The basic syntax used for this purpose is
\d+ table-name;
Let us start our discussion regarding the description of the table. Open psql and provide the password to connect with the server.

Suppose we want to describe all the tables in the database, either in the system’s schema or the user-defined relations. These all are mentioned in the resultant of the given query.
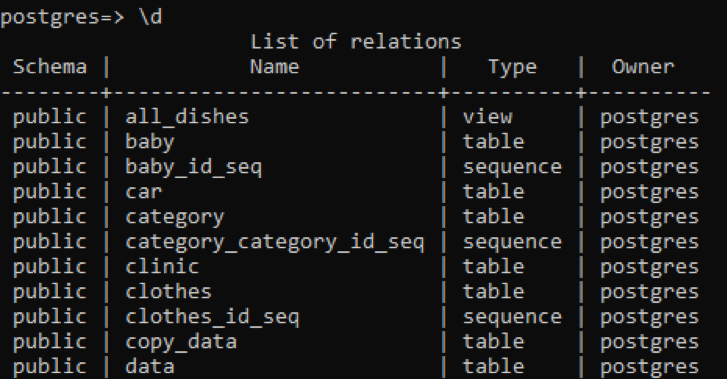
The table displays the schema, names of the tables, the type, and the owner. The schema of all the tables is “public” because each created table is stored there. The type column of the table shows that some are “sequence”; these are the tables that are created by the system. The first type is “view”, as this relation is the view of two tables created for the user. The “view” is a portion of any table that we want to make visible for the user, while the other part is hidden from the user.
“\d” is a metadata command used to describe the structure of the relevant table.
Similarly, if we want to mention only the user-defined table description, we add “t” with the previous command.
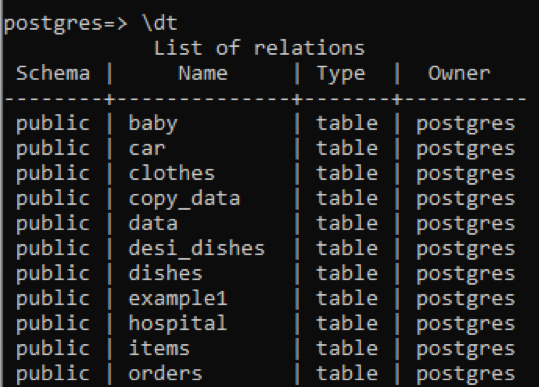
You can see that all the tables have a “table” data type. The view and sequence are removed from this column. To see the description of a specific table, we add the name of that table with the “\d” command.
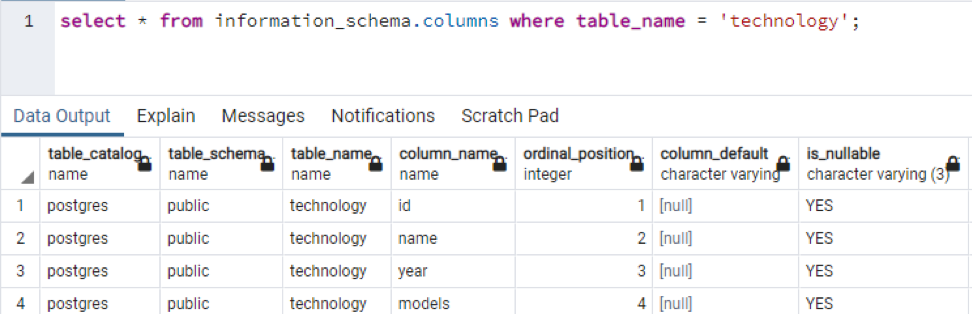
In psql, we can get the description of the table by using a simple command. This describes each column of the table with the data type of each column. Let suppose we have a relation named “technology” having 4 columns in it.
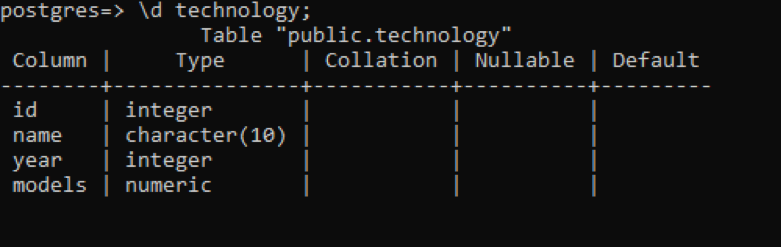
There is some additional data compared to the previous examples, but all of these have no value regarding this table, which is user-defined. These 3 columns are related to the internally created schema of the system.
The other way of getting the description of the table in detail is to use the same command with the sign of “+”.

