Unstructured data is quite difficult to understand with the diversity of languages around the globe. Splitting text into smaller chunks is one of the solutions that can help the user to understand the text and tokens in Langchain. By considering its importance, the “tiktoken” module is used in the LangChain framework to convert the text into the token and then split them into smaller chunks.
This guide will explain the process of splitting text in LangChain using the tokens.
How to Split Text by Tokens Using the “tiktoken” Tokenizer in LangChain?
To split text by tokens in LangChain, install the LangChain module via the following code:
The following screenshot displays that the LangChain has been installed successfully:
After that, install the “tiktoken” module to use the token to split the text in LangChain:
The following screenshot displays the successful installation of the tiktoken:
After installing all the modules, simply upload the document from the local system:
upload = files.upload()
Running the above code allows the user to upload the text file from the system:

Open the uploaded text file in the Text frame and import the CharacterTextSplitter library from text_splitter:
Text = f.read()
from langchain.text_splitter import CharacterTextSplitter
After that, configure the size of the chunks to divide the text into smaller parts and set the overlap of the chunks:
chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(Text)
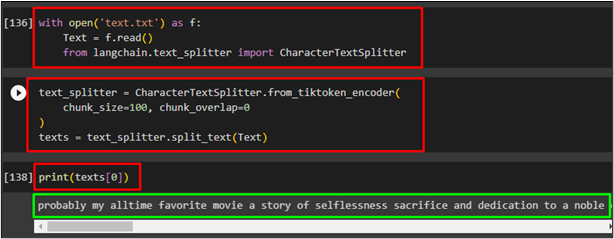
Print the chunk of the text at the index number 0 which refers to the first chunk of the text:
The following screenshot displays the successful execution of all the above code segments and prints the first chunk of the text:
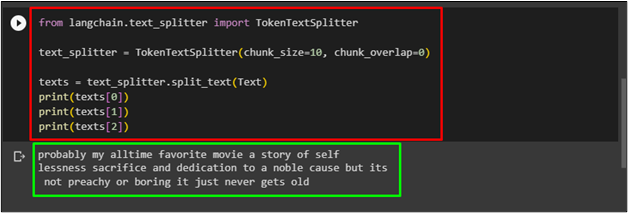
The user can also load the tiktoken splitter using the following code and configure the chunks of the text to split in:
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
texts = text_splitter.split_text(Text)
print(texts[0])
print(texts[1])
print(texts[2])
The following screenshot displays the three chunks of the split text using the above code:
How to Split Text by Tokens Using Spacy Library in LangChain?
Use the following code to install the spacy library to split the text into smaller chunks:
After installing the spacy library, simply use the following code to import the SpacyTextSplitter from the LangChain module:
text_splitter = SpacyTextSplitter(chunk_size=1000)
Use the Text frame from the first step to split the document and print its first chunk using the following code:
print(texts[0])
The following screenshot displays the first chunk divided by the spacy library:

Note: For further instruction on using the tokenizers for splitting text by tokens in LangChain, simply visit the official website.
That is all about splitting text in LangChain using the Tokens
Conclusion
Splitting the text into smaller chunks making it easier to understand the document containing raw text can be done using the token in LangChain. The tiktoken is the best tokenizer that will convert text into tokens and then split them into smaller chunks according to configurations. Another tokenizer to split the text into tokens uses the spacy library called SpacyTextSplitter. This guide has explained the process of splitting text into smaller chinks using tokens in the LangChain framework.