The utilities Linux offer often follow the UNIX philosophy of design. Any tool should be small, use plain text for I/O, and operate in a modular manner. Thanks to the legacy, we have some of the finest text processing functionalities with the help of tools like sed and awk.
In Linux, the awk tool comes pre-installed on all Linux distros. AWK itself is a programming language. The AWK tool is just an interpreter of the AWK programming language. In this guide, check out how to use AWK on Linux.
AWK usage
The AWK tool is most useful when texts are organized in a predictable format. It’s quite good at parsing and manipulating tabular data. It operates on a line-by-line basis, on the entire text file.
The default behavior of awk is to use whitespaces (spaces, tabs, etc.) for separating fields. Thankfully, many of the configuration files on Linux follow this pattern.
Basic syntax
This is how the command structure of awk looks like.
The portions of the command are quite self-explanatory. Awk can operate without the search or action portion. If nothing is specified, then the default action on the match will be just printing. Basically, awk will print all the matches found on the file.
If there’s no search pattern specified, then awk will perform the specified actions on every single line of the file.
If both portions are given, then awk will use the pattern to determine whether the current line reflects it. If matched, then awk performs the action specified.
Note that awk can also work on redirected texts. This can be achieved by piping the contents of the command to awk to act on. Learn more about the Linux pipe command.
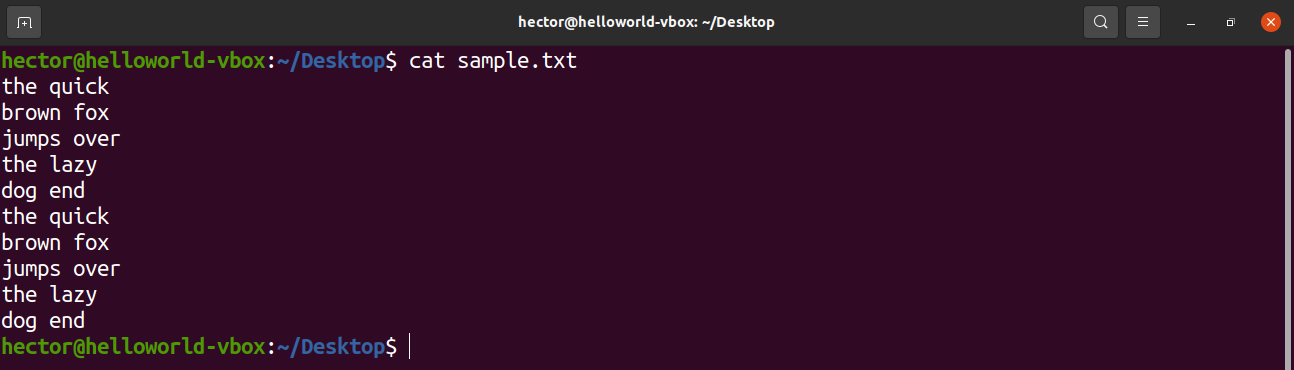
For demo purposes, here’s a sample text file. It contains 10 lines, 2 words per line.
Regular expression
One of the key features that make awk a powerful tool is the support of regular expression (regex, for short). A regular expression is a string that represents a certain pattern of characters.
Here’s a list of some of the most common regular expression syntaxes. These regex syntaxes aren’t just unique to awk. These are almost universal regex syntaxes, so mastering them will also help in other apps/programming that involves regular expression.
- Basic characters: All the alphanumeric characters underscore (_) etc.
- Character set: To make things easier, there are character groups in the regex. For example, uppercase (A-Z), lowercase (a-z), and numeric digits (0-9).
- Meta-characters: These are characters that explain various ways to expand the ordinary characters.
- Period (.): Any character match in the position is valid (except a newline).
- Asterisk (*): Zero or more existences of the immediate character preceding it is valid.
- Bracket ([]): The match is valid if, at the position, any of the characters from the bracket is matched. It can be combined with character sets.
- Caret (^): The match will have to be at the start of the line.
- Dollar ($): The match will have to be at the end of the line.
- Backslash (\): If any meta-character has to be used in the literal sense.
Printing the text
To print all the contents of a text file, use the print command. In the case of the search pattern, there’s no pattern defined. So, awk prints all the lines.
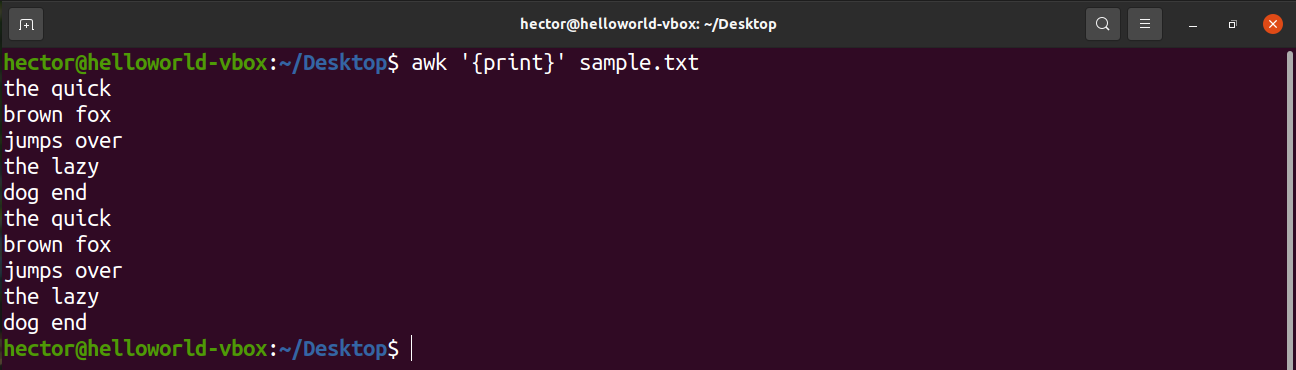
Here, “print” is an AWK command that prints the content of the input.
String search
AWK can perform a basic text search on the given text. In the pattern section, it has to be the text to find.
In the following command, awk will search for the text “quick” on all the lines of the file sample.txt.