This table shows the column name and the data type with the storage of each column. The storage capacity is different for each column. The “plain” shows that the data type has a limitless value for the integer data type. Whereas In the case of character (10), it shows that we have provided a limit, so the storage is marked as “extended”, this means that the stored value can be extended.
The last line in the table description, “Access method: heap,” shows the sorting process. We used the “heap process” for sorting to get data.
In this example, the description is somehow limited. For enhancement, we replace the table name in the given command.
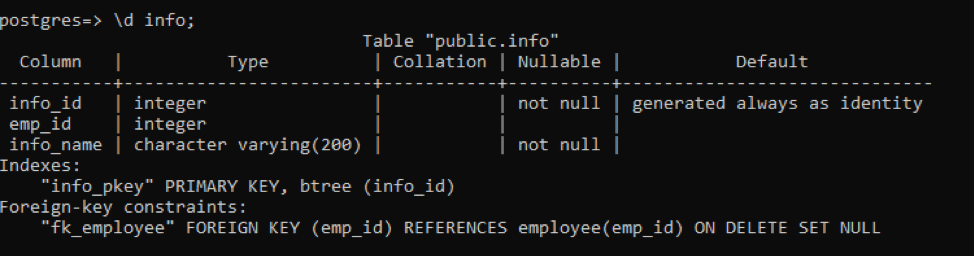
All the information displayed here is similar to the resultant table seen before. Unlike that, there is some additional feature. The column “Nullable” shows that two table columns are described as “not null”. And in the “default” column, we see an additional feature of “always generated as identity”. It is considered as a default value for the column while creating a table.
After creating a table, some information is listed that shows the indexes number and the foreign-key constraints. Indexes show the “info_id” as a primary key, whereas the constraints portion displays the foreign key from the table “employee”.
Till now, we have seen the description of the tables that were already created before. We will create a table using a “create” command and see how the columns add the attributes.

You can see that each data type is mentioned with the column name. Some have size, whereas others, including integers, are plain data types. Like the create statement, now we are going to use the insert statement.

We will display all data of the table by using a select statement.
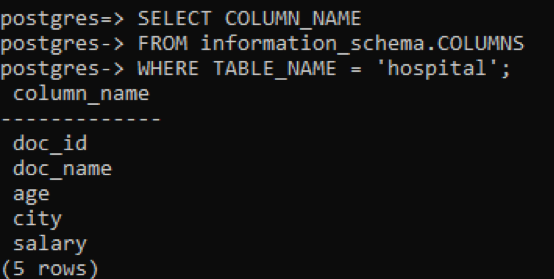
Irrespective of all the information regarding the table is displayed, if you want to restrict the view and want the column description and data type of a specific table only to be displayed, that is a part of the public schema. We mention the table name in the command from which we want the data to be displayed.

