Chromadb is the vector store in LangChain or a database that allows the user to store vector embeddings of data for making an LLM application. Large Language Models or LLMs are used to build applications to handle, or process prompts in natural language and generate text accordingly. LangChain uses vector stores to train models on natural languages which then allows it to generate text for the prompt used in the retriever.
This guide will explain the process of using Chroma self-querying in LangChain.
How to Use Chroma Self-Querying in LangChain?
To use self-query with the chroma database in LangChain, simply follow this simple and thorough guide:
Installing Prerequisites
Install the LangChain at the start of the process to continue using its framework or libraries to create retrievers:
Install OpenAI to use its functions by using its API key to access its resources:
Install the Lark module to create self-query using the chroma database in LangChain:
Install chromadb to use the database as the vector stores in LangChain:
The last installation in the process is the tiktoken tokenizer used to create small chunks of the data:
Use the OpenAI library to provide the API key of the OpenAI to access its resources in building natural language models:
import getpassos.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
Create Chroma Vector Store
After providing all the prerequisite steps, import the libraries like OpenAIEmbeddings and Chroma from these modules:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chromaembeddings = OpenAIEmbeddings()

Insert data in the Chroma vector database using multiple documents related to movies with its description and metadata like the year, rating, genre, etc.
Document(
page_content="Earth is a million years old",
metadata={"year": 2003, "rating": 8.7, "genre": "science fiction"},
),
Document(
page_content="Leo DiCaprio gets lost in space",
metadata={"year": 2009, "director": "Christopher Nolan", "rating": 9.2},
),
Document(
page_content="A doctor gets lost in a series of dreams",
metadata={"year": 2006, "director": "Satoshi Kon", "rating": 7.6},
),
Document(
page_content="A bunch of highly talented women are saving the world",
metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},
),
Document(
page_content="Toys come alive and have a blast doing so",
metadata={"year": 1995, "genre": "animated"},
),
Document(
page_content="prisoners plan to escape but caught",
metadata={
"year": 1979,
"rating": 9.9,
"director": "Andrei Tarkovsky",
"genre": "thriller",
"rating": 9.9,
},
),
]
vectorstore = Chroma.from_documents(docs, embeddings)
Creating Self-Query Retriever
After creating the chroma vector store and inserting data in it, simply create the retriever for self-querying using LLM to generate text after understanding the natural language prompts:
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfometadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie",
type="string or list[string]",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="director",
description="The name of the movie director",
type="string",
),
AttributeInfo(
name="rating", description="A 1-10 rating for the movie", type="float"
),
]
document_content_description = "Brief summary of a movie"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm, vectorstore, document_content_description, metadata_field_info, verbose=True
)
Retriever Specifying Filter
Now, simply test the retriever using prompts with a filter on the genre of the movie from the database:
The movie has been displayed in the following screenshot after applying the filter:

Specifying Multiple Filters
The user can also apply the filter on multiple attributes as the following code uses a command with the filter on genre and rating:
The following screenshot displays the movie with the genre science and with a rating of 8.7 justifying both the filter applied in the prompt:

Specifying Query and Filter
The prompts can also contain the query by specifying a particular data from the database and a filter on a single field:
The movie retrieved after applying the prompt is directed by the said director which is about women:

Specifying Query and Multiple Filters
The prompt can comprise multiple filters with a query written in natural language:
"What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"
)
The movie extracted from the prompt provided in the above code is displayed in the following screenshot:

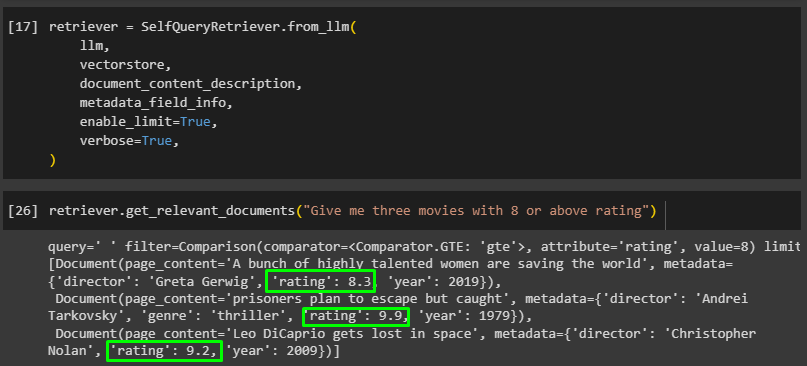
Limit With Filter K
The prompt can also use the filters on how much data needed to be extracted from the database by enabling the limit of the retriever:
llm,
vectorstore,
document_content_description,
metadata_field_info,
enable_limit=True,
verbose=True,
)
Simply type the prompt in the retriever by limiting the model to extract the exact number of documents from the database:
The following screenshot displays three movies with ratings of more than 8 as specified by the above code:
That is all about using the chromadb self-querying in LangChain.
Conclusion
To use the self-querying chroma vector database in LangChain, install all the necessary modules like LangChain, OpenAI, Lark, Chroma, etc. After that, create a Chroma vector store and insert data in it after providing the OpenAI API key from the OpenAI credentials. Create a self-query retriever to extract data from the chroma database using the prompts in natural language. This guide has explained the process of using the chroma database self-query in LangChain.