Pandas.Read_CSV
The pandas.read_csv() is used to read the comma separated value (CSV) file into the DataFrame. It imports all the rows and columns with row indices (starting from 0) if no parameter is passed to this function. It stores the missing values that are present in the CSV as NaN in the DataFrame.
Syntax:
Let’s see the syntax and some parameters that are passed to this function:
- index_col (by default = None) – The existing column/s are utilized as index for the DataFrame. If not, the “Index” column is “None” and the row indices are assigned starting from 0. It can also be possible to set the MultiIndex for the DataFrame by passing a list of existing columns to this parameter.
- usecols (by default = None) – We can include specific columns in the DataFrame from CSV during import. The column labels that are to be included are passed as a parameter through the list (separated by comma).
- nrows (by default = None) – The number of rows to be read into the DataFrame from the CSV file. It takes an integer that specifies the total number of rows to be included from the first row.
- skiprows (by default = None) – This parameter takes a list of row numbers which is used to skip the specified rows
- names – The custom column names can be specified to the DataFrame using this parameter. The list of column names (without duplicates) are provided to this parameter. Make sure that you need to set the header parameter to 0.
- skipfooter (by default = 0) – This parameter takes an integer value which is used to skip the number of lines from the bottom of the CSV file.
- na_values (by default = None) – We can consider the missing values by specifying this parameter. It takes the existing values in the CSV and considers them as missing values in the DataFrame. It takes a single item, a list of items, or a dictionary.
- dtype (by default = None) – It specifies the data type for the columns {“Column_Name”: datatype}.
- converters (by default = None) – It is a dictionary of functions that is used to convert the values in certain columns.
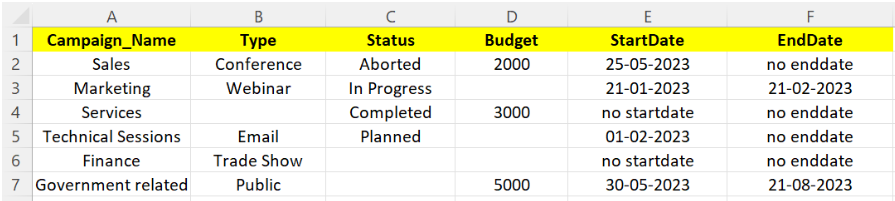
We use the following CSV (Company_Campaign.csv) for all the examples that are discussed in this guide:
Example 1: Read_CSV() with No Parameters
Let’s read the previous CSV file into the DataFrame_from_CSV object using the read_csv() function without passing any parameter.
# read_csv() with no parameters
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv')
print(DataFrame_from_CSV)
Output:
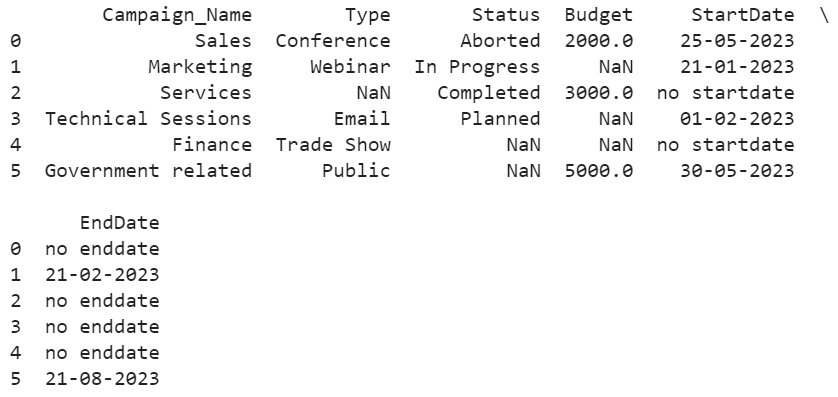
You will see that the CSV data is imported into the DataFrame with all rows and columns. The row indices for these six recorda are 0, 1, 2, 3, 4, and 5.
Example 2: Index_Col Parameter
- Single Index – Set the “Campaign_Name” column as an index to the DataFrame.
- MultiIndex – Set the “Campaign_Name” column as an index to the DataFrame.