Now, let’s use some regular expressions to further fine-tune the search. The following command will print all the lines that have “brown” at the beginning.

How about finding something at the end of a line? The following command will print all the lines that have “quick” at the end.

Wild card pattern
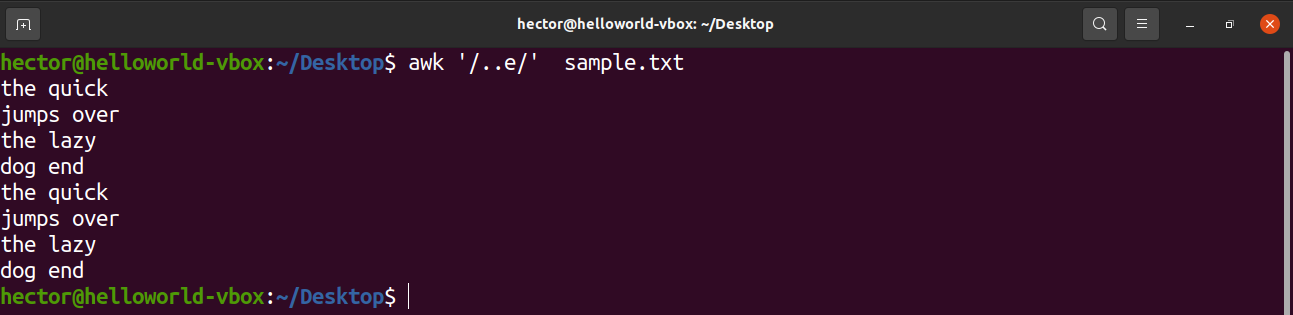
The next example is going to showcase the usage of the caret (.). Here, there can be any two characters before the character “e”.
Wild card pattern (using asterisk)
What if there can be any number of characters at the location? To match for any possible character at the position, use the asterisk (*). Here, AWK will match all the lines that have any amount of characters after “the”.

Bracket expression
The following example is going to showcase how to use the bracket expression. Bracket expression tells that at the location, the match will be valid if it matches the set of characters enclosed by the brackets. For example, the following command will match “The” and “Tee” as valid matches.

There are some predefined character sets in the regular expression. For example, the set of all uppercase letters is labeled as “A-Z”. In the following command, awk will match all the words that contain an uppercase letter.
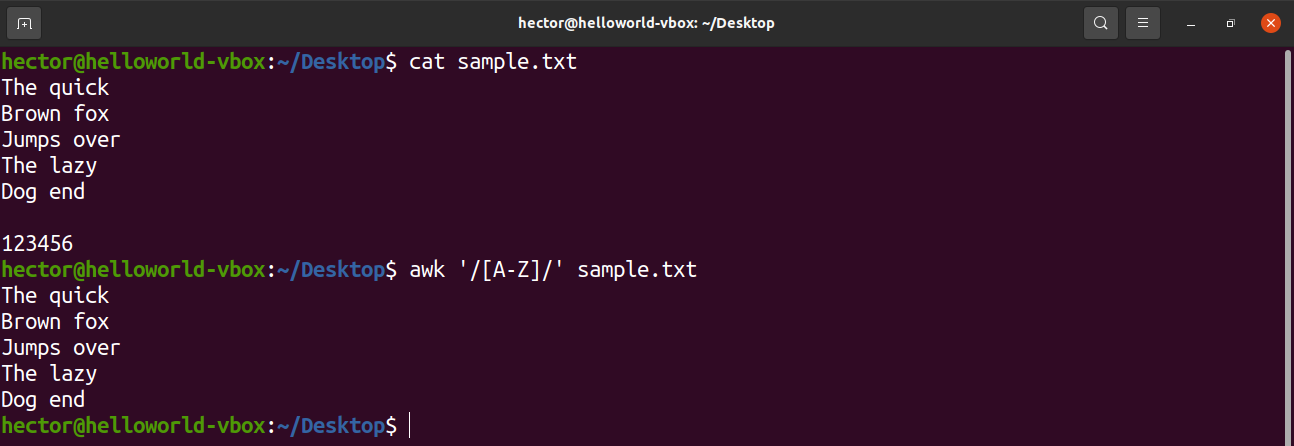
Have a look at the following usage of character sets with bracket expression.
- [0-9]: Indicates a single digit
- [a-z]: Indicates a single lowercase letter
- [A-Z]: Indicates a single uppercase letter
- [a-zA-z]: Indicates a single letter
- [a-zA-z 0-9]: Indicates a single character or digit.
Awk pre-defined variables
AWK comes with a bunch of pre-defined and automatic variables. These variables can make writing programs and scripts with AWK easier.
Here are some of the most common AWK variables that you’ll come across.
- FILENAME: The filename of the current input file.
- RS: The record separator. Because of the nature of AWK, it processes data one record at a time. Here, this variable specifies the delimiter used for splitting the data stream into records. By default, this value is the newline character.
- NR: The current input record number. If the RS value is set to default, then this value will indicate the current input line number.
- FS/OFS: The character(s) used as the field separator. Once read, AWK splits a record into different fields. The delimiter is defined by the value of FS. When printing, AWK rejoins all the fields. However, at this time, AWK uses the OFS separator instead of the FS separator. Generally, both FS and OFS are the same but not mandatory to be so.
- NF: The number of fields in the current record. If the default value “whitespace” is used, then it’ll match the number of words in the current record.
- ORS: The record separator for the output data. The default value is the newline character.
Let’s check them in action. The following command will use the NR variable to print line 2 to line 4 from sample.txt. AWK also supports logical operators like logical and (&&).

