Pandas.Read_Parquet()
The pandas.read_parquet() function is used to load the parquet from the path (file/URL). It returns the Pandas DataFrame.
Syntax:
Let’s see the syntax of the pandas.read_parquet() function with the parameters in detail:
- file – We can directly pass the parquet from the location.
- columns – If you want to load the parquet file into DataFrame with specific columns, the columns are specified in a list and assigned to the “columns” parameter. All columns are loaded if it is not specified.
- engine – The parquet is an open source and there are many different Python libraries and engines that can be used to read the parquet. The supported engines are “auto” (by default), “pyarrow”, and “fastparquet”.
- storage_options – (by default = None) We can specify the storage connection with the localhost, username, password, etc. as additional options.
Parquet File Creation from Pandas DataFrame
Before reading the parquet file into the DataFrame object, we need a parquet file. So, let’s create a DataFrame and generate a “camps.parquet” parquet file from the DataFrame.
camps = pandas.DataFrame([['Marketing','Conference','Completed',1200],
['Sales','Trade show','Completed',1500],
['Service','Conference','Planned',2500],
['Technical','Conference','Aborted',5000],
['Others','Public Relations','Planned',6000],
],columns=['Campaign_Name', 'Campaign_Type', 'Status', 'Budget'])
# Generate parquet file from the above DataFrame
camps.to_parquet('camps.parquet')
The parquet file is generated. Let’s utilize this to read into the Pandas DataFrame.

Example 1: With the Default Parameters
Let’s read the “camps.parquet” file to the DataFrame by passing the file name to the read.parquet() function. By default, it reads all the columns and the engine is “auto”.
# Read camps.parquet file
DataFrame_from_parquet = pandas.read_parquet('camps.parquet')
print(DataFrame_from_parquet)
Output:

All the columns are loaded into the DataFrame from the parquet file.
Example 2: With the “Columns” Parameter
Now, we read the parquet file into the DataFrame by passing the “columns” parameter.
- Read the camps.parquet file with the “Status” and “Budget” columns.
- Read the camps.parquet file with the “Campaign_Name” column.
# Read camps.parquet file with Status and Budget
DataFrame_from_parquet = pandas.read_parquet('camps.parquet',columns=['Status','Budget'])
print(DataFrame_from_parquet,"\n")
# Read camps.parquet file with Campaign_Name column
DataFrame_from_parquet = pandas.read_parquet('camps.parquet',columns=['Campaign_Name'])
print(DataFrame_from_parquet)
Output:
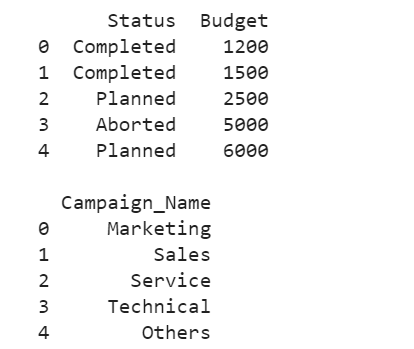
In the first output, the DataFrame is created with two columns – “Status” and “Budget”. In the second output, the DataFrame is created with one column – “Campaign_Name”.
Example 3: With the Fastparquet Engine
The fastparquet is a Python implementation of the parquet format which integrates big-data workflows in Python. In your Python Env, install the fastparquet module first.
Command: pip install fastparquet
Let’s set the engine to “fastparquet”.
import fastparquet
# Read camps.parquet file with engine as 'fastparquet'
DataFrame_from_parquet = pandas.read_parquet('camps.parquet',engine='fastparquet')
print(DataFrame_from_parquet,"\n")
Output:

Example 4: With the Pyarrow and PyArrow Engines Utility Function
Basically, Pyarrow allows data sharing between the data science tools and languages in an efficient way. Pandas uses the PyArrow to improve the API performance. Let’s read the parquet file by setting the engine to “pyarrow”.
# Read camps.parquet file with engine as 'pyarrow'
DataFrame_from_parquet = pandas.read_parquet('camps.parquet',engine='pyarrow')
print(DataFrame_from_parquet,"\n")
Output:
While working with larger datasets, the processing speed is an important factor. Using the PyArrow utility function is the best option which speeds up the load.
- First, we need to load the file using the read_table() function that is available in the pyarrow.parquet module.
- Using the to_pandas() function, we convert the table data into the Pandas DataFrame.
import pyarrow.parquet
# Read Table from camps.parquet
table = pyarrow.parquet.read_table('camps.parquet')
print(table,"\n")
# Convert Table to pandas DataFrame
DataFrame_from_parquet = table.to_pandas()
print(DataFrame_from_parquet)
Output:
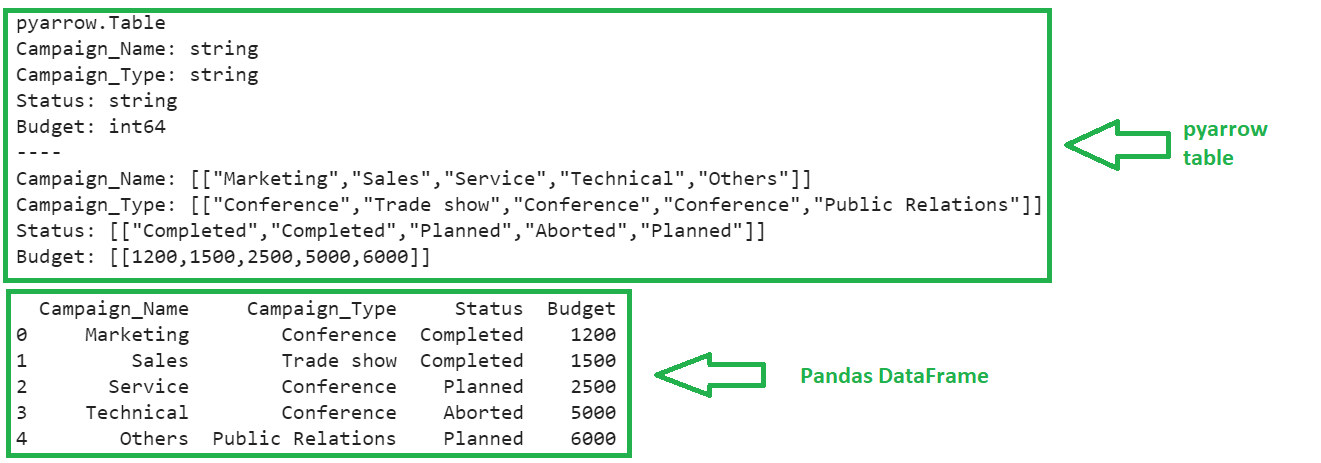
The first output is the pyarrow table and the second output is the Pandas DataFrame is created from the pyarrow table.
Conclusion
Now, we are able to load the parquet file into the Pandas DataFrame using the pandas.read_parquet() function. In this guide, we learned the different examples by considering the parameters with the output screenshots. To improve the data processing speed while loading the parquet file into the Pandas DataFrame, we utilized the PyArrow utility function. Specific columns can be loaded into the Pandas DataFrame by specifying the “columns” parameter.