What Is an EndpointSlice in Kubernetes?
EndpointSlice in Kubernetes is a network endpoint tracker. It makes it possible to monitor the network endpoints in a Kubernetes cluster. In simple words, it is an object that gets the IP addresses from each pod assigned to it. Kubernetes service refers to this object to get the record of the pod’s internal IP addresses for communication. Moreover, these endpoints are used by the pods to get themselves exposed to a service.
In the Kubernetes realm, these endpoints work as an abstraction layer which helps the Kubernetes service to make sure that there is a distribution of traffic to pods in the cluster. However, when a load of traffic increases, the traffic scaling issue occurs. This is because a single endpoint holds all the network endpoints for each service. And when these sources grow to an unacceptable size, the performance of Kubernetes gets impacted negatively. In other words, when the number of network endpoints grows immensely, the ability of Kubernetes to scale the deployment gets negatively impacted. Let us understand this with the help of the following graphical image:
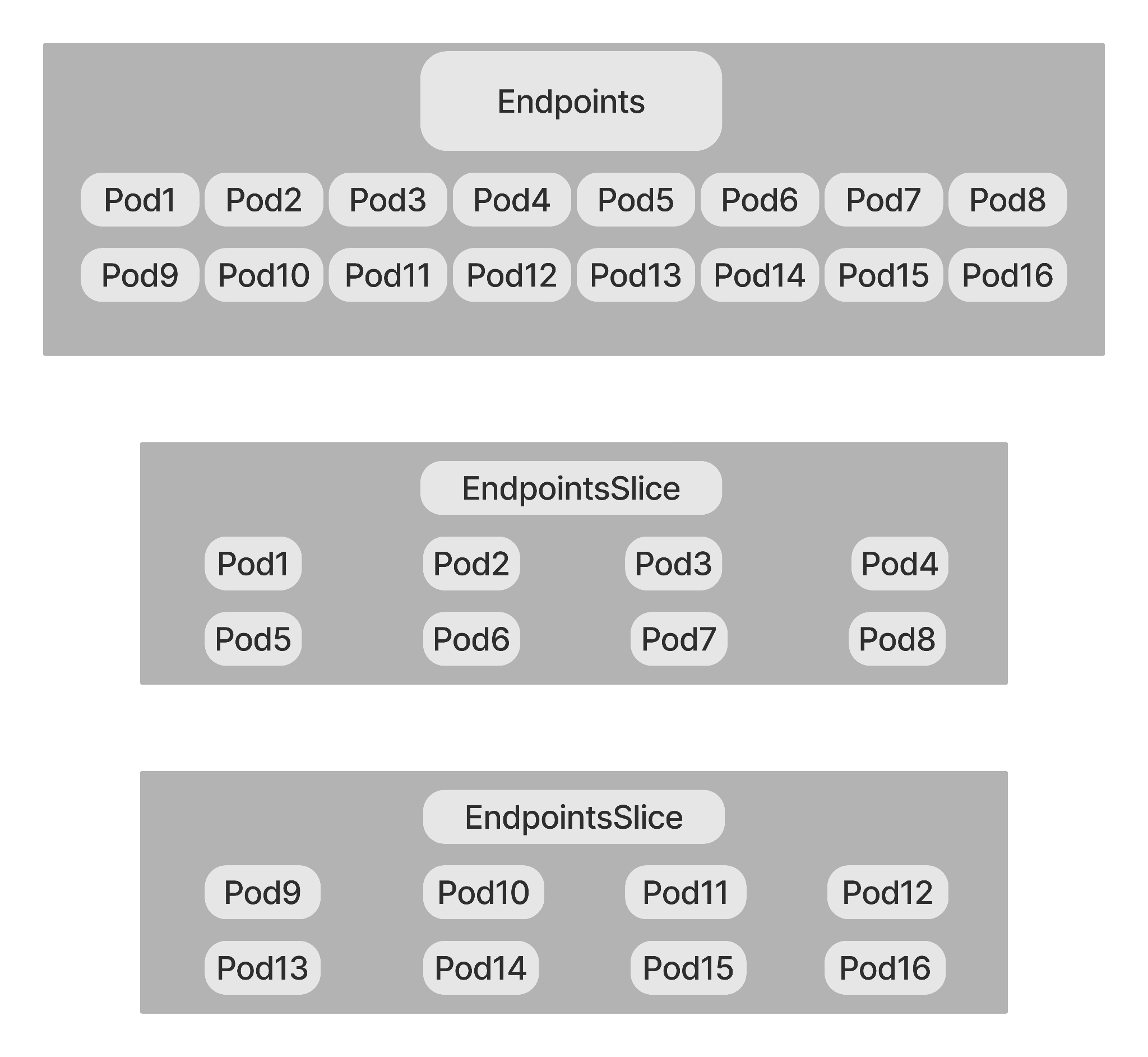
Here, you can see that an Endpoint contains all the pods in the cluster and EndpointSlices are the extensible and scalable alternative to the existing Endpoint. There is only one Endpoint resource for the whole service but there are more than one EndpointSlices for the same service. The EndpointSlices help you scale your network resources in this way. To understand how significant this scalability issue is, let us take an example.
