Caching is the process of storing and fetching the most recent or frequently used data from the model so it does not have to be recomputed all the time. Text embeddings can be used to convert textual data into numbers and applying caching techniques to it can improve the efficiency of the model. LangChain enables the developers to build the caching model using the CacheBackedEmbeddings library.
This post will demonstrate the process of working with caching in LangChain.
How to Work With Caching in LangChain?
Caching in LangChain on text embedding models can be used through different datasets like using the vector store, In-memory data, or data from the file systems. Applying the cache methods can get the output quickly and the model can apply similarity searches on the data more effectively.
To learn the process of working with caching in LangChain, simply go through the listed steps:
Step 1: Install Modules
First, start the process of working with caching by installing the required models the first one here is LangChain which contains all the required libraries for the process:
The FAISS module is required to perform a similarity search for extracting or generating output based on the input provided by the user:
The last module for this guide that is required to install is OpenAI which can be used to create embeddings of the data using the OpenAIEmbeddings() method:
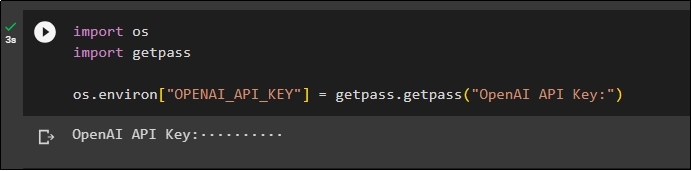
After the installation of all the modules, simply set up the environment using the API key from the OpenAI environment using the “os” and “getpass” libraries:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Step 2: Importing Libraries
Once the setup is completed, simply import the libraries for working with caching techniques in LangChain:
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
Step 3: Building Caching Model
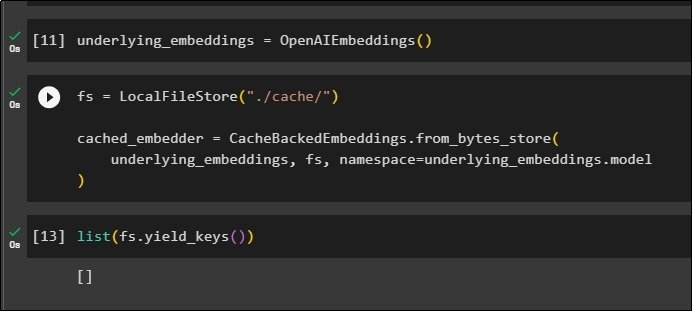
After importing the libraries, simply call the OpenAIEmbeddings() method to build the model and store it in the variable:
Now, apply cache using the LocalFileStore() method and the CacheBackedEmbeddings() methods with multiple arguments:
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, fs, namespace=underlying_embeddings.model
)
Simply get the list of embeddings and for now, the list is empty as the embeddings are not stored in the list:
Step 4: Creating Vector Store
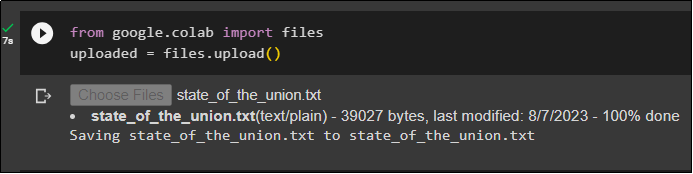
Get the file from the local system using the files library and click on the “Choose Files” after executing the code:
uploaded = files.upload()
