Postgres relies on different locks to guarantee that all transactions can run as expected. The transaction that first obtains a lock must be completed. Unless a ROLLBACK or COMMIT is made, another transaction can’t go forward due to the lock. Our focus today is understanding how to create indexes concurrently to avoid locking.
How Does Locking Work
Before diving into creating indexes concurrently, it’s worth understanding how Postgres implements locks and seeing how they affect the transaction unless you know how to deal with them.
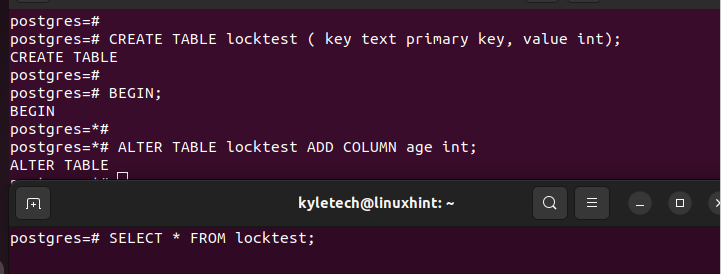
For this case, we create a table and initiate a transaction to alter the table to add a new column. From the following image, we can see that once the ALTER transaction gets hold of the lock as the first transaction, the select command fails to respond in the second psql shell.
This case occurs because the first transaction issues a lock. You will run into a similar case when you fail to index concurrently, as we will see in the later section.
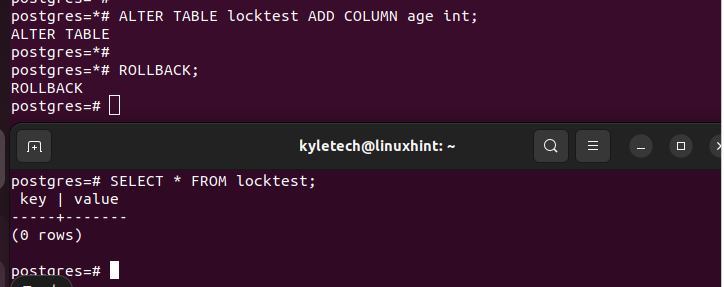
However, when you issue a ROLLBACK command to the first transaction, we can immediately notice that the lock is released. Now, the second transaction can proceed uninterrupted.
That’s how locks work on tables. Blocks read and write transactions when a DDL command is executed. With that understanding, we can move on to creating indexes concurrently.
How to Use PostgreSQL to Create an Index Concurrently
When creating indexes on PostgreSQL, the operation can quickly block all other transactions and can lead to losses. When indexing a table, Postgres locks it against the write operations, such as update and alter operations, until the index build completes.
The index transaction could take hours or long minutes, depending on your database size. Locking out other transactions in a production environment means that the system can be rendered unusable until the index build completes. If you have such a scenario, the best solution is to create indexes concurrently, which will do away with locks.
Indexing concurrently ensures that a transaction won’t block other transactions. Thus, normal transactions can occur in the middle of a build process. When you add CONCURRENTLY when indexing, PostgreSQL scans the indexed table and waits for all transactions to terminate. Thus, indexing concurrently takes longer but ensures that no delays are encountered in a production environment. Let’s see an example of normal indexing to understand how locking can cause chaos in a production environment.

Here, we have a table named “details” in which we accessed on our Postgres shell. Suppose we want to create a “btree” index on one column. We can execute the following command:
Our index is successfully created because we are dealing with a small table.
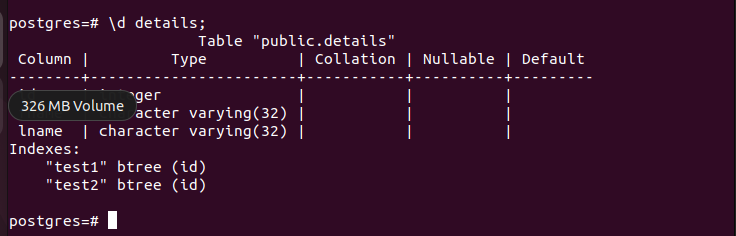
However, the same command could take hours to execute if you are in a live production environment. If you open another psql shell and try to write to the same table, the shell won’t respond until the indexing completes. If someone tries to update, insert, or perform another write operation, they will be locked out.
Such a scenario can be fixed by indexing the same table concurrently. The following is the syntax to create an index concurrently:

If we are to repeat the same index that we did earlier but, in this case, concurrently, our new command would be as follows:
In this case, if the indexing takes longer and we open another shell to perform a write operation to the table that we are indexing, we couldn’t get any lock error since the index build is done concurrently.
You can also create a “unique concurrent index” by adding the “unique” keyword. Unique indexing eliminates redundancy and raises errors whenever it detects a redundant column value.

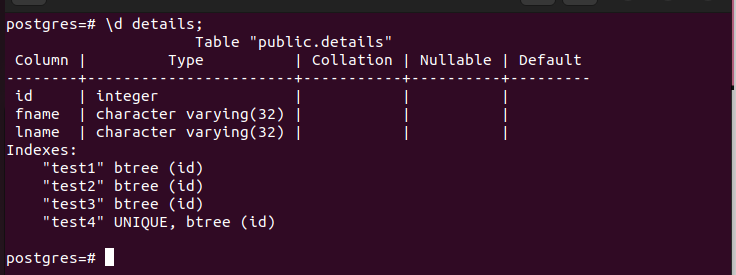
Here’s an example of unique concurrent indexing:
When you view the index table, you will notice that the indexing occurred successfully, and you can see which column has the unique indexing.
Conclusion
Creating an index without a concurrent approach leads to locking and blocking transactions. However, when you index concurrently, the index build will complete without preventing other transactions from occurring. This post helps you understand how locking works when working with tables in Postgres. Furthermore, we explained how to create an index concurrently to avoid locking when working with PostgreSQL.