In this article, I am going to show you how to get the current URL of the browser with Selenium. So, let’s get started.
Prerequisites:
To try out the commands and examples of this article, you must have,
1) A Linux distribution (preferably Ubuntu) installed on your computer.
2) Python 3 installed on your computer.
3) PIP 3 installed on your computer.
4) Python virtualenv package installed on your computer.
5) Mozilla Firefox or Google Chrome web browsers installed on your computer.
6) Must know how to install the Firefox Gecko Driver or Chrome Web Driver.
For fulfilling the requirements 4, 5, and 6, please read my article Introduction to Selenium with Python 3 at Linuxhint.com.
You can find many articles on the other topics on LinuxHint.com. Be sure to check them out if you need any assistance.
Setting Up a Project Directory:
To keep everything organized, create a new project directory selenium-url/ as follows:
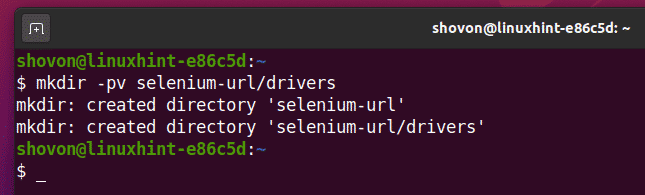
Navigate to the selenium-url/ project directory as follows:

Create a Python virtual environment in the project directory as follows:
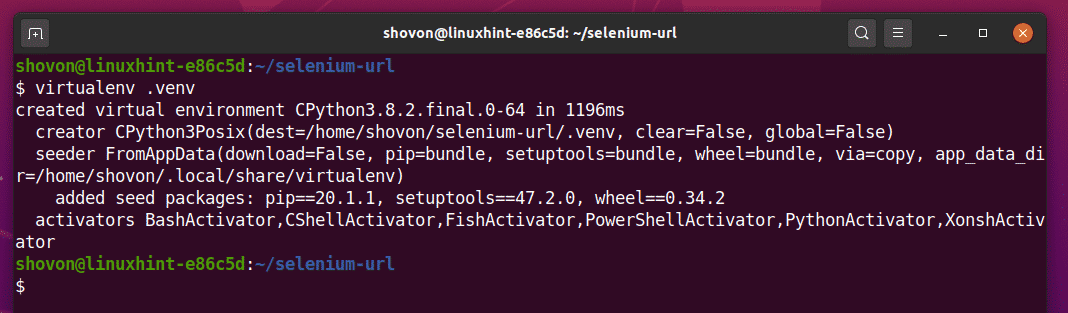
Activate the virtual environment as follows:

Install Selenium Python library in your virtual environment using PIP3 as follows:

Download and install all the required web drivers in the drivers/ directory of the project. I have explained the process of downloading and installing web drivers in my article Introduction to Selenium with Python 3. If you need any assistance, search on LinuxHint.com for that article.
I will be using the Google Chrome web browser for the demonstration in this article. So, I will be using the chromedriver binary with Selenium. You should use the geckodriver binary if you want to use the Firefox web browser.
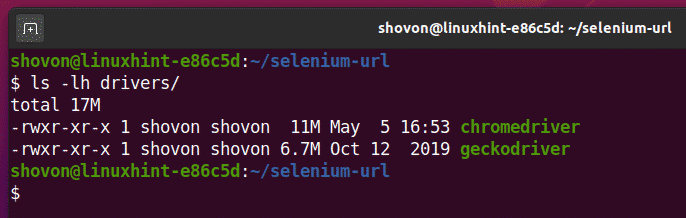
Getting Current URL with Selenium:
Create a Python script ex01.py in your project directory and type in the following lines of codes in it.
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
options.headless = True
browser = webdriver.Chrome(executable_path="./drivers/chromedriver", options=options)
browser.get("https://duckduckgo.com/")
print(browser.current_url)
browser.close()
Once you’re done, save the ex01.py Python script.
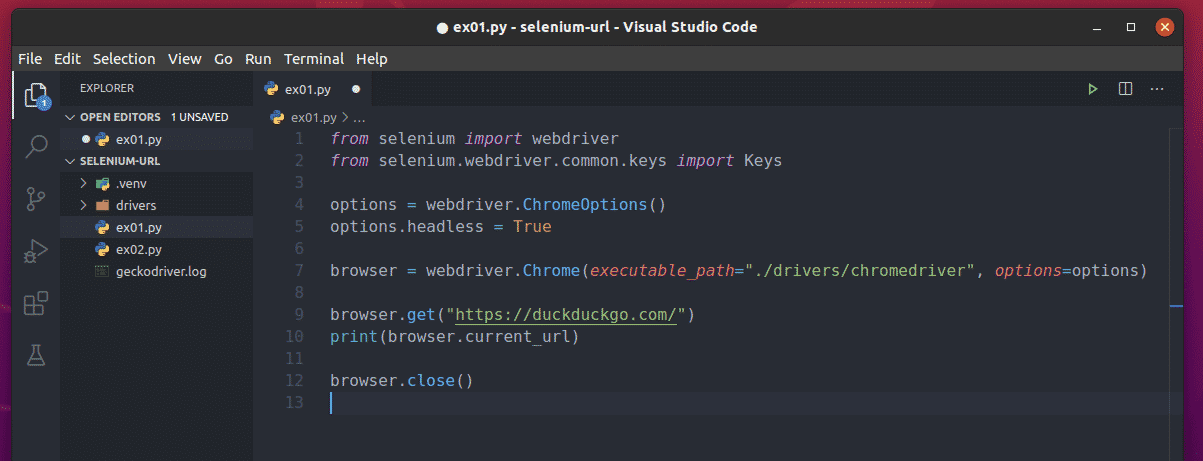
Here, line 1 and line 2 import all the required components from the Python selenium library.