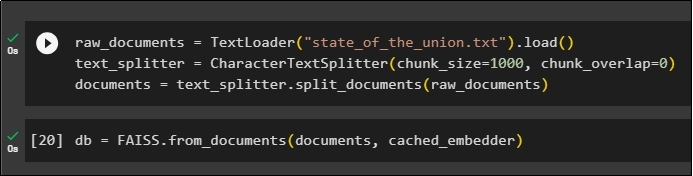
Now, simply create a vector store that can be used to store the embeddings using the TextLoader() method with the name of the document. After that, apply the text splitter methods with the size of the chunks and split the data into smaller chunks:
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
After splitting the text, store the data in the db variable using the FAISS library to get the output using the similarity search method:
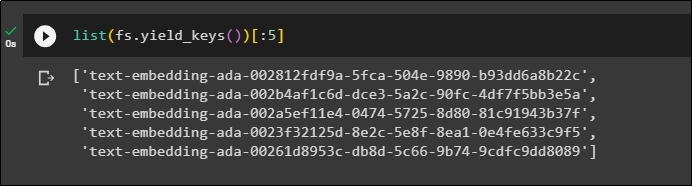
Now, again get the list of embeddings after storing them in the database and limit the output to only 5 indexes:
Step 5: Using In-Memory Caching
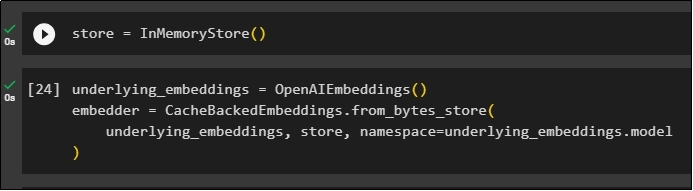
The next caching can be used through InMemoryStore() methods to define the store variable:
Build the caching model using OpenAIEmbeddings() and CacheBackedEmbeddings() methods with the model, store, and namespace as its parameters:
embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, store, namespace=underlying_embeddings.model
)
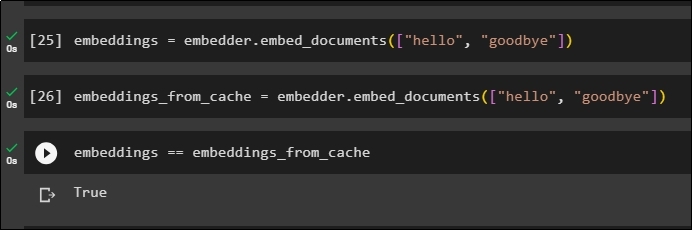
Apply embeddings on the stored document without using the cache embeddings to get data from the document:
Now, apply cache to the embeddings to quickly fetch data from the documents:
Store the cache embeddings to the embeddings variable so the embeddings variable has the cached embeddings stored:
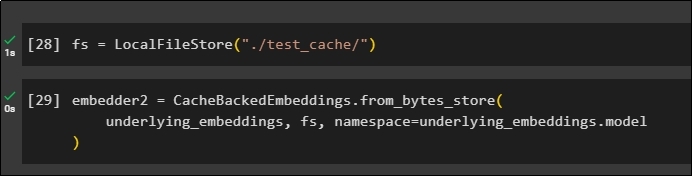
Step 6: Using File System Caching
The last method to apply caching in the embeddings from the test_cache document using the File System Store:
Apply embeddings using the CacheBackedEmbeddings() method with the embedding model, data store, and namespace as the parameters:
underlying_embeddings, fs, namespace=underlying_embeddings.model
)
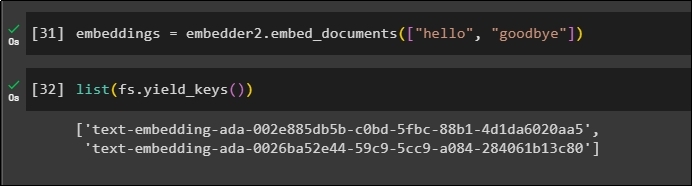
Use the embeddings variable with the cached data stored in it to call the embedder() method:
Now get the embeddings for the above two worlds mentioned as the parameters:
That is all about the process of building and working with caching in LangChain.
Conclusion
To work with caching techniques for embeddings in LangChain, simply get the required modules using the pip command like FAISS, OpenAI, etc. After that, import the libraries for building and working with caching in LangChain. It efficiently gets the embeddings stored in different stores. The developers can use multiple stores as databases to store embeddings like vector stores, File Systems, or In-memory stores. This guide demonstrated the process of working with caching in LangChain.