Firstly, you need to create a database in the installed PostgreSQL. Otherwise, Postgres is the database that is created by default when you start the database. We will use psql to start implementation. You may use pgAdmin.
A table named “items” is created by using a create command.

To enter values in the table, an insert statement is used.

After inserting all data through the insert statement, you can now fetch all the records through a select statement.
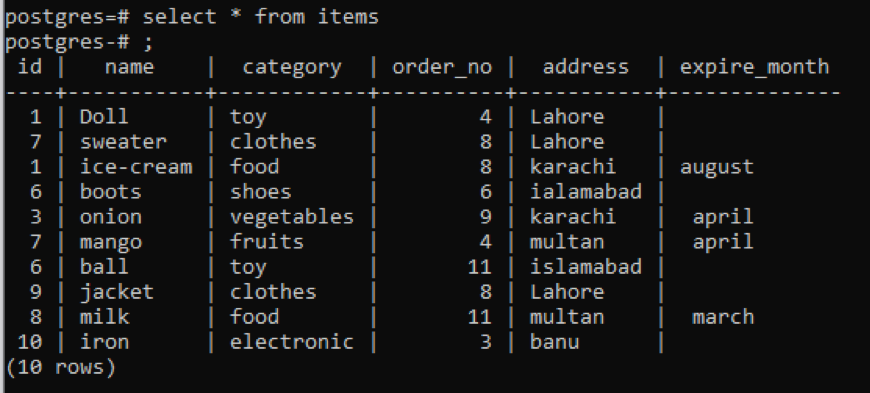
Example 1
This table, as you can see from the snap, has some similar data in each column. To distinguish the uncommon values, we will apply the “distinct” command. This query will take a single column, whose values are to be extracted, as a parameter. We want to use the first column of the table as input of the query.

From the output, you can see that the total rows are 7, whereas the table has 10 rows total, which means some rows are deducted. All the numbers in the “id” column that were duplicated twice or more are displayed only once to distinguish the resultant table from others. All the result is arranged in the ascending order by the use of “order clause”.
Example 2
This example is related to the subquery, in which a distinct keyword is used within the subquery. The main query selects the order_no from the content obtained from the subquery is an input for the main query.
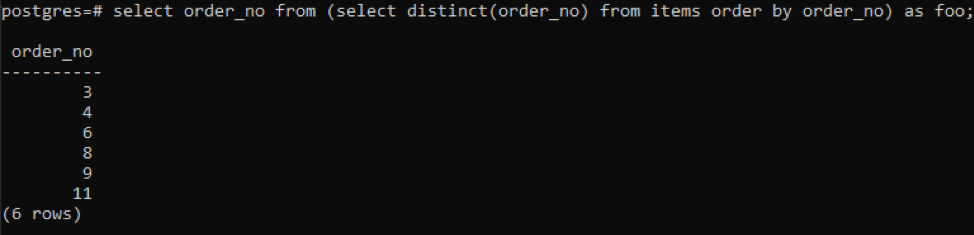
The subquery will fetch all the unique order numbers; even repeated ones are displayed one time. The same column order_no again orders the result. At the end of the query, you have noticed the use of ‘foo’. This acts as a placeholder to store the value that can change according to the given condition. You can also try without using it. But to assure the correctness, we have used this.
Example 3
To get the distinct values, here we another method to make use of. The “distinct” keyword is used with a function count (), and a clause that is “group by”. Here we have selected a column named “address”. The count function counts the values from the address column that are obtained through the distinct function. Besides the query result, if we randomly think to count the distinct values, we will come with a single value for each item. Because as the name indicates, distinct will bring the values one either they are present in numbers. Similarly, the count function will display only a single value.
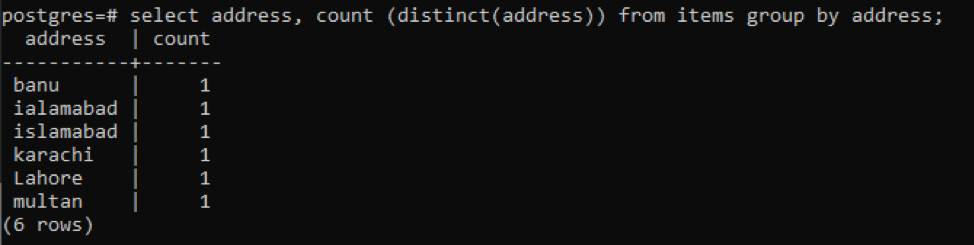
Each address is counted as a single number because of distinct values.
Example 4
A simple “group by” function determines the distinct values from two columns. The condition is that the columns you have selected for the query to display the contents must be used in the “group by” clause because the query will not work properly without that.
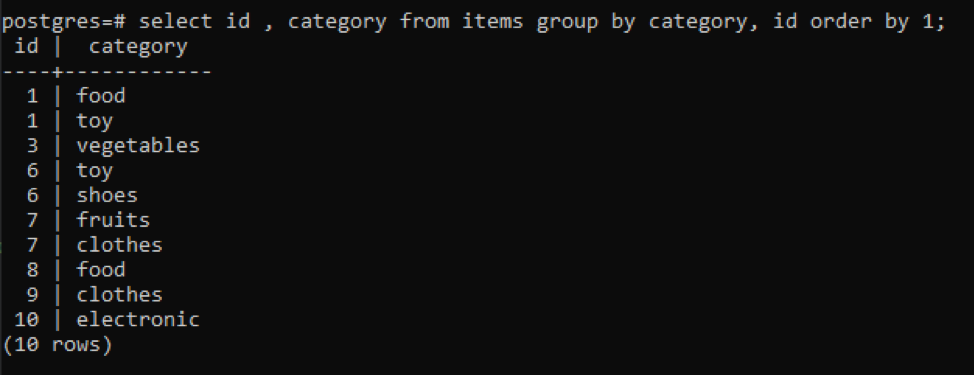
All the resultant values are organized in ascending order.
Example 5
Again consider the same table with some alteration in it. We have added a new layer to apply some constraints.