# Single Index
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv',index_col='Campaign_Name')
print(DataFrame_from_CSV)
# MultiIndex
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv',index_col=['Campaign_Name','Type'])
print(DataFrame_from_CSV)
Output:
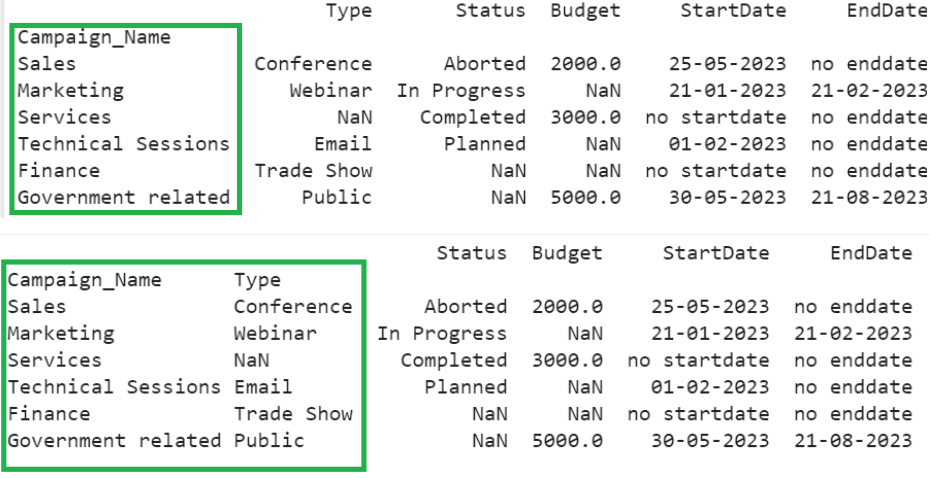
In the first output, the “Campaign_Name” acts as an index for this DataFrame and both “Campaign_Name” and “Type” act as indices in the second output.
Example 3: Usecols Parameter
Pass the “StartDate”,”Campaign_Name” and “Type” columns to the “usecols” parameter through the list. The DataFrame is created from the CSV file with these three columns.
# read_csv() with usecols parameter
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv',usecols=["StartDate","Campaign_Name","Type"])
print(DataFrame_from_CSV)
Output:

The DataFrame_from_CSV is created with these three columns only.
Example 4: Nrows Parameter
Create the DataFrame from the CSV by passing only the first four records using the “nrows” parameter.
# read_csv() with nrows parameter
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv',nrows=4)
print(DataFrame_from_CSV)
Output:
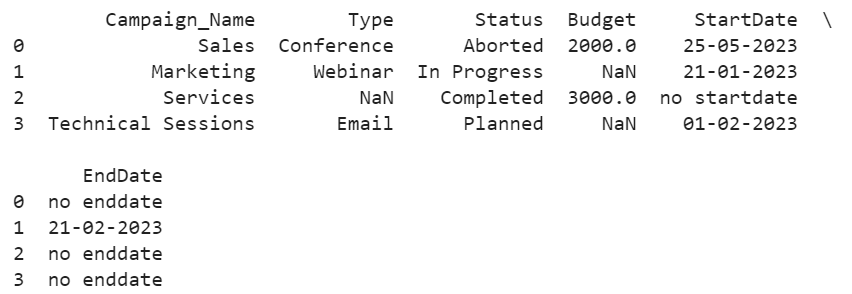
The DataFrame_from_CSV holds only four rows with the indices as 0, 1, 2, and 3.
Example 5: Skiprows Parameter
Create the DataFrame from the CSV by skipping the first, third, and fourth row.
# read_csv() with skiprows parameter
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv',skiprows=[1,3,4])
print(DataFrame_from_CSV)
Output:
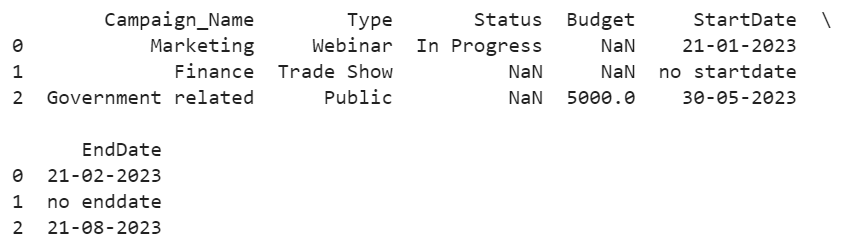
The DataFrame_from_CSV is created by skipping the specified rows.