Line 4 creates a Chrome Options object, and line 5 enables headless mode for the Chrome web browser.

Line 7 creates a Chrome browser object using the chromedriver binary from the drivers/ directory of the project.
![]()
Line 9 tells the browser to load the duckduckgo.com website.
![]()
Line 10 prints the current URL of the browser. Here, browser.current_url property is used to access the current URL of the browser.
![]()
Line 12 closes the browser.
![]()
Run the Python script ex01.py as follows:

As you can see, the current URL (https://duckduckgo.com) is printed on the console.

In the earlier example, I have visited the website duckduckgo.com and printed the current URL on the console. This returns the URL of the page we are visiting. Not very fancy as we already know the page URL. Now, let’s search for something on DuckDuckGo and try to print the URL of the search result page on the console.
Create a Python script ex02.py in your project directory and type in the following lines of codes in it.
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
options.headless = True
browser = webdriver.Chrome(executable_path="./drivers/chromedriver", options=options)
browser.get("https://duckduckgo.com/")
print(browser.current_url)
searchInput = browser.find_element_by_id('search_form_input_homepage')
searchInput.send_keys('selenium hq' + Keys.ENTER)
print(browser.current_url)
browser.close()
Once you’re done, save the ex02.py Python script.

Here, lines 1-10 are the same as in ex01.py. So, I am not explaining them again.

Line 12 finds the search textbox and stores it in the searchInput variable.
Line 13 sends the search query selenium hq in the searchInput text box and presses the <Enter> key using Keys.ENTER.
![]()
Once the search page loads, browser.current_url is used to access the updated current URL.
Line 15 prints the updated current URL on the console.
![]()
Line 17 closes the browser.
![]()
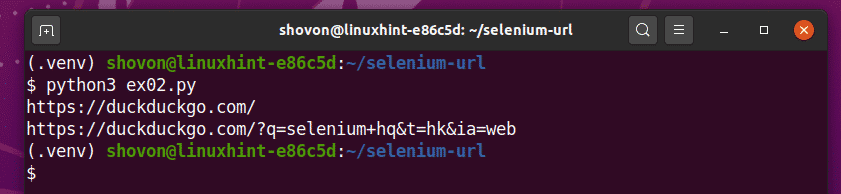
Run the ex02.py Python script as follows:

As you can see, the Python script ex02.py prints 2 URLs.
The first one is the homepage URL of the DuckDuckGo search engine.
The second one is the updated current URL after performing a search on the DuckDuckGo search engine using the query selenium hq.
Conclusion:
In this article, I have shown you how to get the current URL of the web browser using Selenium Python library. Now, you should be able to make your Selenium projects more interesting.