Knowing and manipulating database management systems have made us familiar with alterations about databases. Which typically involves creating, insert, update and delete functions applied on specific tables. In the current article, we will see how data is managed by the insertion method. We must have to create a table in which we want insertion. Insert statement is used for the addition of new data in rows of tables. PostgreSQL inserts statement covers some rules for the successful execution of a query. Firstly we have to mention the table name followed by column names (attributes) where we want to insert rows. Secondly, we must enter the values, separated by a comma after the VALUE clause. Finally, every value must be in the same order as the sequence of attribute lists is provided while creating a particular table.
Syntax
Here, a column is the attributes of the table. Keyword VALUE is used to enter values. ‘Value’ is the data of tables to be entered.
Inserting row functions in PostgreSQL shell (psql)
After successful installation of postgresql, we will enter the database name, port number, and password. Psql will be initiated. We will then perform queries respectively.
Example 1: Using INSERT to add new records to tables
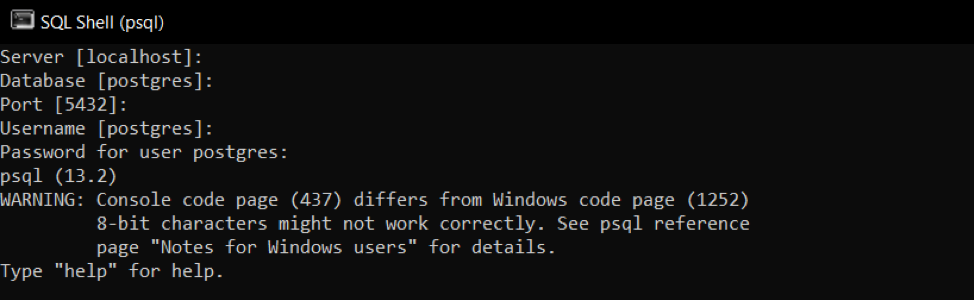
Following the syntax, we will create the following query. To insert a row in the table, we will create a table named “customer”. Respective table contains 3 columns. Data-type of particular columns should be mentioned to enter data in that column and to avoid redundancy. Query to create a table is:

After creating the table, we will now enter data by inserting rows manually in separate queries. Firstly, we mention the column name to maintain the accuracy of data in particular columns regarding attributes. And then, values will be entered. Values are encoded by single comas, as they are to be inserted without any alteration.
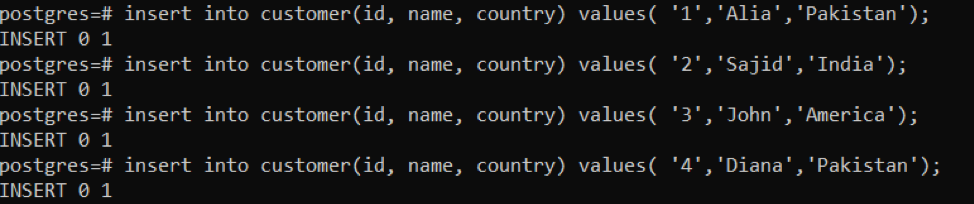
After every successful insertion, the output will be “0 1,” which means that 1 row is inserted at a time. In the query as mentioned earlier, we have inserted data 4 times. To view the results, we will use the following query:
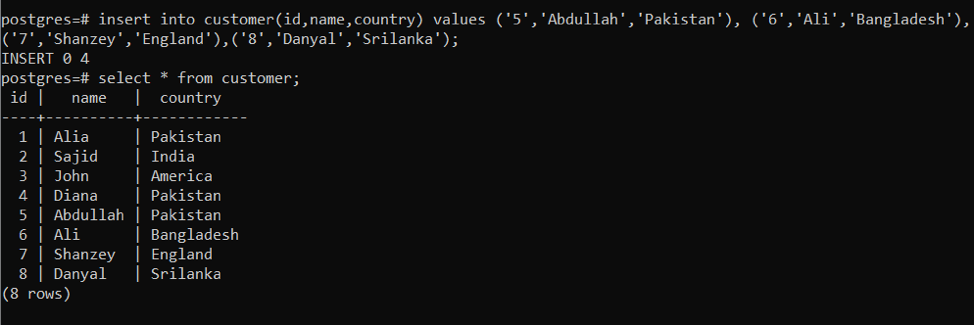
Example 2: Using INSERT statement in adding multiple rows in a single query
The same approach is used in inserting data but not introducing insert statements many times. We will enter data at once by using a certain query; all values of one row are separated by” By using the following query, we will attain the required output
Example 3: INSERT multiple rows in one table based on numbers in another table
This example relates to the insertion of data from one table to another. Consider two tables, “a” and “b”. Table “a” has 2 attributes, i.e., name and class. By applying a CREATE query, we will introduce a table. After the creation of the table, data will be entered by using an insert query.
