SQLite is an RDBMS, which is used to manage the data of the database, which is placed in the rows and columns of the table. This writeup helps us to understand what is UNIQUE CONSTRAINT in SQLite as well as how it works in SQLite.
What is the UNIQUE constraint in SQLite
A UNIQUE constraint ensures the data in the column should be unique, which means no fields of the same column contain similar values. For example, we create a column, email, and define it with the UNIQUE constraint so it will ensure that no email inserted in the column should be the same as the other record of the column.
What is the difference between the UNIQUE and the PRIMARY KEY constraint in SQLite
Both constraints, PRIMARY KEY and UNIQUE ensure that no duplicate entry should be inserted in the table, but the difference is; the table should contain only one PRIMARY KEY whereas the UNIQUE constraint can be used for more than one column in the same table.
How UNIQUE constraint be defined in SQLite
The UNIQUE constraint can be defined either on the single column or the multiple columns in SQLite.
How UNIQUE constraint be defined to a column
A UNIQUE constraint can be defined as a column, by which it can ensure that no similar values can enter in any field of that column. The general syntax of defining the UNIQUE constraint on a column is:
The explanation of this is:
- Use the CREATE TABLE clause to create a table and replace the table_name
- Define a column name with its datatype by replacing the column1 and datatype
- Use the UNIQUE clause to a column that you are going to define with this constraint
- Define the other columns with their datatypes
To understand this syntax, consider an example of creating a table for students_data which have two columns, one is of std_id and the other is of st_name, were to define the column, std_id, with the UNIQUE constraint so that none of the students can have similar std_id as:

Insert the values using:

Now, we will add another student name where the std_id is 1:

We can see from the output, it generated the error of inserting the value of std_id because it was defined with the UNIQUE constraint which means no value can be duplicated with the other values of that column.
How is the UNIQUE constraint defined for multiple columns
We can define multiple columns with the UNIQUE constraint, which ensures that there is no duplication of the data inserted in all rows at the same time. For example, if we have to choose cities for a trip to three groups of people (A, B, and C), we cannot assign the same city to all of the three groups, this can be done by using the UNIQUE constraint.
For example, these three scenarios can be possible:
| Group_A | Group_B | Group_C |
|---|---|---|
| Florida | Florida | Boston |
| New York | Florida | Florida |
| Florida | Florida | Florida |
But the following scenario is not possible if we are using the UNIQUE constraints:
| Group_A | Group_B | Group_C |
|---|---|---|
| Florida | Florida | Florida |
The general syntax of using the UNIQUE constraint to the multiple columns is:
The explanation of this is:
- Use the CREATE TABLE clause to create a table and replace the table_name with its name
- Define a column name with its datatype by replacing the column1 and datatype
- Use the UNIQUE clause and type the names of the columns in the () that you are going to define with this constraint
To understand this we will consider the above example, and will run the following command to create a table of Trip_data:

We will insert the values of assigning their cities:

Now, we will insert the same city in all the columns of Trip_data:

