What are Labels and Matchlabels?
Within Kubernetes, labels are a key/value formatted piece of metadata linked to an object. Additional information about the thing relevant to the consumer or object is provided via labels. For example, a label can identify a node’s hardware specifications or whether a workload is for production testing.
Labels serve as an implicit grouping technique for similar objects while also offering a lookup mechanism for users, controllers, and other systems.
Labels allow users to map their own organizational systems to system items in a loosely connected manner without requiring clients to save the mappings.
Multi-dimensional entities such as service deployments as well as batch processing pipelines are common. Cross-cutting actions are frequently required in management, which undermines the encapsulation of rigorously hierarchical representations, particularly inflexible hierarchies dictated by infrastructure rather than users.
Matchlabels are a type of key-value pair map. A single key value pair in the matchLabels map corresponds to an element of matchExpressions with the key field “key,” the operator “In,” and only “value” in the values array. A collection of pod selector requirements is called matchExpressions.
In, Exists, DoesNotExist, and NotIn are all valid and required operators. In the case of ‘In’ and ‘NotIn,’ make sure the values set are non-empty. All of the matchLabels and matchExpressions requirements are ANDed together, and they must all be met in order to match.
Prerequisite:
We need to install Ubuntu 20.04 in order to put the theoretical knowledge into practice and perform the instructions in Kubernetes. The kubectl commands are run on the Linux operating system in this example. In order to run Kubernetes on Linux, install the Minikube cluster. Minikube facilitates comprehension by providing an efficient mechanism for testing commands and applications.
We have executed the “minikube start” command on the terminal in order to initialize the Minikube. This command launches the Kubernetes cluster and creates a virtual machine capable of cluster execution. It will also connect with the cluster by using the kubectl installation. The “minikube start” command’s output is depicted below.

Creating a Deployment
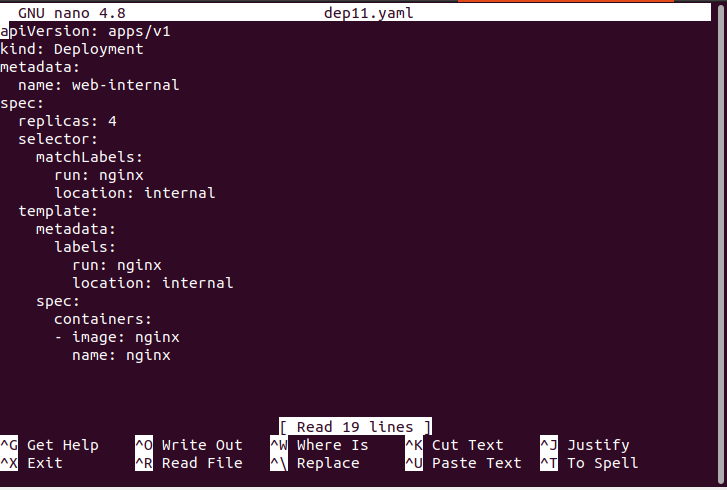
In this example, we have created two deployments. One for a web service that runs on internal infrastructure and another on DMZ infrastructure. The initial deployment (named dep11.yaml) is made, as shown below.
![]()
Here is the whole dep11.yaml configuration file, which includes the matchlabels field.
The command to create the pod is as follows.

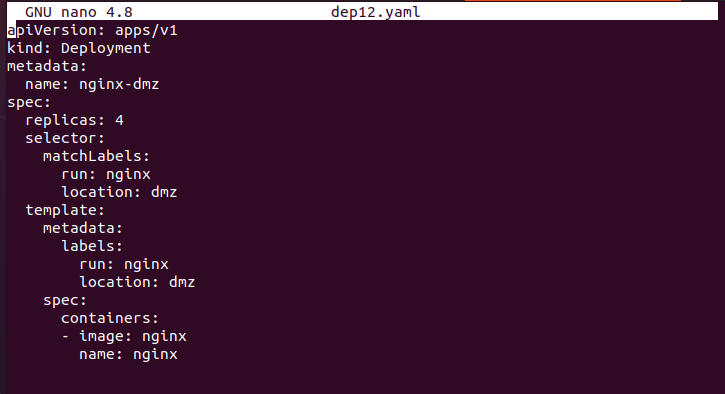
The deployment (named: dep12.yaml) that operates on the DMZ infrastructure is shown below.
![]()
The entire configuration file can be found below.
When the pods are deployed, they have the labels run=nginx. Multiple labels are possible for an object; however, multiple labels with the same key are not. If there are several label entries with the same key in an object manifest, the last value is used.
The selector tag can be seen here, which deployment utilises to communicate with its pods. The Deployment’s selector field specifies how it determines which Pods to manage. You need to select a label first from the Pod template. More complicated selection rules were also possible if the Pod template fit the criteria. Here is the command for creating the pod.

