PostgreSQL is a popular open-source relational database with a solid reputation for its reliability, flexibility, and support for open technical standards. It supports both relational and non-relational data types, making it one of the most compliant, stable, and mature relational databases.
In this guide, we will dive deep into using regex with PostgreSQL.
Prerequisites:
To perform the demonstrated steps in this guide, you need the following components:
- A properly-configured Linux system. Learn more about creating an Ubuntu virtual machine on VirtualBox.
- A proper PostgreSQL installation. Learn more about installing and setting up PostgreSQL on Ubuntu.
- Access to a non-root user with sudo Learn more about managing sudo privilege using sudoers.
Regex and PostgreSQL
A short term for regular expression, regex is a string of text that describes a pattern to match, locate, and manage the text. It’s a versatile tool is supported by many programming languages (Perl, Python, Java, Kotlin, Scala, Go, C++ etc.) and tools (awk, sed, Nginx, grep/egrep, and more).
PostgreSQL uses POSIX’s regular expressions that can function better than queries like LIKE and SIMILAR TO operators.
Demo Database
For demonstration purposes, we’re going to work with a dummy database which is populated with dummy entries.
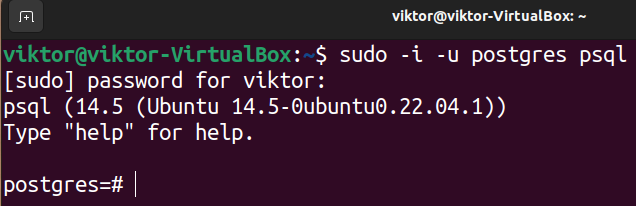
Connect to the local PostgreSQL server as postgres:
From the PostgreSQL shell, create a dummy database named demo_db:

Switch to the new database:

