Create a Collection
The following code introduces a new collection using the “Test” title to the existing database and responds with the “ok: 1” message to show that it was successful.
Add the Records
The following shown fields are added to each record that is inserted by the script into the “Test” collection: “name”, “pay”, “exp”, “date”, and “working”. There are many languages that are mentioned in the “exp” field. Each record contains a person’s data such as the name, salary, experience, date of hiring, and the current work status. The “insertMany” function receives the acknowledgment and produces the inserted IDs for every record as ObjectIds.
{ name: "John", pay: 23000, exp: ["C++", "Python", "Cobol"], date: ISODate("2002-08-27"), working: false},
{ name: "Simon", pay: 67800, exp: ["C#", "Oop", "Java"], date: ISODate("2015-09-14"), working: true },
{ name: "Peter", pay: 75000, exp: ["C#", "JavaScript", "Cobol"], date: ISODate("2018-05-22"), working: false},
{ name: "Cillian", pay: 39500, exp: ["Node.js", "Xml", "Cobol"], date: ISODate("2012-07-11"), working: true } ])
Match Aggregation
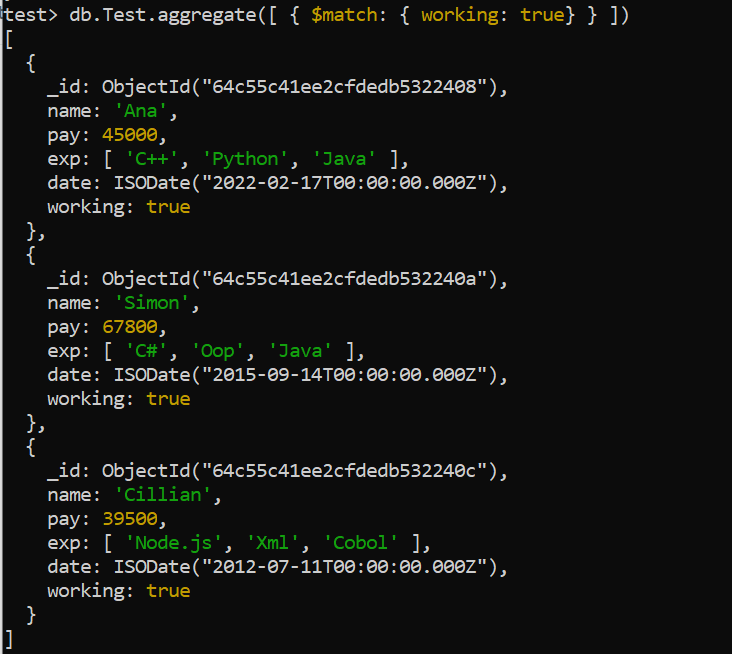
Match aggregation is used to search the results with specific conditions of matching via fields. So, in the following example, it aggregates the “Test” collection’s records and outputs those with the “working” attribute set to true. Three records with details about the currently working individuals named “Ana”, “Simon”, and “Cillian” are found once the collection is filtered.
Project Aggregation
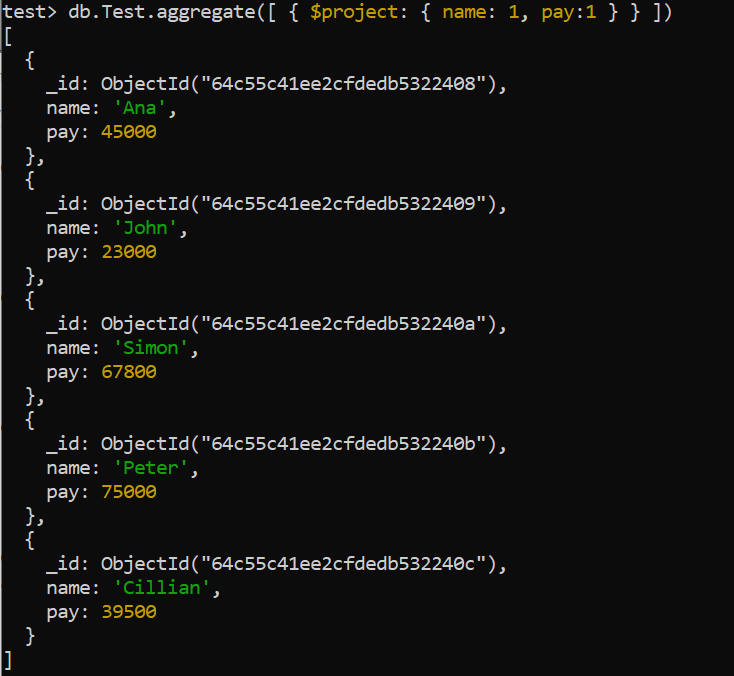
The $project aggregation can modify the collection of records by adding or removing the fields, adding the calculated fields, or renaming the preexisting fields. Here, it is used in the following script to restructure the “Test” collection records that only involve the “name” and “pay” columns in the result. The final result shows the names along with the pay for the “Ana”, “John”, “Simon”, “Peter”, and “Cillian” entries for every record in the collection.
