Apache Spark is defined as an open-source analytics engine that supports processing the large data. Its foundation is based on Resilient Distributed Dataset (RDD). Spark is founded on a computational engine and works with Python, Java, Scala, and SQL.
When working with Python, you need a PySpark Python library. It is a tool that is designed to support using the Apache Spark with Python. It is commonly referred to as Apache PySpark. This guide focuses on the steps to install PySpark on Rocky Linux 9. Let’s begin!
How to Install PySpark on Rocky Linux 9
Apache PySpark has different prerequisites required for its installation. You must have an installed Python 3.6 or later, JDK, and Apache Spark. In the installation steps, we will see how to install some of these prerequisites to support the final step of installing PySpark. Follow keenly.
1. Install JDK
The Java development kit is required before we can get PySpark installed. Start by checking for updates.

Next, update your Rocky Linux 9 to get the latest package list version.
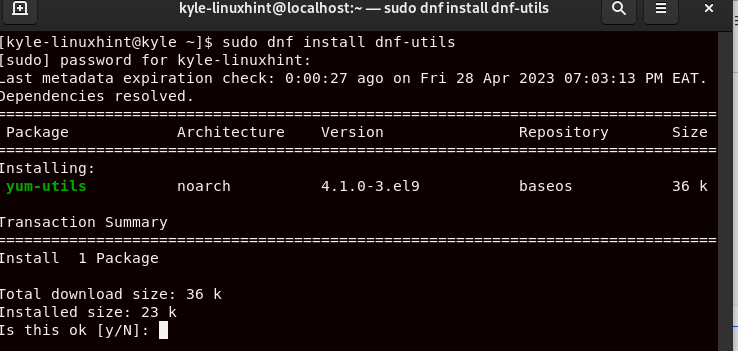
You can then install JDK. Here, we install Java JDK 11.
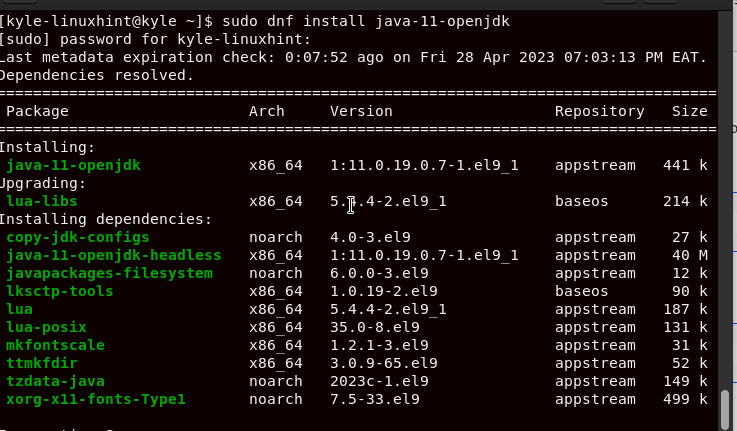
Ensure that the installation goes to completion. All the required packages will be downloaded and installed. Once all is done, you will receive an output which confirms the installation is complete.
Verify the installed JDK with the following command:
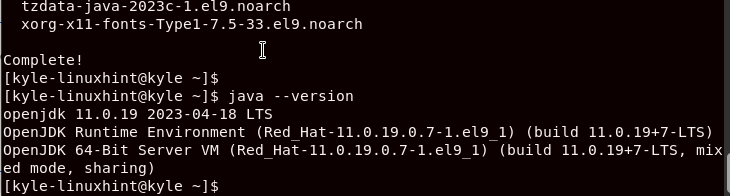
The output confirms that we have the openjdk 11 installed on our Rocky Linux 9.
2. Install Apache Spark
The Spark package is not available on Rocky Linux 9 repository. We must download the Apache Spark package directly from its website to install it.
We use the wget option to download the archived package file.
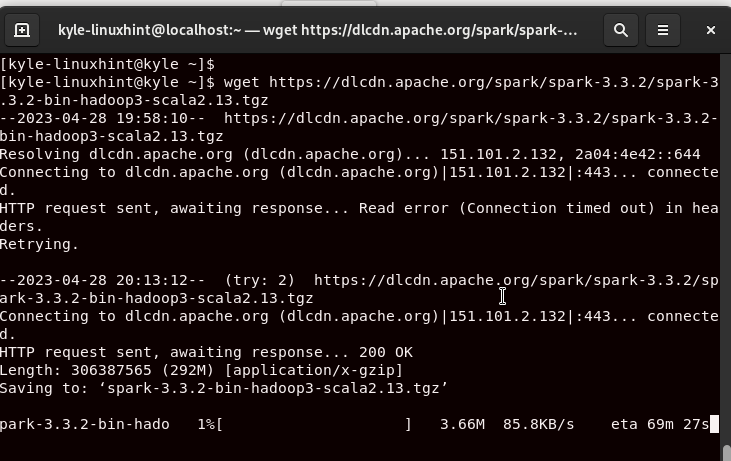
Once wget completes downloading the Spark package, you can list the directory’s contents and verify that the package is there.

