MyScale is a cloud-based database that assists AI technology in building efficient models and getting data from the database. LangChain is used to create Large Language Models (LLM) as question-answering chatbots to extract data using natural language queries. The user can create their own dataset and design queries related to the data to retrieve information quickly in LangChain.
This post demonstrates the process of using self-query with MyScale in LangChain.
How to Use Self-Querying with MyScale in LangChain?
To use self-query with MyScale in LangChain, let’s look at this guide with simple steps to perform the task:
Step 1: Installing Modules
To start the process of using self-query with MyScale in LangChain, install the LangChain framework first and then move forward with the example:
Install the OpenAI framework to use the API key of the framework. After that, LLM is used to generate text in natural language:
To create a self-query with MyScale, simply install Lark with the “clickhouse-connect” library:
Install the tiktoken tokenizer to split the text into small chunks before embedding it using the OpenAI functions:
Step 2: Create MyScale Vector Store
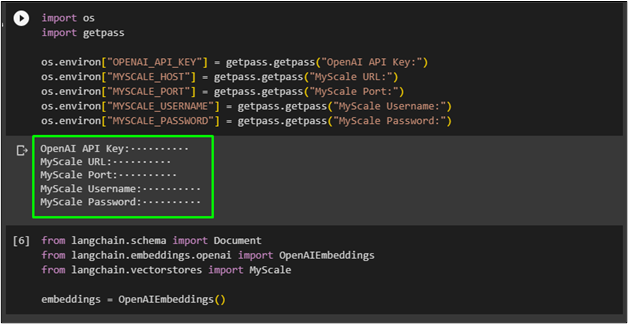
After installing all the necessary libraries for using self-query in MyScale, simply import all the credentials for building the LLM model and accessing MyScale resources. The credentials include the OpenAI key, host, port, username, and password for the MyScale account:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
os.environ["MYSCALE_HOST"] = getpass.getpass("MyScale URL:")
os.environ["MYSCALE_PORT"] = getpass.getpass("MyScale Port:")
os.environ["MYSCALE_USERNAME"] = getpass.getpass("MyScale Username:")
os.environ["MYSCALE_PASSWORD"] = getpass.getpass("MyScale Password:")
After successfully providing the credentials for the MyScale account and OpenAI API, simply import MyScale from the vector stores of LangChain. OpenAI library is used to call the OpenAIEmbeddings() function for embedding the data from the vector store:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import MyScale
embeddings = OpenAIEmbeddings()
Step 3: Insert the Data into MyScale
Insert data into the MyScale database by simply creating documents for movies with their storyline and metadata like the year, rating, director, genre, etc.
Document(
page_content="Earth is a million years old",
metadata={"year": 2003, "rating": 8.7, "genre": "science fiction"},
),
Document(
page_content="Mark Boucher gets lost in space",
metadata={"year": 2009, "director": "Ab De-Villiers", "rating": 9.2},
),
Document(
page_content="A doctor gets lost in a series of dreams",
metadata={"year": 2006, "director": "Satoshi Kon", "rating": 7.6},
),
Document(
page_content="A bunch of highly talented ladies/women are saving the world",
metadata={"year": 2019, "director": "Sara Taylor", "rating": 8.3},
),
Document(
page_content="Toys cars are fighting for their existing at racing track",
metadata={"year": 2000, "genre": "animated"},
),
Document(
page_content="prisoners plan to escape but caught",
metadata={
"year": 2009,
"director": "Ben Ducket",
"genre": "thriller",
"rating": 9.9,
},
),
]
vectorstore = MyScale.from_documents(
docs,
embeddings,
)

Step 4: Create Self-Querying Retriever
After inserting data in the MyScale vector store, simply create a self-query to fetch data from the database using the following code. The self-query retriever will generate the data about the film like the genre, date, director, and rating of the movie using the LLM in LangChain:
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie",
type="string or list[string]",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="director",
description="The name of the movie director",
type="string",
),
AttributeInfo(
name="rating", description="A 1-10 rating for the movie", type="float"
),
]
#configure the retriever using the LLM in OpenAI application to get data from database
document_content_description = "Get basic info about the movie"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm, vectorstore, document_content_description, metadata_field_info, verbose=True
)
Step 5: Test Retriever
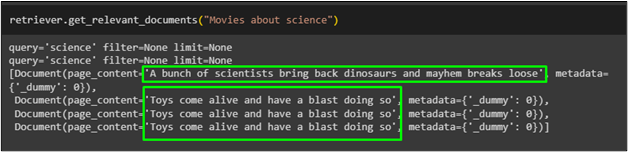
Once the retriever is created, simply run the retriever with queries written in the natural language:
The movies retrieved for the query mentioned in the above code are displayed in the following screenshot:
Step 6: Specifying Filter K With Retriever
The user can also configure the retriever to fetch the exact number of documents by enabling the limit:
llm,
vectorstore,
Document_content_description,
Metadata_field_info,
enable_limit=True,
verbose=True,
)
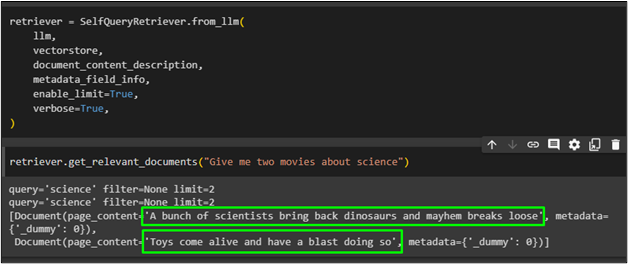
Run the retriever with a query stating the exact number of documents to fetch from the database:
The model has retrieved exactly two movies from the database as asked in the above prompt:
That’s all about using the self-query with MyScale in LangChain and the user can use multiple prompts in retrievers provided in this guide.
Conclusion
To use self-query with MyScale in LangChain, simply install frameworks like LangChain, OpenAI, Lark, tiktoken, etc. Accessing the MyScale database requires the connection credentials which are necessary to get on with it. After that, insert data into the MyScale database and create a self-query retriever to fetch data using prompts. This post demonstrated the process of using self-querying retrievers with MyScale in LangChain.