The same group by and the order by clauses is used in this example applied to two columns. Id and the order_no are selected, and both are grouped by and ordered by 1.
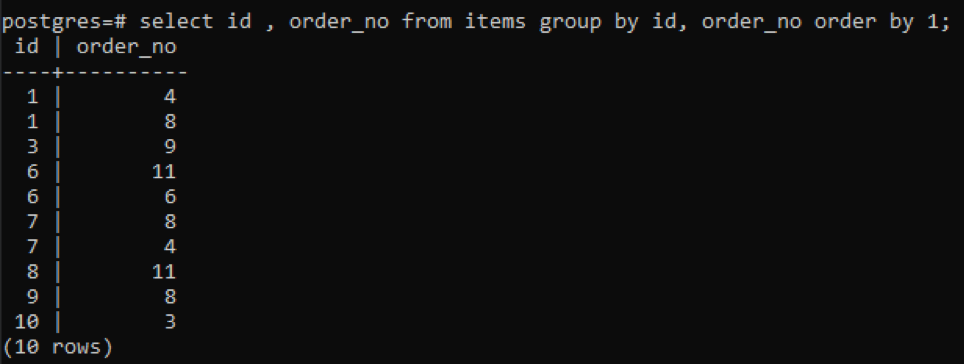
As each id has a different order number except one number that is newly added “10”, all other numbers that have twice or more presence in the table are displayed simultaneously. For instance, “1” id has order_no 4 and 8, so both are mentioned separately. But in the case of “10” id, it is written one time because both the ids and the order_no are the same.
Example 6
We have used the query as mentioned above with the count function. This will form an additional column with the resultant value to display the count value. This value is the number of times both “id,” and the “order_no” are the same.
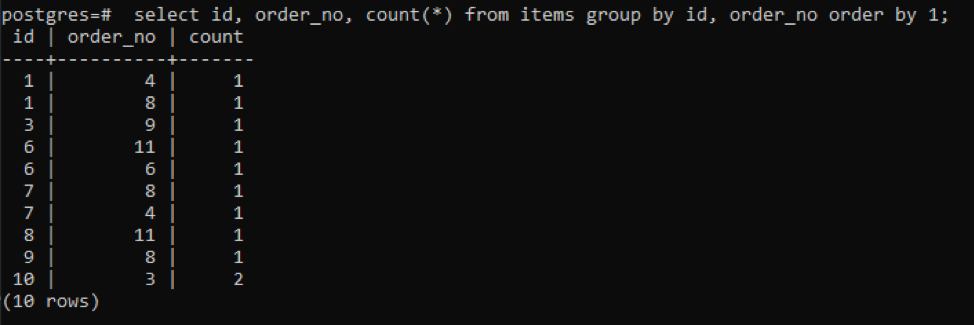
The output shows that each row has the count value of “1” as both have a single value that is dissimilar from one another except the last one.
Example 7
This example uses almost all the clauses. For instance, the select clause, group by, having clause, order by clause, and a count function are used. Using the “having” clause, we can also get duplicate values, but we have applied a condition with the count function here.

Only a single column is selected. First of all, the values of order_no that are distinct from other rows are selected, and the count function is applied to it. The resultant that is obtained after the count function is arranged in ascending order. And all the values are then compared with the value “1”. Those values of the column greater than 1 are displayed. That’s why from 11 rows, we get only 4 rows.
Conclusion
“How do I count unique values in PostgreSQL” has a separate working than a simple count function as it can be used with different clauses. To fetch the record having a distinct value, we have used many constraints and the count and distinct function. This article will guide you on the concept of counting the unique values in the relation.