>> Insert into a values (‘amna’, 1), (‘bisma’,’2’), (‘javed’,’3’), (‘maha’,’4’);

Four values are inserted into the table using the exceeding theory. We can check by using select statements.
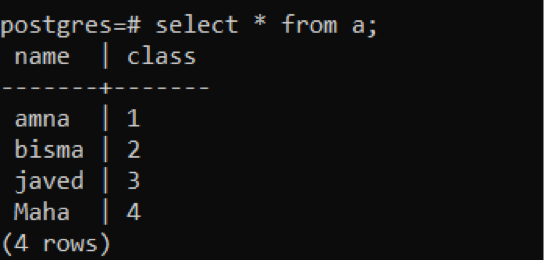
Similarly, we will create table “b,” having attributes of all names and subjects. The same 2 queries will be applied to insert and to fetch the record from the corresponding table.

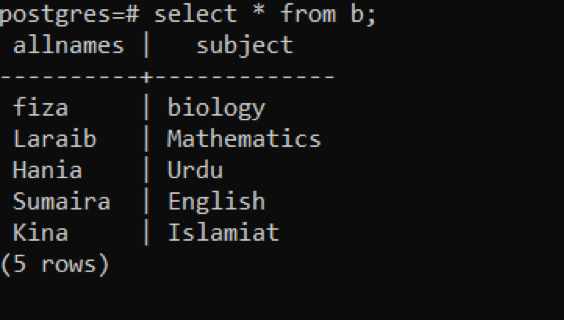
Fetch the record by select theory.
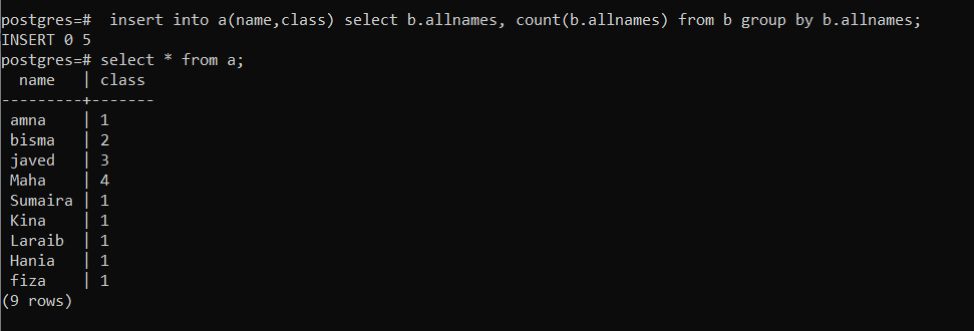
To insert values of table b in the table, we will use the following query. This query will work in such a way that all names in table b will be inserted in table a with the counting of numbers that show the number of occurrences of a particular number in the respective column of table b. “b.allnames” represents the object function to specify the table. Count (b.allnames) function works to count total occurrence. As every name is occurred at once so, the resultant column will have 1 number.