We can see from the output, the duplication of the data in all the columns which are defined by the UNIQUE constraint is not allowed and the generated error of the UNIQUE constraint failed.
How to add the UNIQUE constraint to the existing table
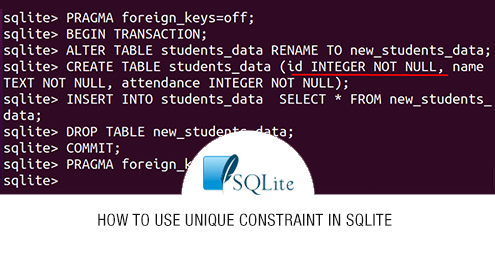
In SQLite, we can add the constraint by using the ALTER command, for example, we have a table students_data with columns std_id, std_name, we want to add a constraint std_id to the table, students_data:
- Use the command “PRAGMA foreign keys=OFF” to off the foreign key constraints
- Use the command “BEGIN TRANSACTION;”
- Use the command “ALTER TABLE table_name RENAME TO old_table;” to rename the actual table
- Create a table again with the previous name, but while defining column this time, also define the UNIQUE constraints
- Copy the data of the previous table (whose name is changed), to the new table (which has the previous name)
- Delete the first table(whose name was changed)
- Use “COMMIT”
- USE the command “PRAGMA foreign keys=ON”, to on the foreign keys constraints
ALTER TABLE students_data RENAME TO new_students_data;
CREATE TABLE students_data (id INTEGER NOT NULL UNIQUE, name TEXT NOT NULL, attendance INTEGER NOT NULL);
INSERT INTO students_data SELECT * FROM new_students_data;
DROP TABLE new_students_data;
COMMIT;
PRAGMA foreign_keys=ON;
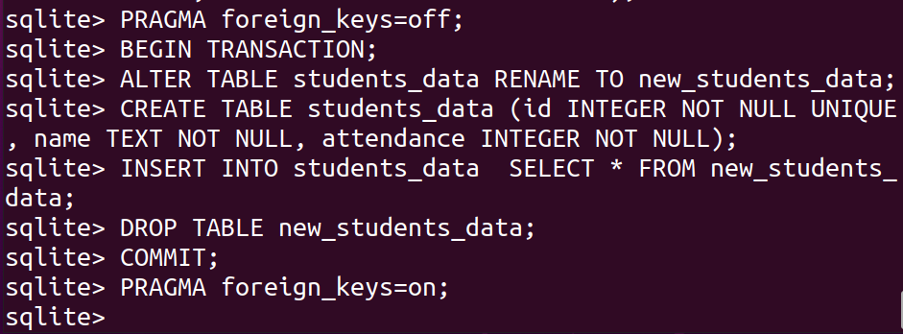
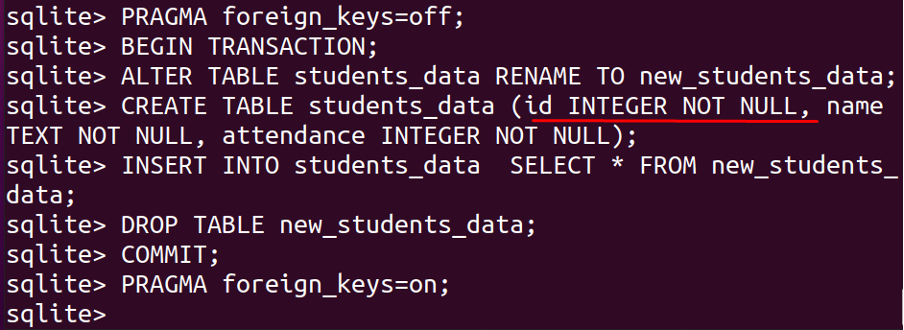
How to drop the UNIQUE constraint to the existing table
Like other databases, we cannot drop the constraint by using the DROP and ALTER commands, to delete the UNIQUE constraints we should follow the same procedure we opted for adding the constraint to an existing table and redefine the structure of the table.
Let consider the above example again, and remove the UNIQUE constraints from it:
BEGIN TRANSACTION;
ALTER TABLE students_data RENAME TO new_students_data;
CREATE TABLE students_data (id INTEGER NOT NULL, name TEXT NOT NULL, attendance INTEGER NOT NULL);
INSERT INTO students_data SELECT * FROM new_students_data;
DROP TABLE new_students_data;
COMMIT;
PRAGMA foreign_keys=ON;
Conclusion
The UNIQUE constraint is used in the databases to restrict the duplication of the values inserted in the fields of the table just like the PRIMARY key constraint, but there is a difference between both of them; a table can only have one PRIMARY key, whereas a table can have UNIQUE key columns more than one. In this article, we discussed what a UNIQUE constraint is and how it can be used in SQLite with the help of examples.