To see the labels of a pod, use the get subcommand:

The pods launched using the above deployment manifests are shown in the code block below. The pod-template-hash label is applied automatically by the deployment controller.
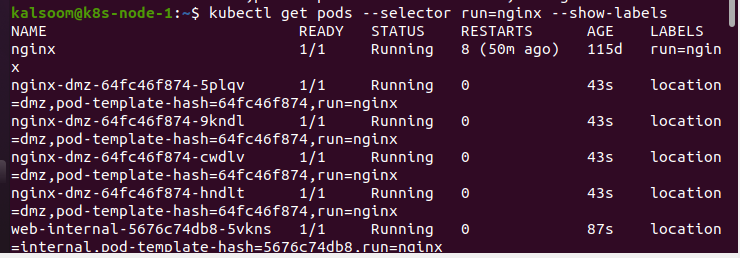
The pods provided by kubectl get pods can be filtered using one or more —selector parameters. In the output, the labels are presented as an additional column.
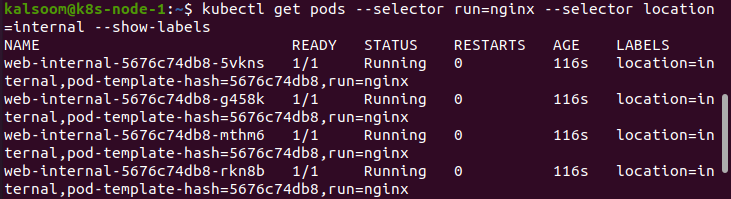
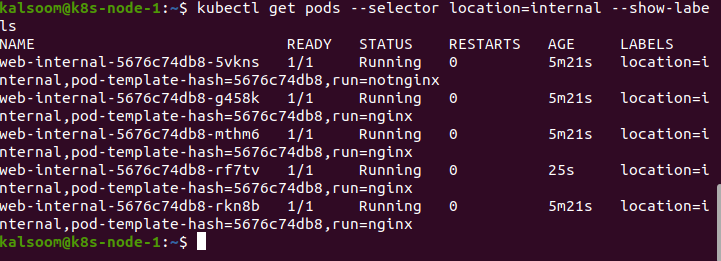
To get internal nginx pods, use several selectors.

The deployment controller uses a selector to determine which pods are included in a deployment. A replicaSet object is created when a deployment is created, and the replication controller monitors it to ensure that the number of pods operating matches the planned number.
Our deployments currently have four pods in a ready state.

The configuration of a replicaSet is shown below.
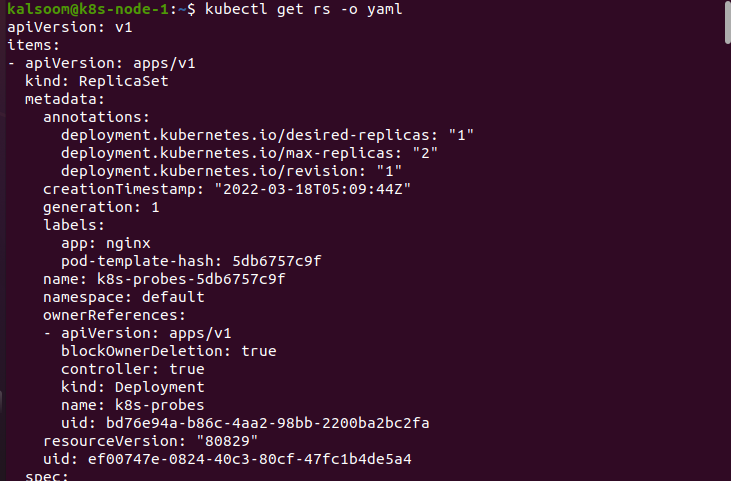
Here is the rest of the output of the overhead code.
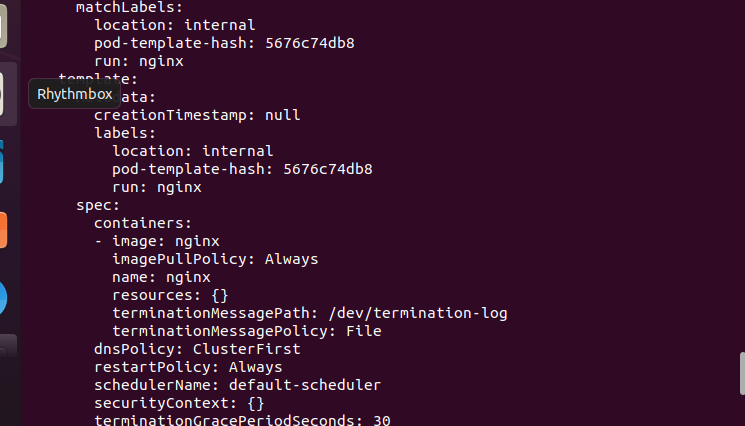
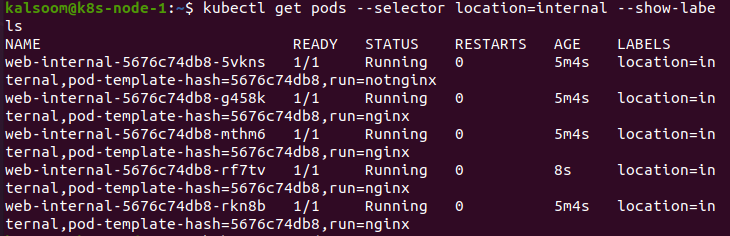
Let’s change one of the labels on a pod such that it no longer corresponds to our selector. Check out the matchLabels spec in order to see what happens.

After altering the run label on the pod and deploying another pod to resolve the issue, the replica controller could only locate three pods operating using the matchLabel selection.
To confirm the Deployment was created, run the ‘kubectl get deployments’ instruction. The following fields are presented when you inspect the Deployments in your cluster: NAME, READY, UP-TO-DATE, AVAILABLE, and AGE.

As you can see below, we utilized several criteria to acquire internal nginx pods.
Conclusion:
This article clarified the differences between labels and matchlabels. We have already seen the benefits of employing labels. The categorization and filtering capabilities of Kubernetes labels are fantastic, as you can see above. Using labels will make your logs more relevant, monitoring tools will allow you to choose certain workloads of interest, and bash scripting will provide you with a larger range of data to deal with.