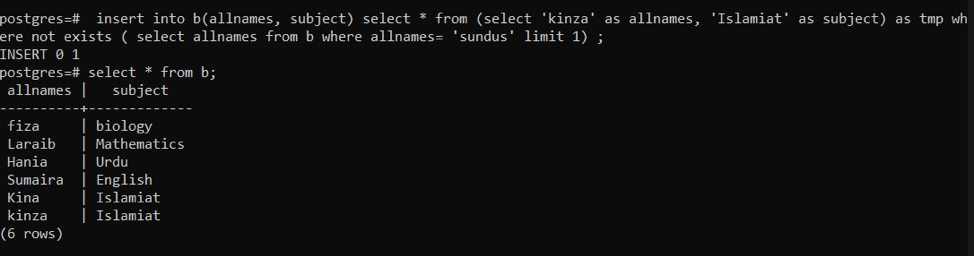
Example 4: INSERT data in rows if not exists
This query is used to enter rows if it is not present. Firstly the provided query checks if the row is already present or not. If it already exists, then data is not added. And if data is not present in a row, the new insertion will be held. Here tmp is a temporary variable used to store data for some time.
Example 5: PostgreSQL Upsert Using INSERT Statement
This function has two varieties:
- Update: if a conflict occurs, if the record matches the existing data in the table, it is updated with new data.
- If a conflict occurs, do nothing: If a record matches with the existing data in the table, it skips the record, or if an error is founded, it is also ignored.
Initially, we will form a table with some sample data.
After creating table we will insert data in tbl2 by using query:
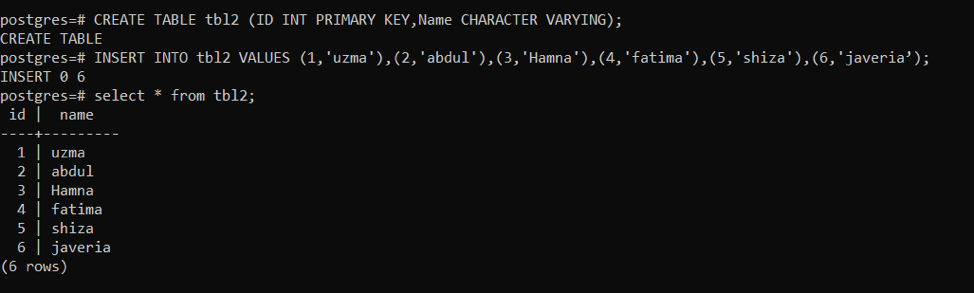
If a conflict occurs, Update:
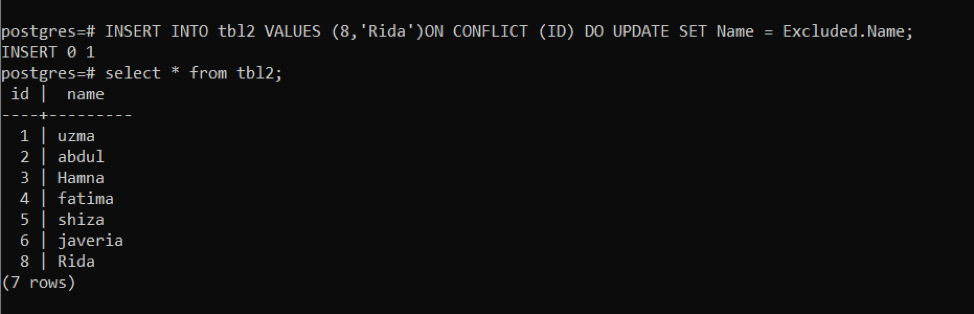
At first, we will enter data using the conflict query of id 8 and the name Rida. The same query will be used following the same id; the name will be changed. Now you will notice how names will be changed on the same id in the table.
