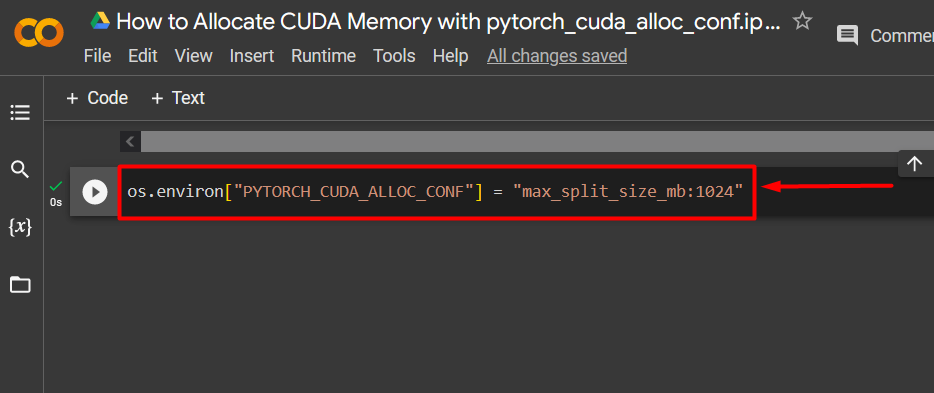
Step 3: Allocate CUDA Memory
Use the “pytorch_cuda_alloc_conf” method to specify the maximum split size using “max_split_size_mb”:
Step 4: Continue with your PyTorch Project
After having specified “CUDA” space allocation with the “max_split_size_mb” option, continue working on the PyTorch project as normal without fear of the “out of memory” error.
Note: You can access our Google Colab notebook at this link.
Pro-Tip
As mentioned previously, the “pytorch_cuda_alloc_conf” method can take any of the above-provided options. Use them according to the specific requirements of your deep learning projects.
Success! We have just demonstrated how to use the “pytorch_cuda_alloc_conf” method to specify a “max_split_size_mb” for a PyTorch project.
Conclusion
Use the “pytorch_cuda_alloc_conf” method to allocate CUDA memory by using any one of its available options as per the requirements of the model. These options are each meant to alleviate a particular processing issue within PyTorch projects for better runtimes and smoother operations. In this article, we have showcased the syntax to use the “max_split_size_mb” option to define the maximum size of the split.