Group Aggregation
The $group aggregation enables the users to execute the aggregate actions on the collected information, i.e. for calculating the totals, averages, similar statistics, and group records collectively according to a provided key or keys. The provided script searches the “Test” collection for the records that contains the name “Cillian”. It then gathers the filtered records and determines the average age and the overall salary of the workers with the name “Cillian”. The outcome reveals that the combined pay of all employees with the last name “Cillian” is $39500, and the age is null since no age field happens to be in the records.
... { $group: { _id: null, Salary: { $sum: "$pay" }, avgAge: { $avg: "$age" } } } ])

Sort Aggregation
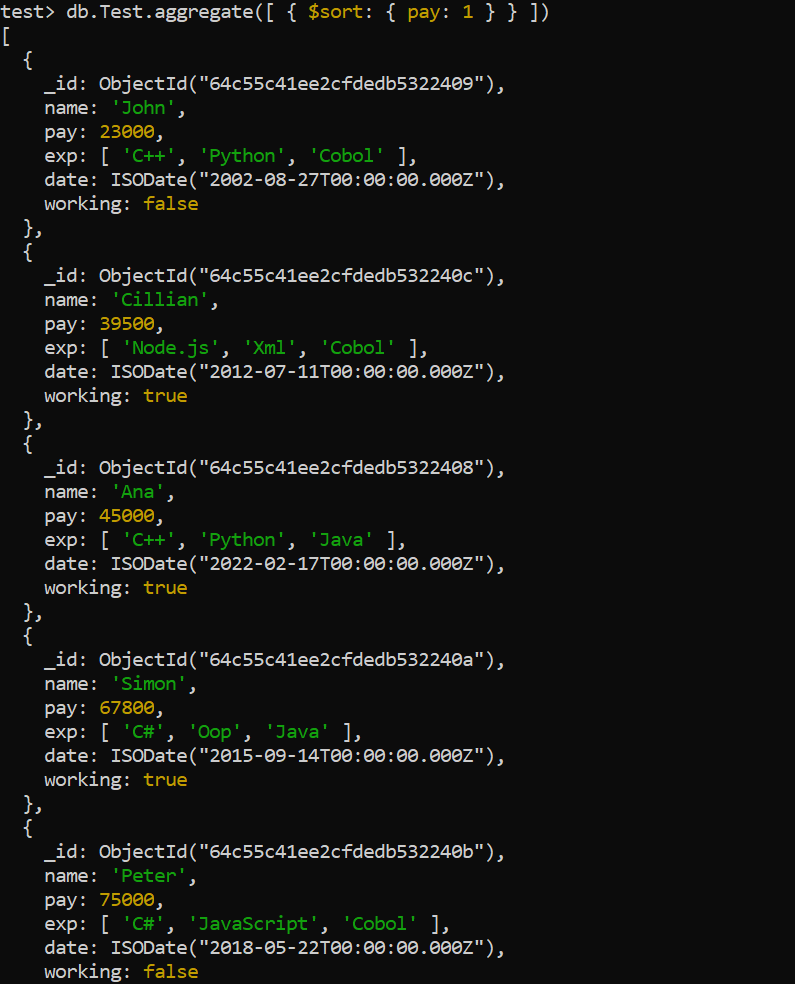
As the name suggests, the sort aggregation function organizes the records according to the sorting order of the mentioned columns in the function. Within the following script of an aggregate function, we use the sort aggregation to display all the records of the “Test” collection according to the “pay” field’s sorting order, i.e. ascending order. Therefore, all five records of the “Test” collection are displayed from a small amount of “pay” to a large amount of “pay” for each person.