In the below image, the table_name and column_names are mentioned with the data type in front of each column as the integer is a constant data type and is limitless, so it doesn’t need to have a keyword “varying” with it.
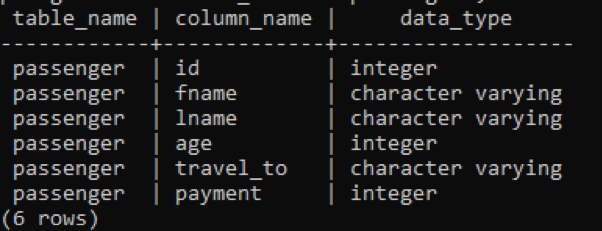
To make it more precise, we can also use only a column name in the command to display the names of the table columns only. Consider the table “hospital” for this example.
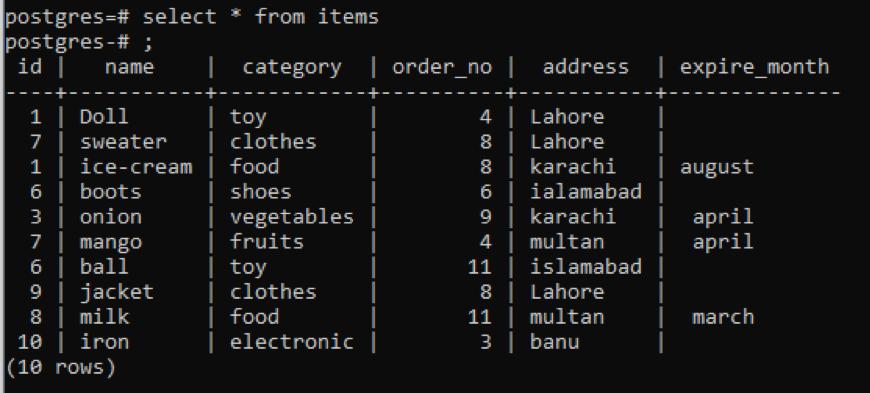
If we use a “*” in the same command to fetch all the table’s records present in the schema, we will come across a large amount of data because all the data, including the specific data, is displayed in the table.
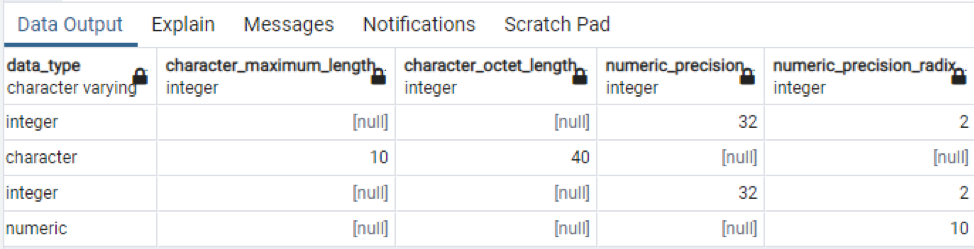
This is a part of the data present, as it is impossible to display all the resultant values, so we have taken some snaps of a few data to create a little view.
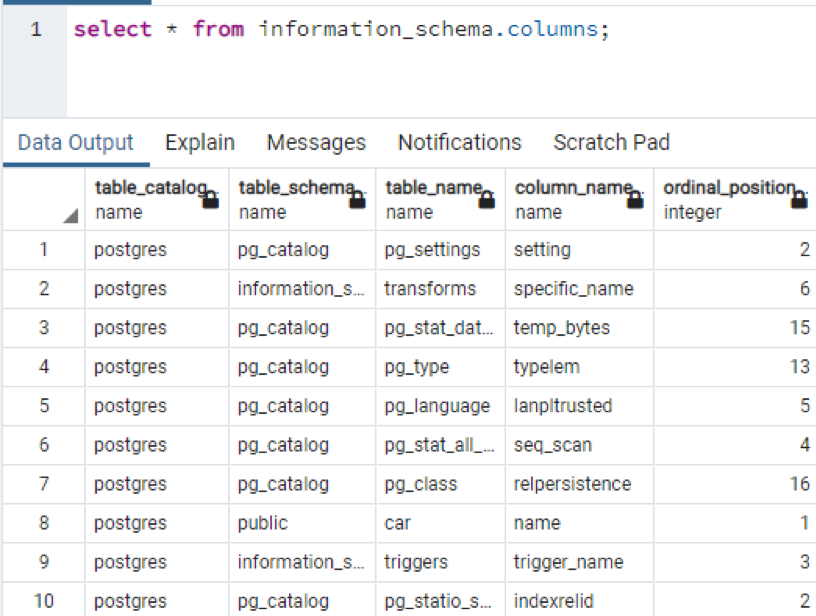
To see the number of all the tables in the database schema, we use the command to see the description.

The output shows the schema name and also the table type along with the table.

Just like the total information of the specific table. If you want to display all the column names of the tables present in the schema, we apply the below-appended command.

The output shows that there are rows in thousands that are displayed as the resultant value. This shows the table name, owner of the column, column names, and a very interesting column that shows the position/location of the column in its table, where it is created.
Conclusion
This article, “HOW DO I DESCRIBE A TABLE IN POSTGRESQL,” is explained easily, including the basic terminologies in the command. The description includes the column name, data type, and schema of the table. The column location in any table is a unique feature in postgresql, that discriminate it from other database management system.