To assign a specific value to an AWK variable, use the following structure.
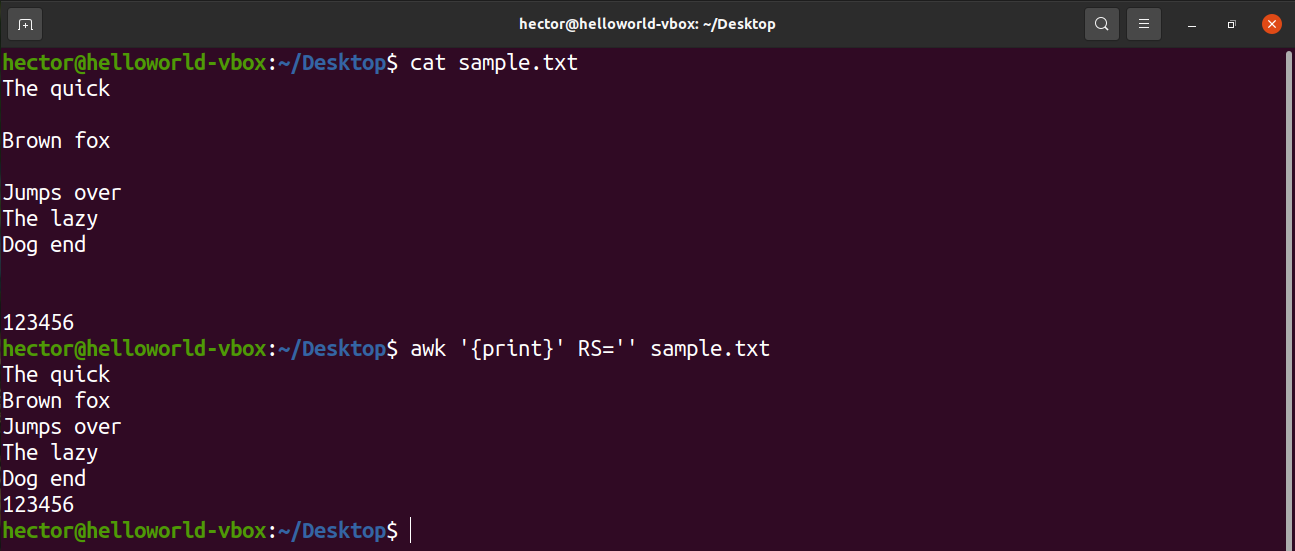
For example, to remove all the blank lines from the input file, change the value of RS to basically nothing. It’s a trick that uses an obscure POSIX rule. It specifies that if the value of RS is an empty string, then records are separated by a sequence that consists of a newline with one or more blank lines. In POSIX, a blank line with no content is completely empty. However, if the line contains whitespaces, then it’s not considered “blank”.
Additional resources
AWK is a powerful tool with tons of features. While this guide covers a lot of them, it’s still just the basics. Mastering AWK will take more than just this. This guide should be a nice introduction to the tool.
If you really want to master the tool, then here are some additional resources you should check out.
- Trim whitespace
- Using a conditional statement
- Print a range of columns
- Regex with AWK
- 20 AWK examples
Internet is quite a good place to learn something. There are plenty of awesome tutorials on AWK basics for very advanced users.
Final thought
Hopefully, this guide helped provide a good understanding of the AWK basics. While it may take a while, mastering AWK is extremely rewarding in terms of the power it bestows.
Happy computing!