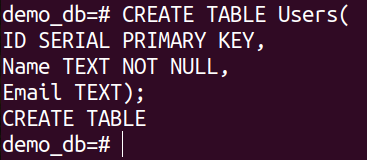
Create a new table:
ID SERIAL PRIMARY KEY,
Name TEXT NOT NULL,
Email TEXT);
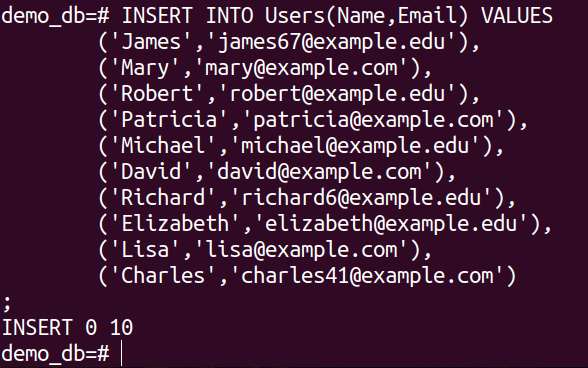
Next, populate the table with some values:
('James','[email protected]'),
('Mary','[email protected]'),
('Robert','[email protected]'),
('Patricia','[email protected]'),
('Michael','[email protected]'),
('David','[email protected]'),
('Richard','[email protected]'),
('Elizabeth','[email protected]'),
('Lisa','[email protected]'),
('Charles','[email protected]')
;
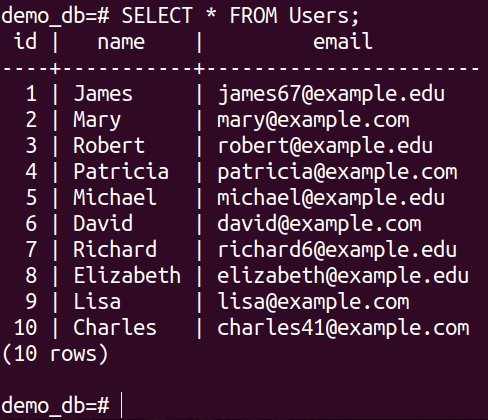
Check the content of the updated table:
PostgreSQL Match Operators
Here’s a short list of various PostgreSQL regex operators for pattern matching:
- ~: A common operator to match a regular expression (case sensitive)
- ~*: Matches the given regular expression (case insensitive)
- !~: Filters the unmatched occurrences (case sensitive)
- !~*: Filters the unmatched occurrences (case insensitive)
Example 1: An Introduction
Let’s start our journey with PostgreSQL regular expression with the following example:
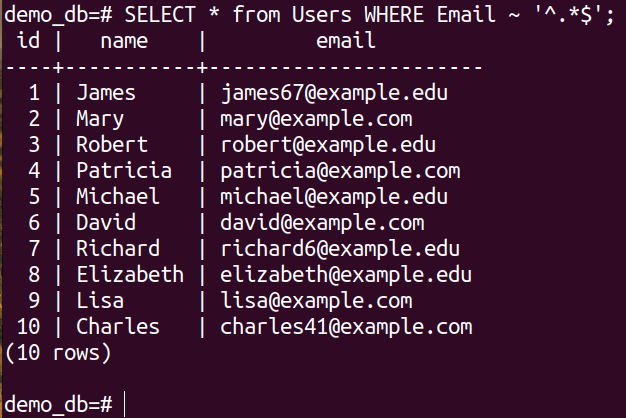
Here:
- The regular expression opens with the tilde (~) operator followed by a wildcard (*). It selects all the records from the Users table.
- The “^” operator denotes the start of a string.
- The “.” operator is a wildcard operator for a single character.
- The “$” operator denotes the end of a string.
All these operators together, “^.*$”, denote a string that starts with any character and ends with any string.
Example 2: Case Sensitive
By default, the tilde (~) operator is case sensitive. We can demonstrate this property using the following queries:
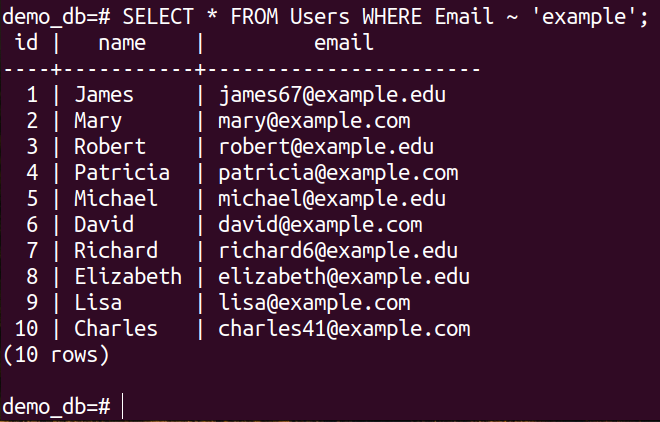
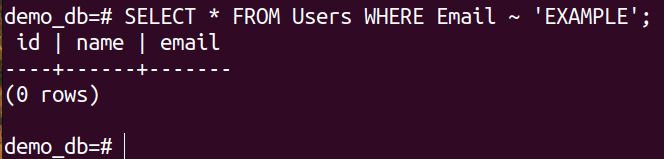
Example 3: Case Insensitive
If we want to perform the case-insensitive operations, we have to include the asterisk (*) operator along with the tilde (~) operator.
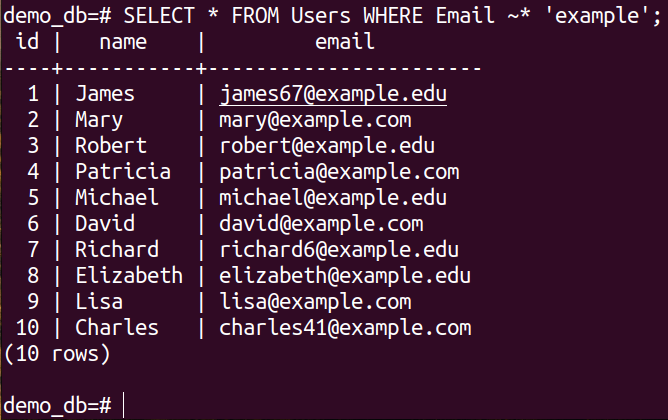
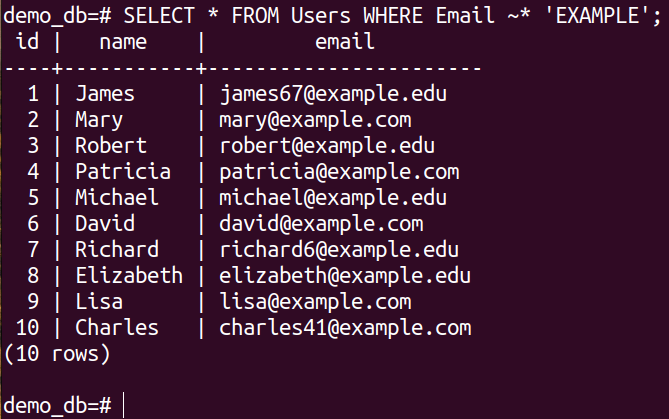
Since we specified the case-insensitive interpretation of the regular expression, both queries return the same output.
Example 4: Invert Match
By default, regular expressions match the specified pattern.
Have a look at the following query:

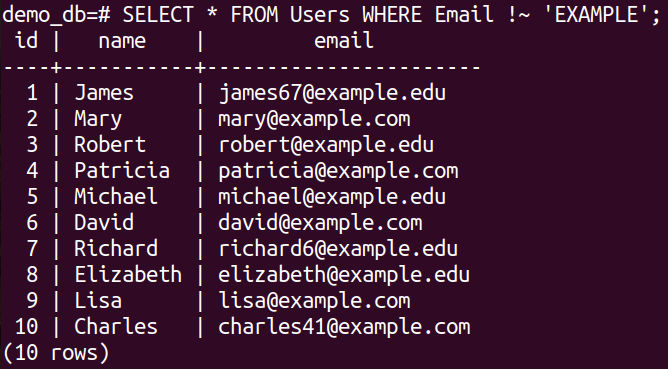
Here:
- The default behavior of the “~” operator is to match the regex specified pattern.
- Using the “!~” operator, we ignore the instances where the pattern matches.
To perform the case-insensitive invert match, use the “!~*” operator instead:


Example 5: Filter the Data by the End of the String
Run the following query:

Here:
- We filter the strings from the Email column based on the tail end.
- The “$” operator indicates the end of the string.
- The regex “com$” describes that it’s matching for strings that has “com” at the end.
Example 6: Filter the Data by the Beginning of the String
Look at the following query:
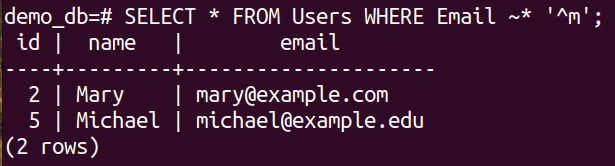
Here:
- We filter the strings from the Email column based on their initials.
- The “^” operator indicates the beginning of a string.
- The regex “^m” describes that it’s matching for strings that has “m” at the beginning.
Example 7: Numeric-Type Data
We can also use the regular expression to specify the finding entries that contain digits. The following query demonstrates it perfectly:
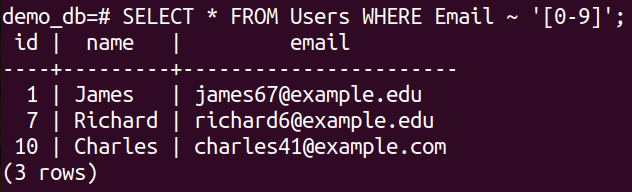
In this query, we use the character class feature of regular expression. Basically, it’s a shortcut way of representing certain character classes. For example, [0-9] is a representation of the digit character class.
For reference, here’s a short list of various regular expression character classes:
- Uppercase letter: [[:upper:]] or [A-Z]
- Lowercase letter: [[:lower:]] or [a-z]
- Alphabet: [[:alpha:]] or [A-Za-z]
- Alphanumeric: [[:alnum:]] or [A-Za-z0-9]
- Hexadecimal: [[:xdigit:]] or [0-9A-Fa-f]
- ASCII: [[:ascii:]]
PostgreSQL Regex Functions
Besides POSIX regular expression, PostgreSQL also comes with various regex-specific functions. This section showcases these functions with examples.
REGEXP_REPLACE()
The syntax of the REGEXP_REPLACE() function is as follows:
Here:
- source: A string where the replacement takes place.
- pattern: A POSIX regular expression to match the sub-strings that should be replaced.
- replacement_string: A string to replace the regex pattern matches.
- flags: It’s an optional component. It can be one or more character that influences the behavior of the function.
Let’s put the function in action:

We can also deploy the REGEXP_REPLACE() to work on strings from database entries:
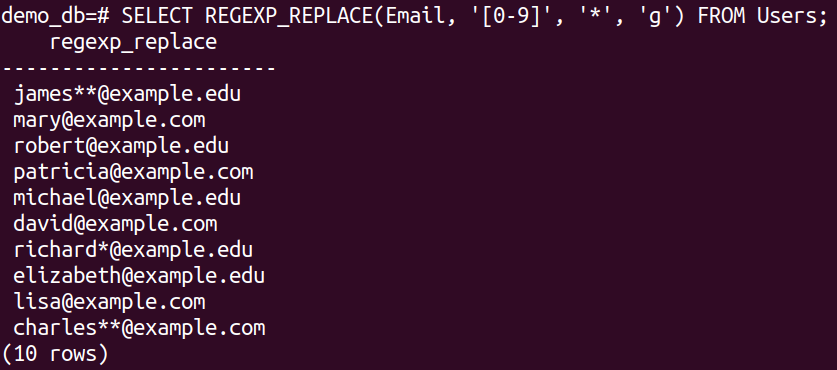
As instructed, the function replaces all the digits from all the entries under the Email column with an asterisk (*).
REGEXP_MATCHES()
As the name of the function suggests, REGEXP_MATCHES() is used to find all the instances of the pattern in a given string. The function syntax is as follows:
Here:
- source: A string where the function searches for the given pattern.
- pattern: A pattern that is described in POSIX regular expression.
- flags: It can be one or more characters that influence the behavior of the function.
Check out the following example:

Note that REGEXP_MATCHES() prints the output as a set.
Next, we filter the data from our database:
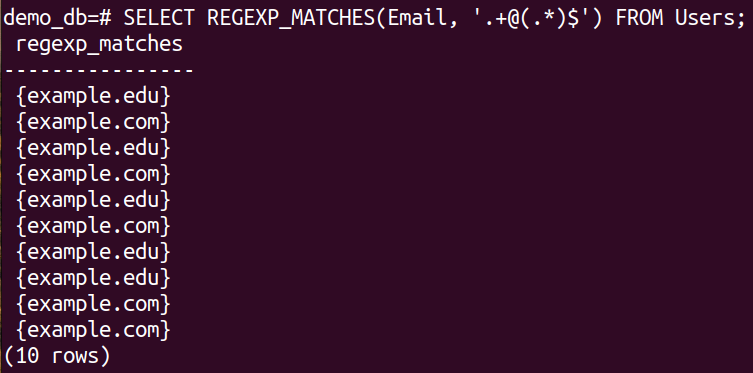
The output is a set of all the unique domains of the email addresses.
SUBSTRING()
The SUBSTRING() function returns a part of a given string. The substring is generated based on the given parameters.
The syntax of the SUBSTRING() function is as follows:
Here:
- string: The string that the function generates a substring from.
- start_position: A positive integer value that specifies the position to extract the substring from. If the value is 0, the substring extraction starts at the first character of the string.
- length: A positive integer value that specifies the number of characters to extract from the start_position. If not provided, the function acts as if the value is the maximum length of the given string.
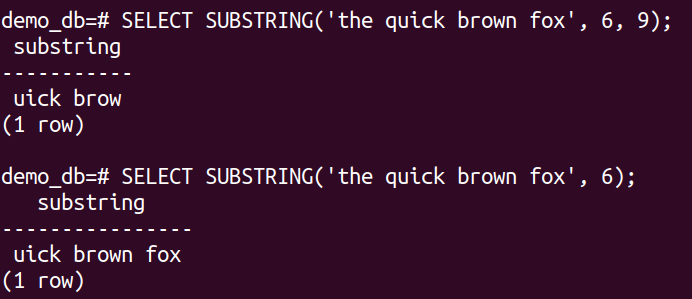
The following examples demonstrate the behavior of the SUBSTRING() function perfectly:
$ SELECT SUBSTRING('the quick brown fox', 6);
We can also utilize this function to manipulate the data that is pulled from the database:

The output prints all the unique domains of the email addresses as a list of substrings.
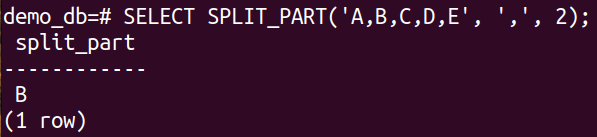
SPLIT_PART()
The SPLIT_PART() function takes a string and splits it into different parts. The syntax of the function is as follows:
Here:
- string: The string that is split into multiple substrings.
- delimiter: A string that is used as the delimiter for splitting.
- position: The position of the part to return. The value starts from 1.
Check out the SPLIT_PART() function in action:
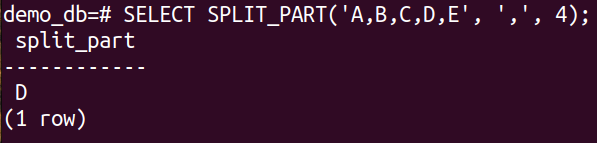
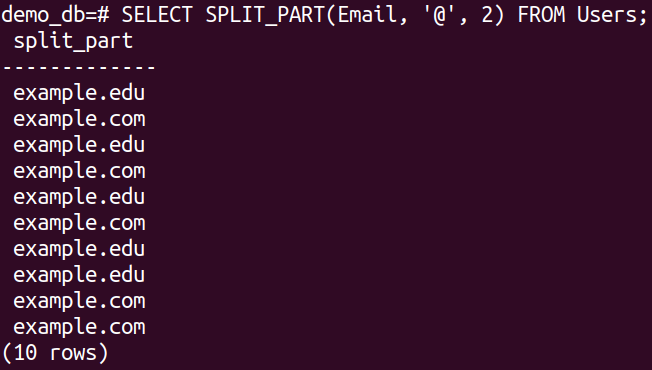
In the following example, we use the SPLIT_PART() to split the email addresses and grab the domain:
Conclusion
In this guide, we went on an in-depth tutorial on using the regular expression to construct the SQL statements and filter the data on PostgreSQL. The usage of regular expression allows far more flexibility than the other established methods. For example, using the LIKE operator.
In addition to basic implementation, we also demonstrated the usage of regex in various other PostgreSQL functions to greatly enhance their functionality. In fact, you can also implement the regular expression on user-defined functions.
Interested in learning more? The PostgreSQL sub-category contains hundreds of guides and tutorials on the various features of PostgreSQL.