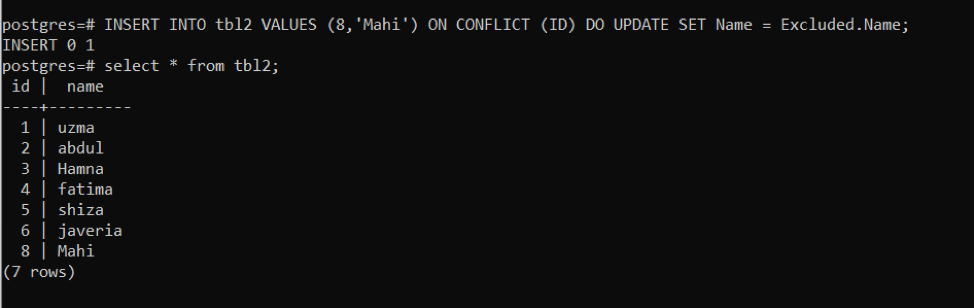
We have found that there was a conflict on id “8”, so the specified row is updated.
If a conflict occurs, do nothing
Using this query, a new row is inserted. After that, we will use if the same query to see the conflict that occurred.
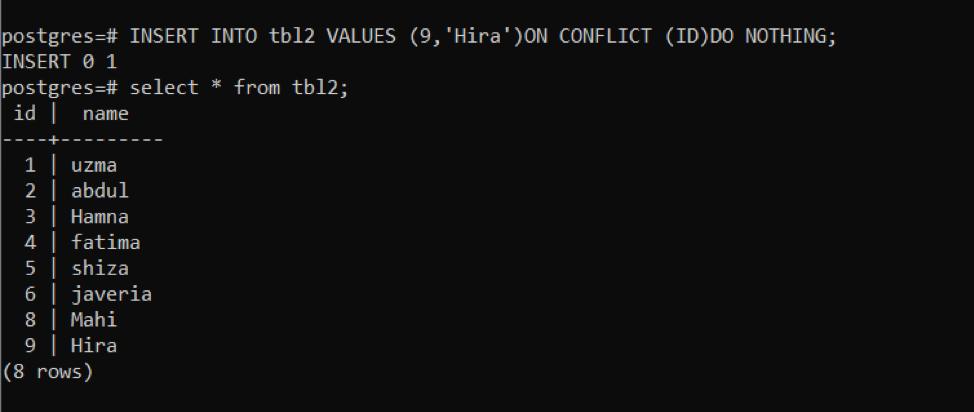
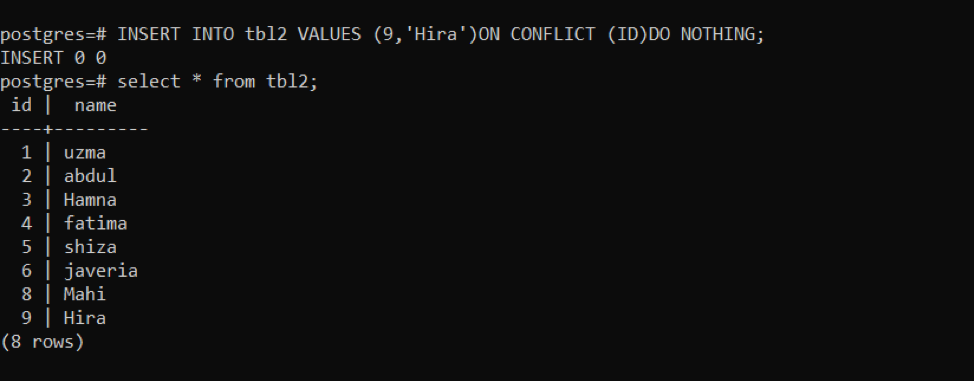
According to the above image, you will see that after the execution of the query “INSERT 0 0” shows no data is entered.
Conclusion
We have taken a glimpse of the understanding concept of inserting rows in tables where data is either not present, or insertion is not completed, if any record is found, to reduce redundancy in database relations.