In simple arithmetic functions, there are different means and formulas to find the median in any provided data either in plain text or in the tabular form. Whereas in the case of database systems, we use some other built-in functions combined to get the value of the median. This article will elaborate on some of the most efficient techniques and also a manual function created by us to fetch the median from the data in Postgresql.
Use of percentile_count() and percentile_disc()
These both are the ways of getting median in a slightly different way. Because the difference in their resultant values is based on their methodologies. Percentile refers to portray the data value with having a percentage of per hundred. But for the median, we use (0.5) value. The main difference between both of them is that percentile_count() interpolates the value and its working is based on the continuous distribution of values, whereas percentile_disc() returns the value from the given data and relies on calculating the percentile on the discrete distribution.
The syntax for both these percentiles is:
SELECT percentile_disc(0.5) within group (order by x) from values (a),(b),(c),(d)) v (x);
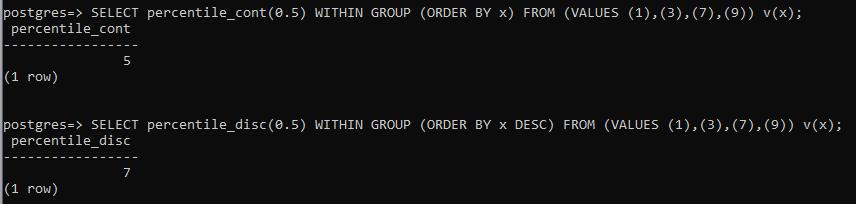
For the given values, percentile_disc will return the only values that are present in the data. Percentile_count calculates the median for the values. For example between the even numbers. In the above example, percentile_count will give “5” the number between the 3 and 7 values. And percentile_disc shows 7 from descending. As the value for this function is always from the available data. So it provides the closest value from the median after calculations.
As the data in the postgresql is present in the relations (table), the percentile is applied on the column of a numeric value (pay). We created a table named professor. The following query will help us to illustrate the table attributes first and then apply the percentile_disc() on it.
The first half of the query will display the contents of the table. whereas the second part will select the percentile value. An order by clause is applied here. This clause will arrange the items of the relevant column in ascending order, and then apply the function on it. The column (pay) is in use for this query to be executed.
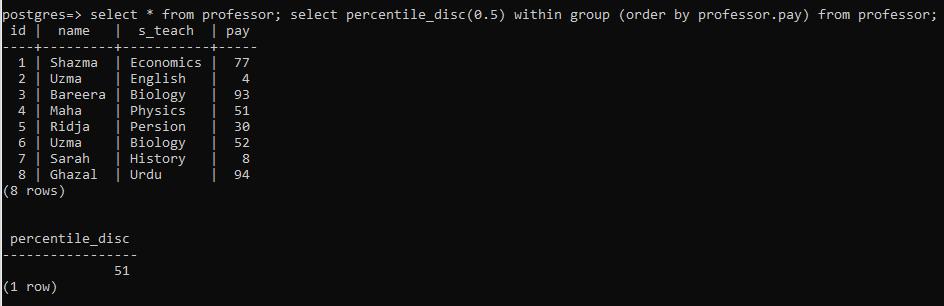
After execution, the result is 51, a distinct value that is obtained by the percentile function. To make it more clear, a simple “ntile” by 100 is used to arrange each element of the column in ascending order.
The above-mentioned command conveys the “pay” column from the table. It has made it easier to understand how percentile_disc will operate. As the total numbers in the “pay” column are 8 rows that are even. So it is hard to get the accurate mid-point of the data. Disc() will go for the closest value. That is “51” according to the ascending order.
In the case of percentile_count, the rest of the command is the same, but the function is changed from disc to CONT. As the name indicates the working of percentile_cont, the value is in the form of continuity, which means no end so far. Hence the result will be always in decimal form. This will bestow the mid of two adjacent numbers. In other words, this function fetches the two numbers present at the center of the column, in the case of even numbers.

Between 51 and 52 its “51.5” is the accurate continuous value of the median in the column “pay”.
You can also change the percentile value in any function. For instance, we use 0.25, 0.5, and 0.75 as the parameter in percentile_disc().
Percentile_disc(0.5)
Percentile_dic(0.75)

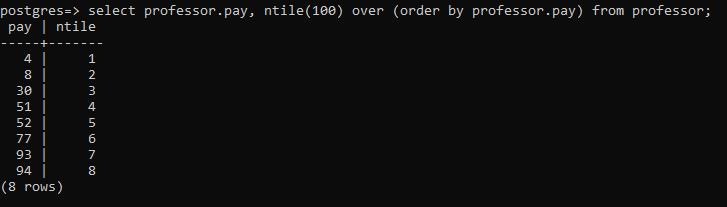
All the values are displayed collectively in a single row using this syntax in the function. Consider the snap we have attached, that shows the ntile of the column, all the values are sorted in ascending order. If 0.5 leads to the value “51”, then for 0.25, it is 8 and for “0.75” it’s 77. As it is the number present at id 4, so for 0.25, it is calculated according to the 4th id respectively. And similar is the case with 0.75.
Use of Function for Median
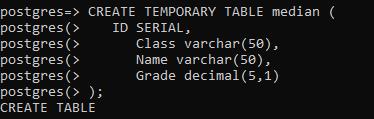
To enforce the function for the calculation of the median of the table, we need to have a new sample table. After creation, the values will be added to make it in the functional state. The temporary table is used because we don’t need this data for a longer time to exist in the database.
![]()
After the insertion of value, we will take a glimpse of the data that is inserted. For this purpose, use the SELECT statement.

In this function, the median for each class will be calculated separately. This partitioning is according to the class column. The data is sorted in both ASC and DESC orders. A new function is initialized here ROW NUMBER(). This will fetch the row number and then apply operations according to it. Let’s have a look at the code. Then we will break it down to see what is happening here to get the median.
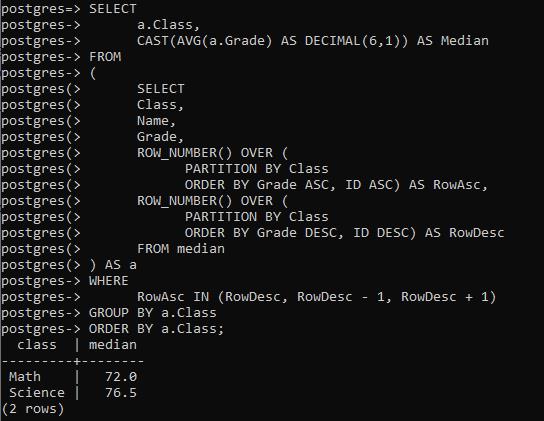
SELECT command is used that introduces the subquery. This subquery uses that ROW NUMBER() that will arrange the rows in ascending and descending order. For each class, orders are used for row numbers.
Whenever you are in search of the median in the list of having the values in even numbers, the answer always lies in taking the average of the two middle numbers as the PERCENTILE_CONT do. This is happening in this command to get the median.
The resultant is sent back from the subquery to the main query. And then an average is calculated. For the math, we get 72.0, the expected mid in the case of an odd list of values. Whereas for science, it is 76.5. It has an even number in science subjects, so we get mid of 72 and 81.
Conclusion
POSTGRESQL MEDIAN FUNCTION makes finding the mid-point in plain or tabular data easier than calculating it manually. Although it is a user-created function, it does use some built-in functions to fetch the relevant record. PERCENTILE_CONT and PERCENTILE_DISC are considered to be the core of the topic under discussion. As their silent support in providing median concept in the function are remarkable. However, all of these functions are enough for finding the median.