PostgreSQL indexes are handy to speed up the SELECT and WHERE queries when working with a large database. However, the indexes will slow the input queries such as INSERT and UPDATE, especially when you have a large database with frequent update operations. So, how do you create indexes on PostgreSQL?
Creating PostgreSQL Indexes
When you have a large database and must retrieve the data that matches a given condition, the query takes longer since every entry has to be checked. However, indexing the table columns where you execute the query speeds up the process.
Here’s the basic syntax of creating an index on PostgreSQL:
In the previous syntax, the index method is the method that you wish to use to create the index. By default, PostgreSQL uses the btree indexing method. However, you can specify other options such as gist, gin, hash, brin, etc.
For the column name, you can create a single or multi-column index. Let’s have examples.
Example 1: Creating a Single-Column Index
Suppose you want to select an entry that matches a given condition. Without indexing, the query searches all entries in a table. However, we can simplify the process by indexing the table and the specific column where we execute the WHERE clause.
Here’s the table that we use for the examples:
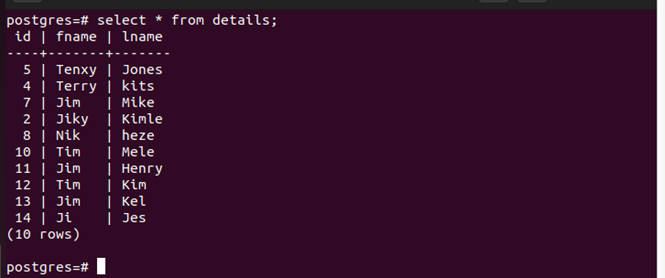
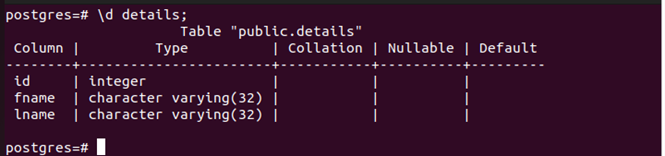
Run the \d table-name to list any available indexes in the table.
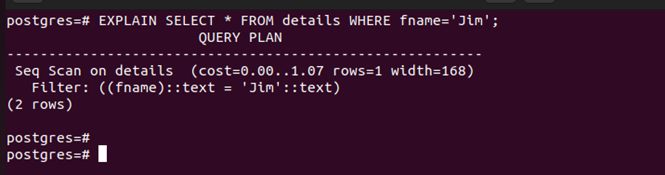
Our select query is as follows:
We can use the EXPLAIN option to see how the query plan flows.
Here’s the output of the query plan:
Now, let’s create an index for the column.

List the available indexes to confirm that the new index is created.
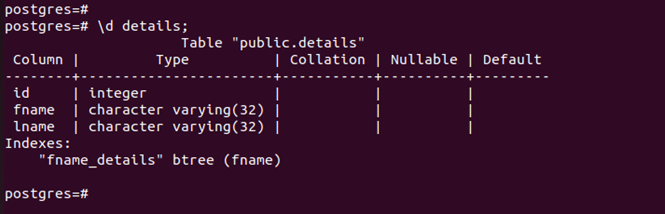
With the created index, the retrieval speed will be faster when you have a larger database. Moreover, the index that we created is used for the scan as seen in the following:
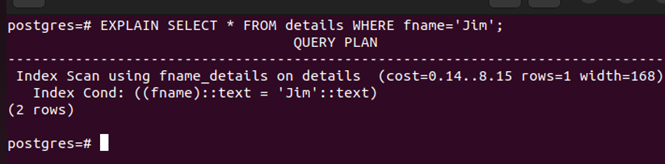
We successfully created a single-column index.
Example 2: Creating Multi-column Indexes
Suppose you frequently perform a SELECT_WHERE clause on two columns. Indexing them is handy in enhancing the retrieval process.
For instance, executing the following command takes longer with no indexing:
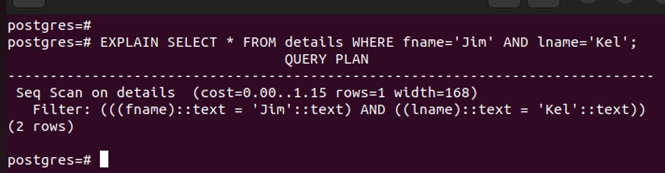
Still, on our table, let’s create a multi-column index for the lname and fname columns.
The index command is as follows:

We confirm that our index is created successfully.
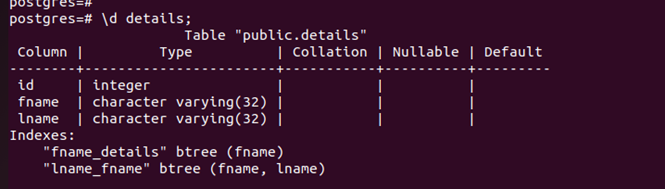
If we EXPLAIN the earlier query, we can see that it now uses the created index.

That’s how you create the multi-column indexes. You only need to specify the target columns that are separated by commas.
Example 3: Creating the UNIQUE Indexes
You can add the UNIQUE option when you don’t want any duplicate values to be inserted on the columns that you want to index. The index checks for any duplicates in the table and raises an error whenever you try to insert duplicate values.
Let’s create a unique index that we created in the first example.

It raises an error because we have duplicate values in the table. Remove the duplicates and create the unique index again. Here, we changed the column.
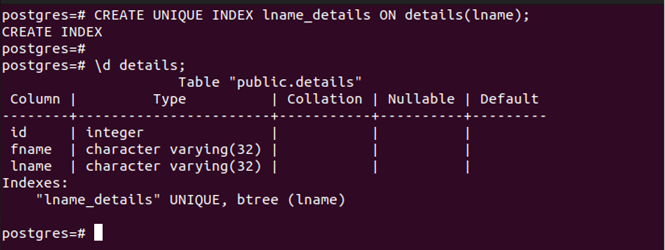
Now, try adding a duplicate value and watch the error that it raises.

That’s the impact of creating a unique index.
Example 4: Creating an Index Concurrently
A lock is created on the particular table whenever you create an index. This lock hinders any write operations on that table until the index build is completed. To avoid this, consider creating the indexes concurrently.
Use the following syntax:
Creating a concurrent index is desirable when you have a large database with different users working on the same database. By avoiding the lock, you guarantee that the table can be edited by various users even when an index build is happening.
Example 5: Dropping an Index
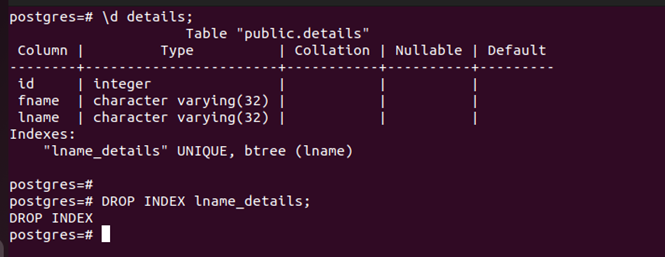
After creating a table, you may want to delete it whenever you feel that you no longer need it. In that case, use the following syntax:
Here’s an example of deleting the indexes that we created earlier:
Conclusion
Creating indexes is one way of creating pointers in a PostgreSQL database. You can create a single or multi-column indexes. Moreover, you can create unique indexes to eliminate the duplicates and concurrent indexes to avoid locking. This post presented different examples of creating indexes. With that, you can try the same on your end.