Example 6: Names Parameter
Let’s create the DataFrame from the CSV with our own column labels [“A”,”B”,”C”,”D”,”E”,”F”] instead of [“Campaign_Name”, “Type”, “Status”, “Budget”, “StartDate”, “EndDate”]. Pass your own label list to the “names” parameter.
# read_csv() with names parameter
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv',names=['A','B','C','D','E','F'],header=0)
print(DataFrame_from_CSV)
Output:

The DataFrame_from_CSV is created with the specified column labels.
Example 7: Skipfooter and Engine Parameters
Let’s create the DataFrame from the CSV by skipping the last three rows present in the CSV file using the “skipfooter” parameter. Also, set the “engine” parameter to “Python”.
# read_csv() with skipfooter & engine parameters
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv',skipfooter=3,engine='python')
print(DataFrame_from_CSV)
Output:

The DataFrame_from_CSV is created from the CSV by skipping the last three rows.
Example 8: Na_Values Parameter
The StartDate and EndDate columns hold the missing data in the form of “no startdate” and “no enddate” values. So, we replace these values with NaN with the help of the “na_values” parameter. By default, this parameter replaces the specified values with “NaN”. Let’s provide “no startdate” and “no enddate” to “na_values”.
# read_csv() with na_values parameter
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv',na_values = ["no startdate","no enddate"])
print(DataFrame_from_CSV)
Output:
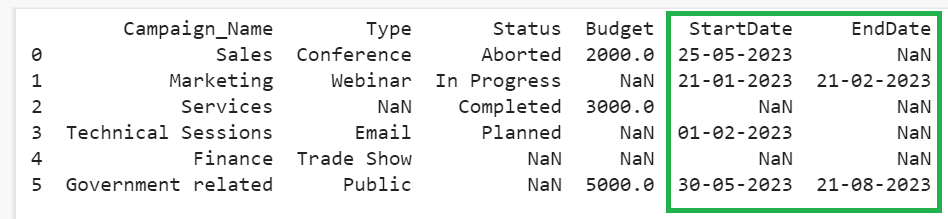
The DataFrame_from_CSV is created from the CSV with the StartDate and EndDate as NaN instead of “no startdate” and “no enddate”.
Example 9: Dtype and Converters Parameters
Change the datatype of the “Budget” column to integer while loading it into the DataFrame from the CSV file by specifying the “dtype” parameter. We need to pass a dictionary with the key as Budget (column name) and the value as int (date type).
# read_csv() with dtype parameter
DataFrame_from_CSV = pandas.read_csv('Company_Campaign.csv',converters={'Budget':lambda x: 0 if x == 'NaN' else x},dtype={'Budget':'int'})
print(DataFrame_from_CSV)
Output:
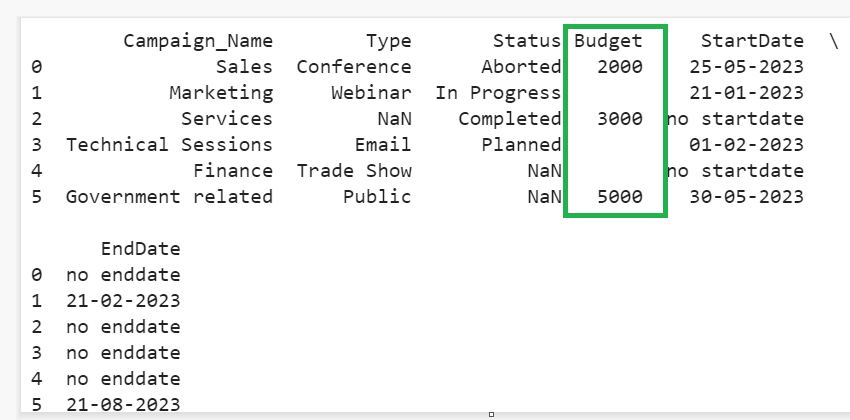
Now, the data type is integer. The “Budget” column holds the missing values. So, we get an error while converting the datatype. To get rid of that, we specify the “converters” parameter that replaces “empty” wherever NaN is found.
Conclusion
We learned how to import CSV into the Pandas DataFrame using the pandas.read_csv() function. All the important parameters that have to be passed to this function are discussed with a separate example in detail. The header parameter is set to 0 if you are passing the custom column labels. Otherwise, the actual column labels from the CSV are created as a row in the Pandas DataFrame. It is good to specify the “engine” parameter with the other parameters to get rid of legacy warnings.