Whether fixing the application in Kubernetes or on a computer, it’s important to ensure that the process stays the same. The tools used are identical, but Kubernetes is used to examine the form and outputs. We can utilize kubectl to begin the debugging procedure at any time or utilize some debugging tools. This article describes certain common strategies that we utilize to fix the Kubernetes placement and some definite faults we can assume.
In addition, we learn how to organize and manage Kubernetes clusters and how to arrange the whole policy to the cloud with constant assimilation and continuous distribution. In this tutorial, we are going to discuss further the Kubernetes clusters and the method of debugging and retrieving the logs from the application.
Prerequisites:
First, we need to check our operating system. This example utilizes the operating system Ubuntu 20.04. After that, we checked all further Linux distributions, depending on our preferences. Furthermore, we make sure that Minikube is an important module for running Kubernetes services. To implement this article smoothly, the Minikube cluster has to be installed on the system.
Start Minikube:
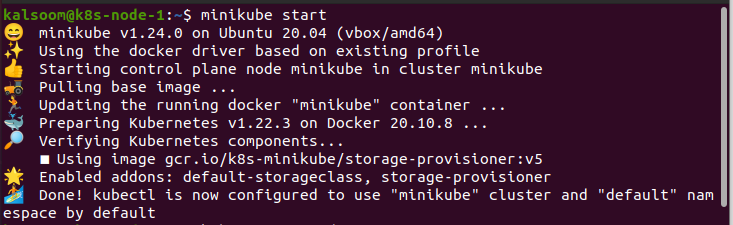
For running the commands, we need to open the terminal of Ubuntu 20.04. First, we open the applications of Ubuntu 20.04. Then, we search for “terminal” in the search bar. By doing this, the terminal can efficiently be initialized to work. The most significant objective is to launch Minikube:
Get the Node:
We start the Kubernetes cluster. To view the cluster nodes in a terminal in a Kubernetes environment, verify that we are associated with the Kubernetes cluster by running “kubectl get nodes”.
Kubectl is a tool that we can use to switch the Kubernetes cluster and provide a variety of commands. One of the important commands is “get”. It is used to enlist different nodes. We can utilize “kubectl get nodes” to get the information about the node. Here, we know about the name, status, roles, age, and version of the node. We also include -o in the command to acquire further data about nodes. In this step, we need to check the eminence of the node. To do this, initiate the command which is shown below:

Now, we utilize the –v parameter in the command. This is very helpful in Kubernetes. By executing the command, we carry out the actions that need to be accomplished. In this instance, we pass the value 8 to the parameter “v”. This command will give us the HTTP traffic. It provides a good instinct of how we switch with the code. It can also be used to identify the RBAC rules required for the code to send directly to kubectl in the code.
In this instance, there is a monitoring flag, and we can utilize this to monitor the updates for specific objects. When the kubelet’s log level detail is appropriately constructed, we execute the subsequent command to collect the logs:
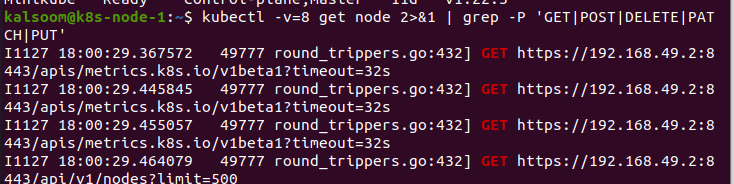
Here, we want to show which rules of RBAC are required. This will enlist the API requirements the code is writing and make it simple to understand the rules we want.
In this instance, we give 0 value to the parameter “v”. This command is observable to the worker at all times.

Next, we provide value 1 to the parameter “v”. By executing this command, an equitable avoidance log level is produced if we do not need verbosity.

In this case, we are using the parameter in the command “v”. By running the following command, we are executing an action that we need to achieve. We give 3 values to “v”. This prolongs the data about variations:

When we deliver 4 values to the “v” parameter, this command shows the Debug level verbosity:

In this example, we are providing value 5 to the verbosity “v”.

This command shows the demanded resources after getting the 6 value of the “v” parameter.
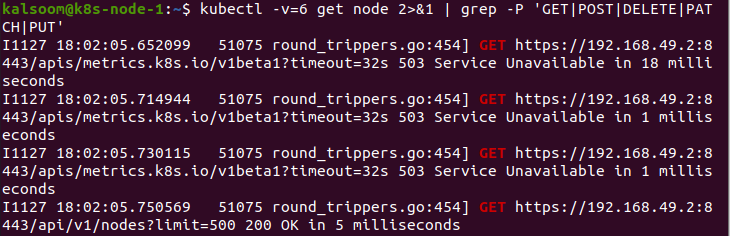
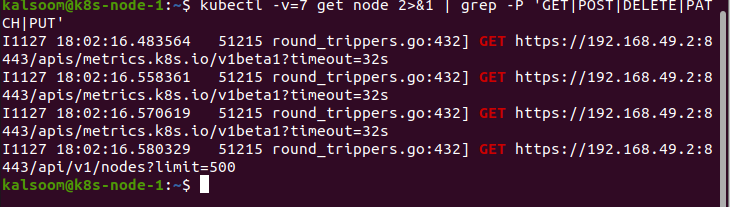
In the end, the parameter “v” contains the value 7. By giving this value to “v”, it shows the HTTP request headers:
Conclusion:
In this article, we have discussed the basics for creating a logging approach for the Kubernetes cluster. Also, regardless of whether we select an interior logging method, we should always make some exertion. It’s important to put all the logs in a place wherever we may examine them. This makes it easier to observe and troubleshoot the environment. In this way, we may diminish the likelihood of customer anomalies. We utilized the “v” parameter in commands. We provided different values to the parameter “v” and observe the log verbosity. We hope you found this article. Check out Linux Hint for more tips and information.