In statistics and mathematics, the “Covariance” is used to determine the strength of two or multiple sets of random variables. Basically, it is an indicator of the extent to which two variables are related or dependent on each other. In Python, the “DataFrame.cov()” method is used to determine the covariance between Pandas DataFrame columns.
This write-up will explain detailed information for calculating covariance using numerous examples and via the following content:
- What is the “cov()” Method in Python?
- Computing the DataFrame Columns Covariance
- Computing the DataFrame Columns Covariance Having NaN Values
- Computing the Covariance of the Series
What is the “DataFrame.cov()” Method in Python?
The “DataFrame.cov()” method of the “Pandas” module is used to compute/calculate the pairwise column covariance and remove or exclude the NA/Null values. The syntax of the “DataFrame.cov()” method is shown below:
In the above syntax:
- The “min_periods” parameter (optional) indicates a minimum number of observations needed for retrieving valid results.
- The “ddof” optional parameter represents the delta degree of freedom. By default, the value is “1”.
- The “numeric_only” parameter is used to include only the float, int/integers, or Boolean data.
Return Value
The “DataFrame.cov()” method retrieves the DataFrame that specifies the covariance matrix of the series of the DataFrame.
Example 1: Computing the DataFrame Columns Covariance Using the “DataFrame.cov()” Method
The “df.cov()” method is used to calculate the covariance among all the given Pandas DataFrame columns, and here is an example code:
df = pandas.DataFrame({"X":[9, 6, 6, 2],"Y":[11, 2, 2, 6],"Z":[2, 6, 8, 9],"V":[9, 2, 2, 8]})
print(df, '\n')
print(df.cov())
The above code retrieves the covariance matrix as shown in the below snippet:
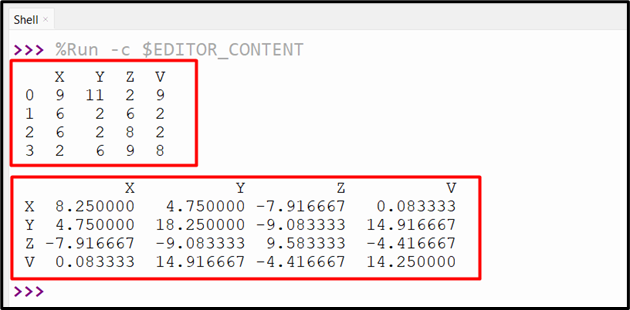
Example 2: Computing the DataFrame Columns Covariance Having NaN Values Using the “DataFrame.cov()” Method
In this example, the DataFrame is created with some “NaN” values. As from the definition, the “DataFrame.cov()” method ignored the “NaN” values while calculating the covariance between the DataFrame columns. Let’s perform this via the following code:
df = pandas.DataFrame({"X":[2, 9, None, 4],"Y":[None, 2, 4, 9],"Z":[4, 9, 8, 2],"V":[2, 4, 2, None]})
print(df, '\n')
print(df.cov())
When the above code is executed, the covariance matrix between the columns by ignoring NaN values has been retrieved:
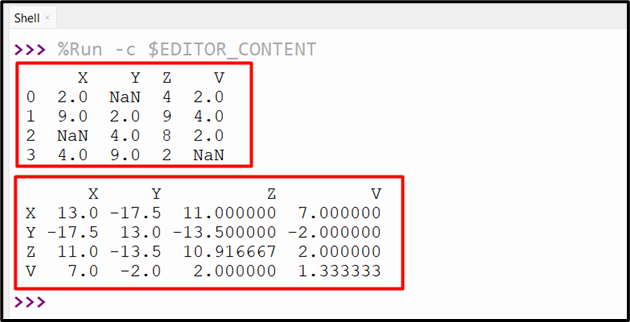
Example 3: Computing the Covariance of the Series Using the “Series.cov()” Method
The “Series.cov()” method is used to compute the covariance of the series with another series by ignoring the NaN values. The below code is utilized to create/construct two series objects using the “pandas.Series()” method and compute the covariance between the series objects using the “Series.cov()” method.
ser1 = pandas.Series([5,4,5,2])
ser2 = pandas.Series([9,7,6,5])
print(ser1, '\n')
print(ser2, '\n')
print("The covariance value: ", ser1.cov(ser2))
After executing the above-given code, the following output will be generated:
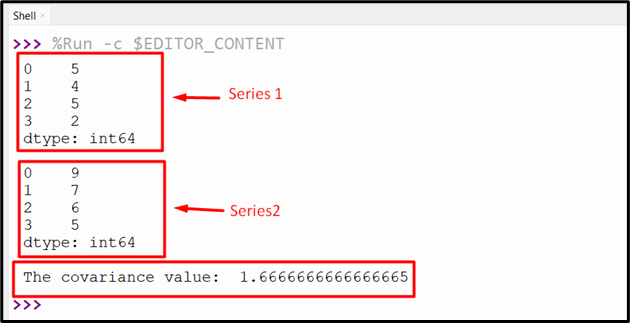
Conclusion
In Python, the “DataFrame.cov()” method of the “Pandas” module computes/calculates the pairwise column covariance and excludes the NA/Null values. We can also determine the covariance between two series objects. This Python tutorial demonstrated an in-depth guide on determining the Pandas covariance using numerous examples.