Data is coming in huge numbers and becomes difficult to manage or understand the data if it is in the unstructured form. However, the structured form of data can be understood easily in comparison to the unstructured form which is mostly available in the textual form. LangChain is a framework to make it easy to understand natural language by building applications-powered language models.
This guide will explain the process of splitting text in LangChain.
How to Split Text in Langchain?
Splitting text can make it easy to understand by dividing the large text into smaller chunks so the user can gain meaningful information through that. To split text using the LangChain framework, simply follow this guide with simpler examples:
Example 1: Text Splitters
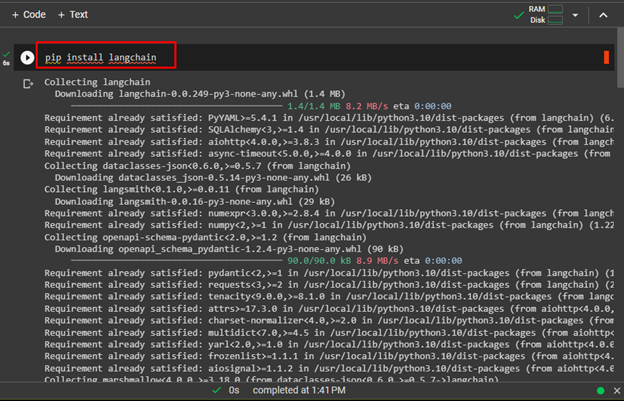
Before learning the process of splitting text in the langchain model, simply learn how these model work and start by installing the LangChain using the following command:
The following screenshot displays the successful installation of the LangChain module:
Use the following command to import the “text_splitter” from the “langchain” library:
RecursiveCharacterTextSplitter,
Language,
)
After that, simply use the following command to get the list of languages that support the process of splitting text using code:
The following screenshot displays the list of all the languages:
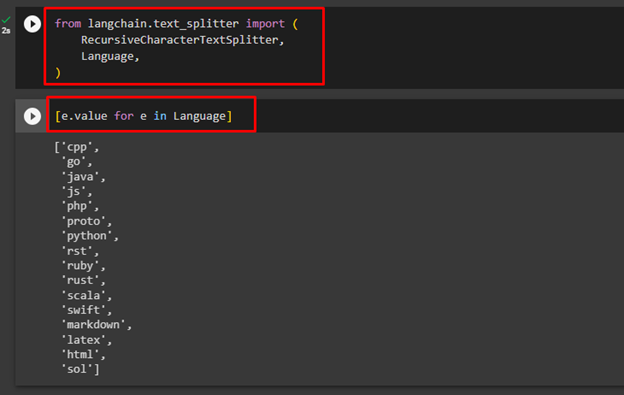
Use the following code to learn all the splitters/separators used to split the text in the provided language:
Splitters are the keyword located in the textual document which can be used to split documents.
The above code is used to get the separators of the Python language and the following screenshot displays the list of all the separators in the language:

Example 2: Splitting Code Using LangChain
Start the process of splitting text by splitting code written in the Python language using the following code:
def hello():
print("Hello, LinuxHint")
# Call the function
hello()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs
The above code uses a basic Python code containing a hello() function and calls it later to print the “Hello, LinuxHint” message. After that, the “python_splitter” is used to split the above code into smaller chunks:
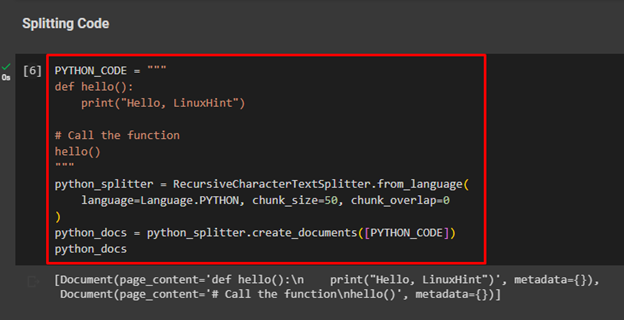
The above screenshot displays that the code has split the code into two documents.
Example 3: Split Text by Character
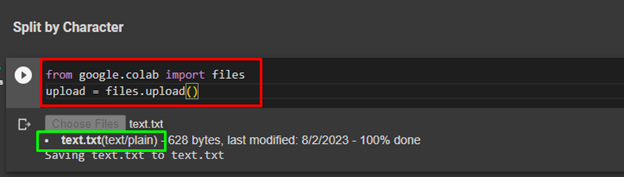
To split the text document by character, simply upload the document from a local computer on the Google Collaboratory IDE. Google Collaboratory is the cloud-based integrated Development Environment for the Python language:
upload = files.upload()
After executing the above code, simply click on the “Choose Files” button and upload the document from the local system:
After that, simply open the text on the cloud IDE and allows the environment to read the text:
Text = f.read()
Import the “CharacterTextSplitter” library from the “langchain” library using the “text_splitter” module and set the configurations for the splitter. The following code uses space as the separator and then set its chunk size with its overlap chunk:
text_splitter = CharacterTextSplitter(
separator = "",
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
The following code is used to print the chunks of the text using the index numbers of the texts:
print(texts[0])
print(texts[1])
print(texts[2])
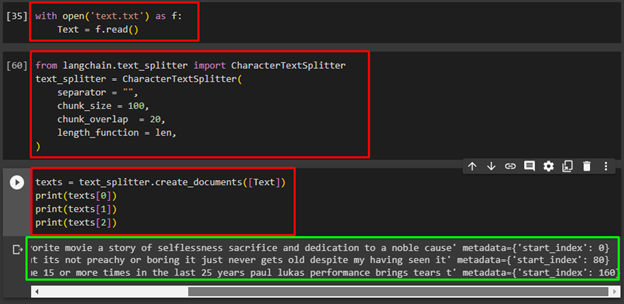
The above screenshot displays the three chunks from the texts as the code only prints the first 3 indexes.
Example 4: Metadata of the Splitting Text
The following screenshot also displays the metadata of the chunks separated from the text and prints the text with the index number 3:
documents = text_splitter.create_documents([Text, Text], metadatas=metadatas)
print(documents[3])
The following screenshot displays the metadata of the data at the end of the output:

After that, simply print the index number 3 without any metadata attached to it using this code:
The following screenshot displays the data without its metadata:

Note: to learn the process of tokenization in Python, simply refer to this guide.
That’s all about splitting the text in the LangChain module using separators of Python language.
Conclusion
To split the text in the LangChain module, simply install the module in the development environment as this guide uses Google Collaboratory. After that, understand the language that supports the splitting process and separator for each language. LangChain supports the splitting of code in Python language as well as text documents from the local system or written in the code. This guide has explained both the process of splitting text in LangChain using Python language.