The downloaded package is a tar file. Hence, we must extract it using the following tar command:
Ensure that you add the correct filename depending on the Apache Spark package version that you downloaded.

Numerous files are extracted to your current directory and stored under the Spark folder. Listing the directory’s contents again, we see that a Spark folder is created. It contains all the necessary files to install Apache Spark.
Move this file to your /opt where the optional files are stored.

Executing that command creates the spark folder inside /opt and store all the Spark package files that we extracted earlier.
You also must set up the environmental variables by exporting the path. For that, you should append the ~/.bashrc file. Run the following two commands:
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin

Lastly, update the ~./bashrc for the environmental variables changes to take effect.

3. Install PySpark
After completing the previous two steps, Apache Spark is installed on your Rocky Linux 9. The remaining step is to install PySpark using pip. For pip to work, you must have the Python3 installed.
However, if you don’t have it, you can still run the command and install pip and the required packages at a go. You will get prompted on what move to take to install the packages.


Pip then starts downloading PySpark. Once the download completes, the PysSpark Python library is installed by running its setup script.
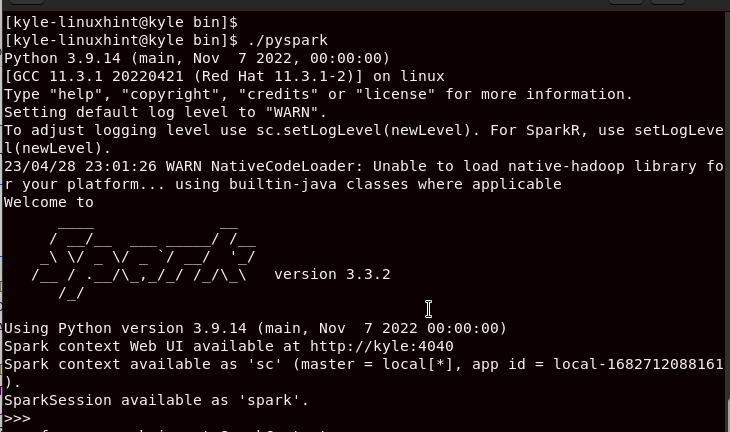
Now, you are ready to start using PySpark for your computation. To open PySpark, navigate to the /opt/spark directory and open the /bin. Inside it, run the ./pyspark command to bring up the PySpark shell. It appears as shown in the following:
./pyspark
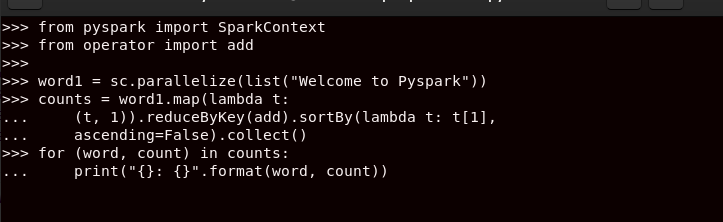
You can import PySpark to use it in your code. The following example is a simple code to print and arrange a string based on the number of counts that the letters in the string appear.
By running the code, we get our output as follows:
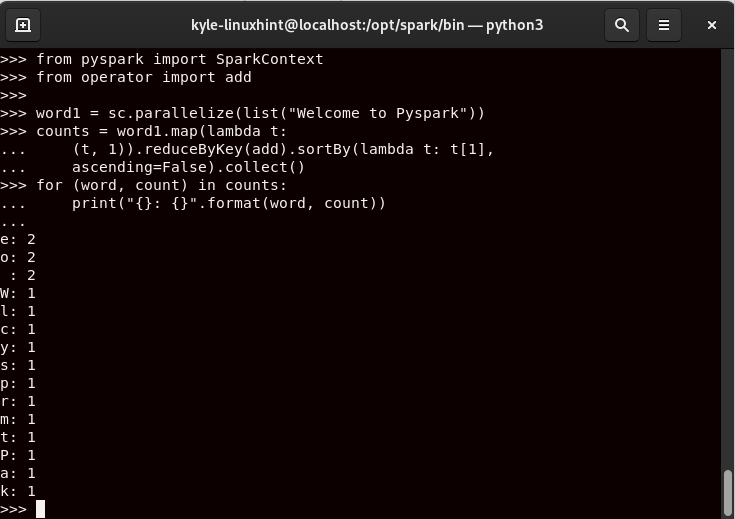
That confirms that we successfully installed PySpark on Rocky Linux 9. You can expound on it to perform more complex computations.
Conclusion
To use Apache Spark with Python, you need the PySpark library. This guide covered a comprehensive guide on installing PySpark on Rocky Linux 9, from installing JDK to installing Apache Spark. With the covered steps, follow along and start using PySpark on your Rocky Linux 9.