For example, Kubernetes service has some 9,000 pods which somehow end up in 2MB Endpoint resources. A single Endpoint has all these Endpoint resources of the services. If any network endpoint changes in the endpoint, the whole resource of the endpoint needs to be distributed among each node in the cluster. When it comes to dealing with a cluster having 3000 nodes, it becomes a huge problem since a huge number of updates need to be sent to each node. Hence, when you scale more in just a single endpoint, the harder scaling the network becomes.
However, the EndpointSlices resolve this issue by enabling the Kubernetes to scale as much as needed. Instead of using a single endpoint that contains a huge list of IP addresses and their associated port numbers, use multiple EndpointSlices. These EndpointSlices are small chunks of a huge single endpoint. These slices are smaller in much, but they mitigate the load which is caused by the huge endpoint. You can store up to 100 pods in one EndpointSlice. These EndpointSlices help you distribute the service to a specific pod. If any network endpoint changes, you only need to send updates to an EndpointSlice which contains a maximum of 100 pods. All other pods in the network remain untouched.
Now, let us learn how we can create a Kubernetes EndpointSlice.
How Are EndpointSlices Created in Kubernetes?
Kubernetes EndpointSlices is the best alternative to a single endpoint in the Kubernetes cluster. It does not only help you track all the network endpoints easily and efficiently but also gives better performance compared to a single endpoint. It also shows the lower network traffic while offering scaling reliability. Moreover, using the multiple EndpointSlices allows you to put less labor on the control plane and nodes in the Kubernetes cluster.
You can have the steps that let you learn how to create the EndpointSlices in the Kubernetes cluster in the following examples.
Step 1: Start the Minikube Cluster
The first and foremost step is to ensure that the minikube cluster is active. An inactive minikube cluster will not allow you to perform any work in the Kubernetes environment, so make sure it is in active mode. To ensure that the minikube cluster is up and running, use the following command:
If your minikube cluster has not started earlier or if it is in sleep mode, this command wakes it up and gets it up and running. Now, you have an active minikube cluster. You are ready to create the EndpointSlice in your Kubernetes environment.
Step 2: Create a Deployment with the YAML File
The YAML file is most commonly used in Kubernetes to create deployments. You can use the pre-existing deployment YAML file or you can create a new one with the following command:
This creates a new YAML file named “endpoint.yaml” where you can save the deployment definition for configuration. Refer to the deployment definition in the following screenshot:
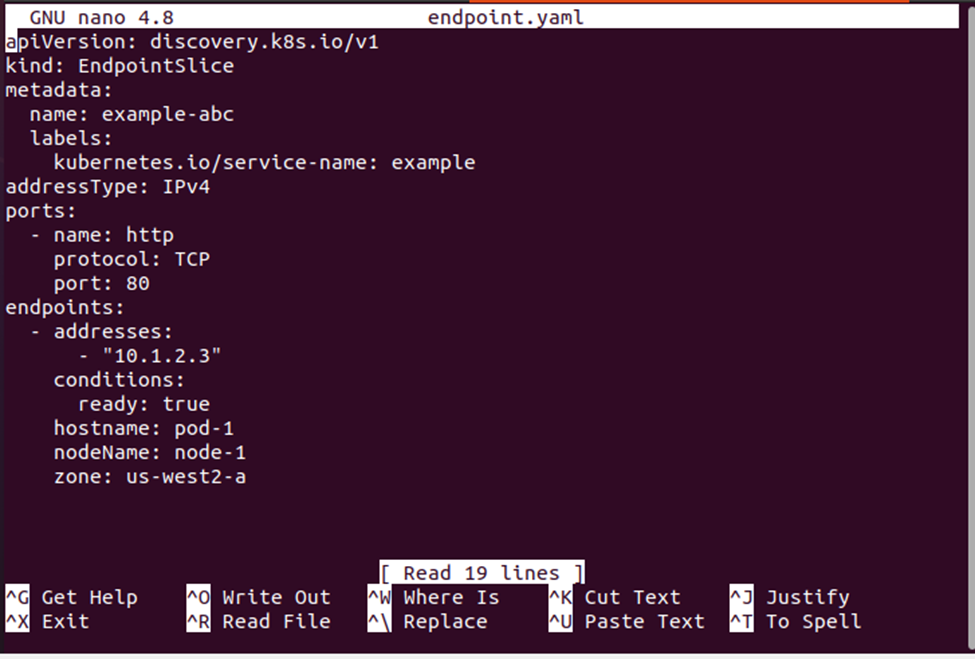
Step 3: Create the EndpointSlice Using the YAML File
Now that we have a YAML file which contains the deployment definition, we use it to create the EndpointSlices in our Kubernetes cluster. We need to deploy the configuration file so that we can have the EndpointSlices in the Kubernetes cluster. We use the following command to deploy the configuration file:
In the Kubernetes environment, resources are created using the “kubectl create” command. Hence, we use the “kubectl create” command to create the EndpointSlices from the YAML configuration file.
![]()
Conclusion
We explored the EndpointSlices in the Kubernetes environment. The EndpointSlice in Kubernetes is an object which is used to track all the network endpoints in the Kubernetes cluster. It is the best alternative to a huge and single Endpoint in the Kubernetes cluster since it allows better scalability and extensibility options. These EndpointSlices enable the Kubernetes cluster to give better performance by placing less labor on nodes and the control plane. With the help of an example, we learned how to create the EndpointSlices in the Kubernetes cluster.