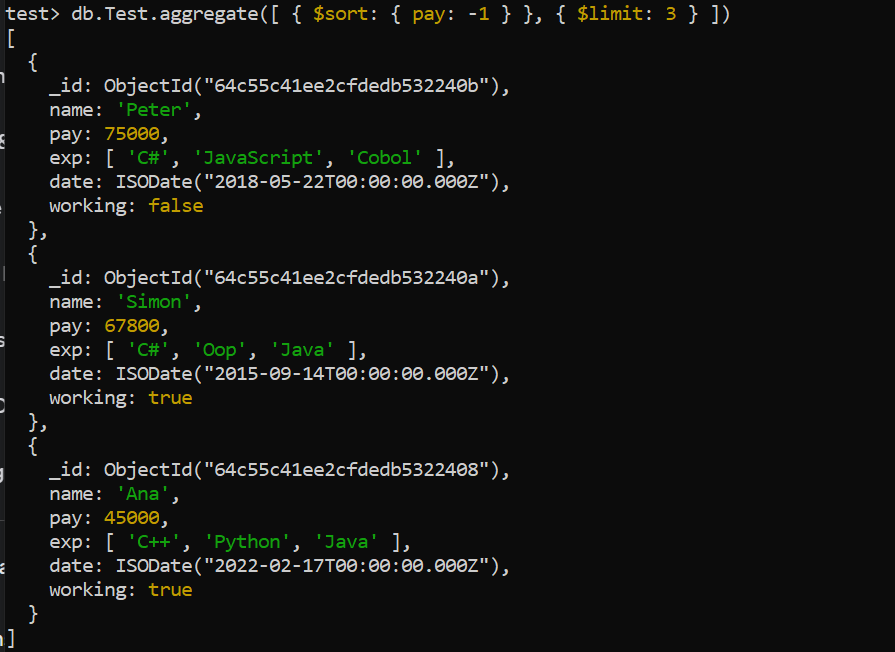
Limit Aggregation
Here comes the “limit” aggregation that restricts the number of records that are processed and displayed on the output. To demonstrate the use of limit aggregation, we try the aggregate function query in the MongoDB shell after the sort aggregation. It limits the number of records to 3 by displaying only three records and the sort aggregation is applied to the “pay” field set to -1 in descending order. Therefore, the output shows the three records with the descending order of the “pay” field, i.e. higher salary to smaller.
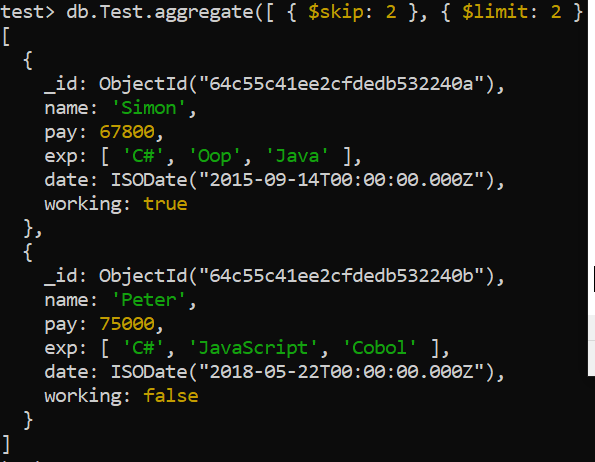
Skip Aggregation
The skip aggregation of MongoB is utilized to skip a certain number of output records, i.e. skipping the first exact number of records. The query that is shown in the following image uses the skip aggregation along with the limit aggregation to only display two records along with skipping the first two records of the “Test” collection. The output of this query displays the two records that are inserted at 3rd and 4th places in the collection by skipping the first two records.
Unwind Aggregation
The unwind aggregate function of MongoDB is utilized to create the independent records of collection by splitting the array-type columns where each splitted column has a separate record in the output. To demonstrate the working of the unwind aggregation, we apply it to the “exp” column of the “Test” collection.
