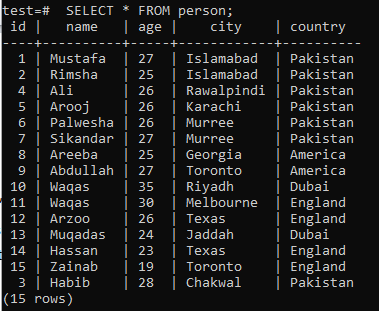
To understand the concept of full-text search, you have to recollect pattern search knowledge via the LIKE keyword. So, let’s assume a table ‘person’ in the database ‘test’ with the following records in it.
Let’s suppose you want to fetch the records of this table, where the column’ name’ has a character’ i’ in any of its values. Try the below SELECT query while using the LIKE clause in the command-shell. From the output below, you can see that we have only 5 records for this particular character’ i’ in the column ‘name’.

Use of Tvsector:
Sometimes it is of no use to use the LIKE Keyword to do a quick pattern search, although the word is there. Maybe you’d be considering using standard expressions, and although this is a feasible alternative, regular expressions are both strong and sluggish. Having a procedural vector for entire words in a text, a vernacular description of those words, is a much more efficient way to address this issue. The concept of complete text search and the data type tsvector was created to respond to it. There are two methods in PostgreSQL that do just what we want:
- To_tvsector: Used to make a list of tokens (ts means for “text search”).
- To_tsquery: Used to search the vector for incidences of specific terms or phrases.
Example 01:
Let’s start with a simple illustration of creating a vector. Suppose you want to make a vector for the string: “Some people have curly brown hair through proper brushing.”. So you have to write a to_tvsector() function along with this sentence in the brackets of a SELECT query as appended below. From the output below, you can see it would yield a vector of references (file positions) for each token, and also where terms with little context, like articles (the) and conjunctions (and, or), are deliberately ignored.

Example 02:
Assume you have two documents with some data in both of them. To store this data, now we will be using a real example of generating tokens. Assume you have created a table ‘Data’ in your database ‘test’ with some columns in it using the below CREATE TABLE query. Don’t forget to create a TVSECTOR type column named ‘token’ in it. From the output below, you can have a look at the table that has been created.
![]()
Now, it turns for us to add the overall data of both the documents in this table. So try the below INSERT command in your command-line shell to do so. Finally, the records from both the documents have been successfully added into the table ‘Data’.

Now you have to colonize the token column of both the documents with their specific vector. Ultimately, a simple UPDATE query will fill the tokens column by their corresponding vector for each file. So, you have to execute the stated below query in the command-shell to do so. The output is showing that the update has been finally made.
![]()
Now that we have it all in place let’s return to our illustration of “can one” with a scan. To to_tsquery with AND operator, as previously said, makes no difference between the files’ locations in the files as shown from the output stated below.

Example 04:
To find words that are “next to” one another, we will try the very same query with the ‘<->’ operator. The change is displayed in the output below.

Here is an example of no immediate word next to another.

Example 05:
We will find the words that aren’t immediately next to one another by using a number in the distance operator to reference distance. The proximity between ‘bring’ and ‘life is 4 words apart from the displayed image.

To check proximity between the words for almost 5 words is appended below.

Conclusion:
Finally, you have done all the simple and complicated examples of Full-text search using the To_tvsector and to_tsquery operators and functions.