When you have a TIME column in your PostgreSQL table, you can group the rows based on the hours. You might want to select various columns that match the given criteria that are specified in your GROUP BY clause. PostgreSQL allows you to group by hour from your column containing a TIME value.
This post discusses how the grouping works by presenting various examples to understand how the GROUP BY hour works. Let’s begin!
Working with the PostgreSQL GROUP BY Hour (Time)
The GROUP BY clause supports different functions, especially when working with date/time. In the case of time, you can use two main functions: the date_func and extract(). You can easily group the rows based on the hour in your time column using the two functions.
We use the following table for the different examples throughout the post:
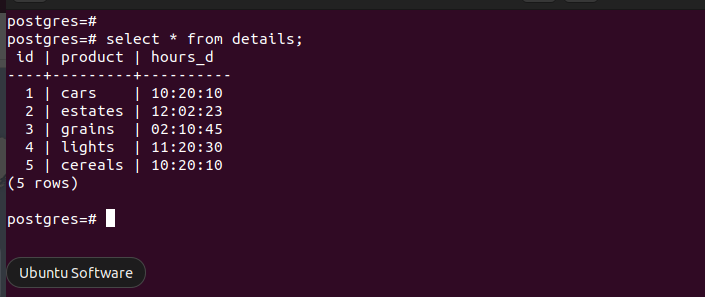
Example 1: GROUP BY Hour
When you want to group your table using your timestamp column, you can truncate the metric that you wish to use for the grouping. The DATE_TRUNC() allows you to group a timestamp column by hour, minute, day, week, etc. based on the selected columns.
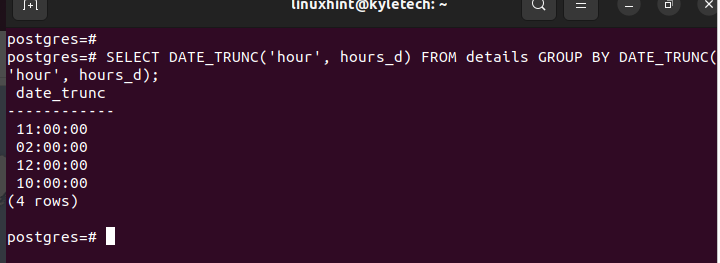
You focus on the “hour” as the metric for grouping by hour. The following example command truncates the timestamp column to group the rows based on the hour:
Since no column is selected, the output returns the group row which contains the hours from the timestamp column:
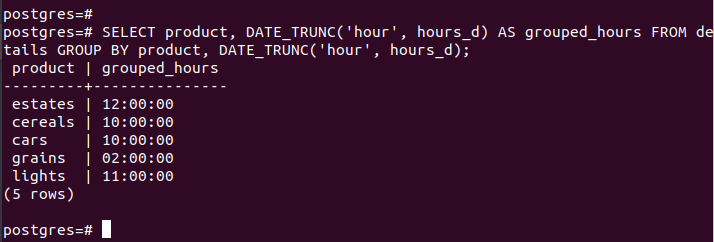
You could implement the command as illustrated in the following if you want to select more columns and give a better name for the grouped rows:
Here, we select the “product” column and add the “AS” statement to name the output row for the hours grouping.
Example 2: GROUP BY Hour Using EXTRACT()
You can get the various portions of the timestamp column with EXTRACT(). So far, we’ve seen how you can group the rows based on the hour. However, it’s possible also to extract only the hour of the day, leaving out the minutes and the seconds from the timestamp column.
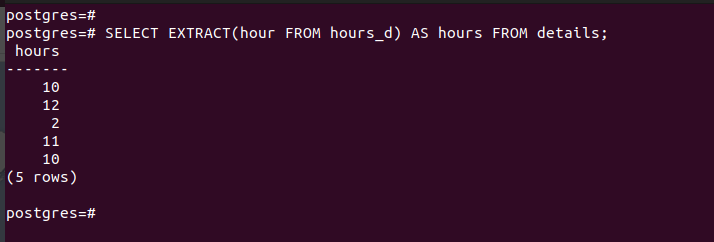
Here’s an example of extracting the hour without using the GROUP BY clause:
Example 3: Using the Aggregate Functions with the GROUP BY Hour
Aggregate functions are handy in achieving specific queries when working with the GROUP BY hour clause. For instance, if you want to count all the rows which contains the same hour, you can use COUNT() as demonstrated in the following image:
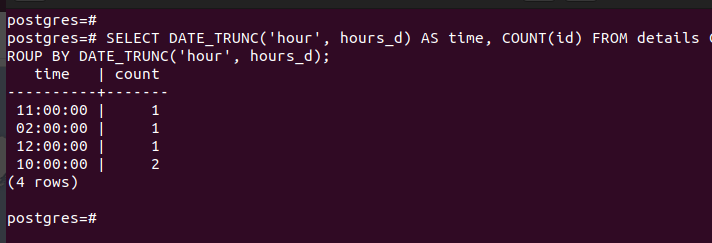
The previous output shows two entries in the table which contain the same hour. All the other values have unique hours in their timestamp, and their count returns as 1.
With the MAX () aggregate function, you can group the hours in the timestamp column by the hour and order them in descending order. Here’s an example:
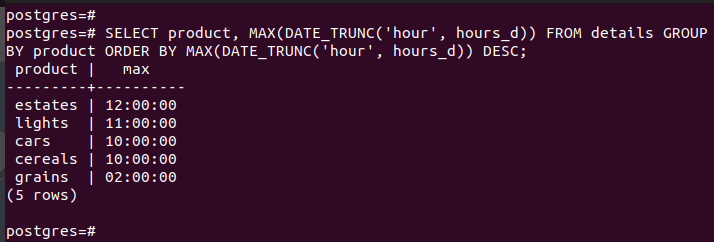
The output shows how the grouped row contains the products that are grouped by hour from the latest hour down to the earliest in the table. If you focus on the hours on a specific day, you could implement the same example to see the urgency in an orders_table.
How you implement the group-by-hour command depends on the needs of your queries and what you wish to achieve.
Conclusion
This post explained the group-by-hour clause. We explained how to group the timestamp columns using the EXTRACT and DATE_TRUNC functions. Moreover, we’ve seen how to use the aggregate functions with the group by hour. Hopefully, you can now work with the PostgreSQL GROUP BY hour (time).