Along with that, we try to skip the first three records and limit the output records to four using the skip and limit aggregations. The “exp” field of the “Test” collection is of array type, and each record of the collection has three values in the “exp” field. Therefore, every record should be splitted into three separate records. The output for this query must skip the first three splitted records for “Ana” and display the next four records as per the limit set to 4.
The outputted four records show the splitted field values for the “exp” column, i.e. 1 for C++, 1 for Python, 1 for Cobol, and 1 for C#.

AddFields Aggregation
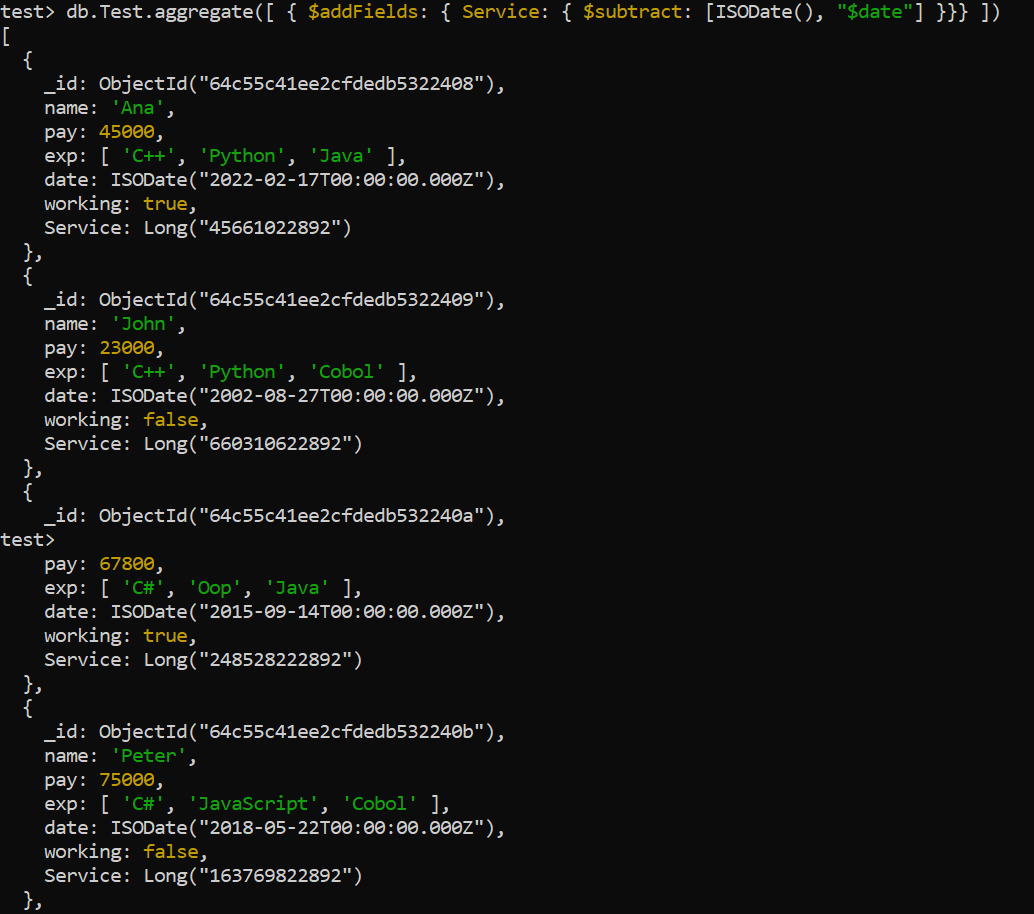
The addFields aggregation of MongoDB is specifically designed to insert new columns in the existing collection along with other records. It may be used to create the calculated columns or retrieve the data from the already-existing columns. The following attached code outputs that each record in the “Test” collection has its “Service” field which is determined by the MongoDB aggregation.
The period of service in milliseconds is calculated by subtracting the value of the “date” column which reflects every worker’s employment date from the current date (ISODate()). The initial columns (name, pay, exp, date, and working) for each worker are included in the aggregation’s output, combined with a recently “Service” column as shown in the following:
Conclusion
A strong tool for numerous data processing and reporting activities, MongoDB’s aggregation architecture offers a flexible and effective approach to handling and interpreting the data. The article includes almost all the aggregation functions for MongoDB to perform certain types of operations on the MongoDB collections via the coding illustrations.