This guide will illustrate how to use VectorStoreRetrieverMemory using the LangChain framework.
How to Use VectorStoreRetrieverMemory in LangChain?
The VectorStoreRetrieverMemory is the library of LangChain that can be used to extract information/data from the memory using the vector stores. Vector stores can be used to store and manage data to efficiently extract the information according to the prompt or query.
To learn the process of using the VectorStoreRetrieverMemory in LangChain, simply go through the following guide:
Step 1: Install Modules
Start the process of using the memory retriever by installing the LangChain using the pip command:
Install the FAISS modules to get the data using the semantic similarity search:
Install the chromadb module for using the Chroma database. It works as the vector store to build the memory for the retriever:
Another module tiktoken is needed to install which can be utilized to create tokens by converting data into smaller chunks:
Install the OpenAI module to use its libraries for building LLMs or chatbots using its environment:
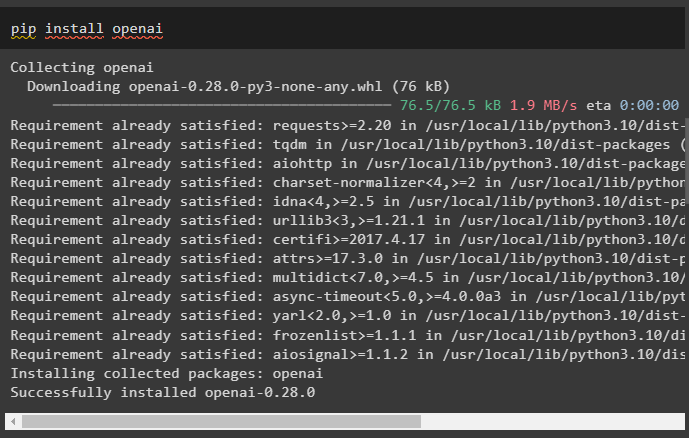
Set up the environment on the Python IDE or notebook using the API key from the OpenAI account:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Step 2: Import Libraries
The next step is to get the libraries from these modules for using the memory retriever in LangChain:
from datetime import datetime
from langchain.llms import OpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import ConversationChain
from langchain.memory import VectorStoreRetrieverMemory
Step 3: Initializing Vector Store
This guide uses the Chroma database after importing the FAISS library to extract the data using the input command:
from langchain.docstore import InMemoryDocstore
#importing libraries for configuring the databases or vector stores
from langchain.vectorstores import FAISS
#create embeddings and texts to store them in the vector stores
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {})
Step 4: Building Retriever Backed by a Vector Store
Build the memory to store the most recent messages in the conversation and get the context of the chat:
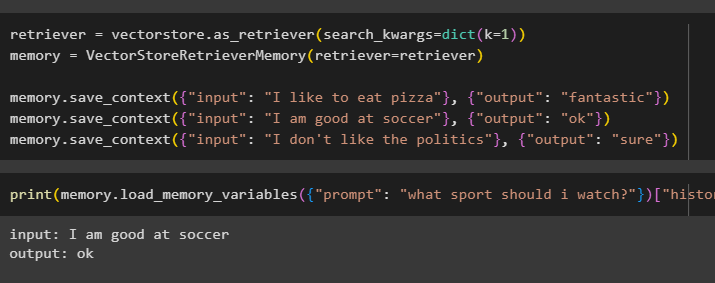
memory = VectorStoreRetrieverMemory(retriever=retriever)
memory.save_context({"input": "I like to eat pizza"}, {"output": "fantastic"})
memory.save_context({"input": "I am good at soccer"}, {"output": "ok"})
memory.save_context({"input": "I don't like the politics"}, {"output": "sure"})
Test the memory of the model using the input provided by the user with its history:
Step 5: Using Retriever in a Chain
The next step is the use of a memory retriever with the chains by building the LLM using the OpenAI() method and configuring the prompt template:
_DEFAULT_TEMPLATE = """The is an interaction among a human and a machine
The system produces useful information with details using context
If the system does not have the answer for you, it simply says i don’t have the answer
Important information from conversation:
{history}
(if the text is not relevant don’t use it)
Current chat:
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
#configure the ConversationChain() using the values for its parameters
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
memory=memory,
verbose=True
)
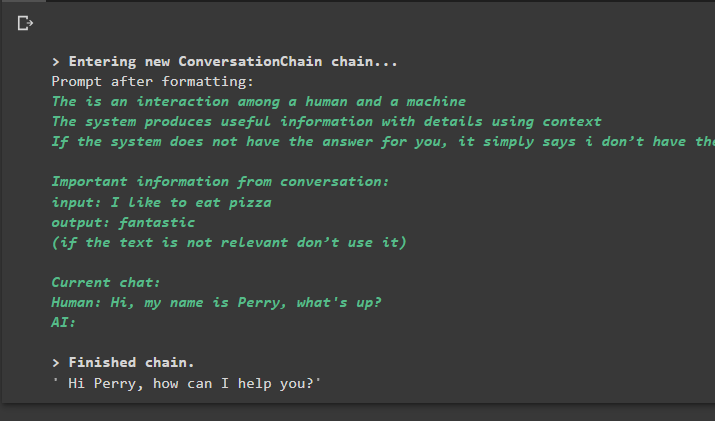
conversation_with_summary.predict(input="Hi, my name is Perry, what's up?")
Output
Executing the command runs the chain and displays the answer provided by the model or LLM:
Get on with the conversation using the prompt based on the data stored in the vector store:
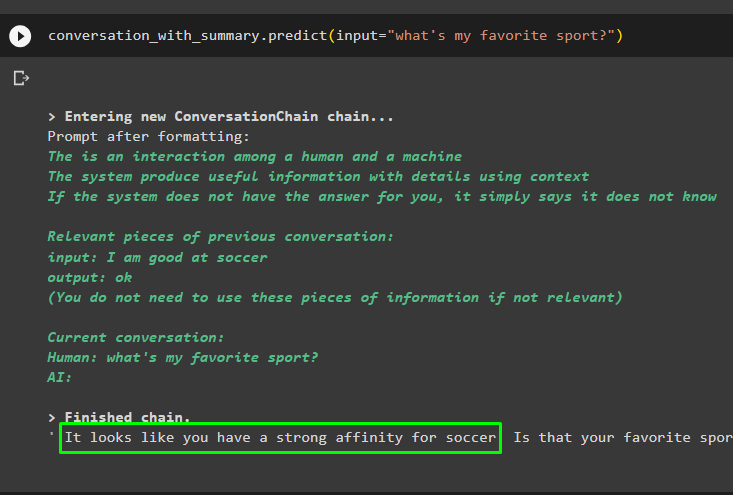
The previous messages are stored in the model’s memory which can be used by the model to understand the context of the message:
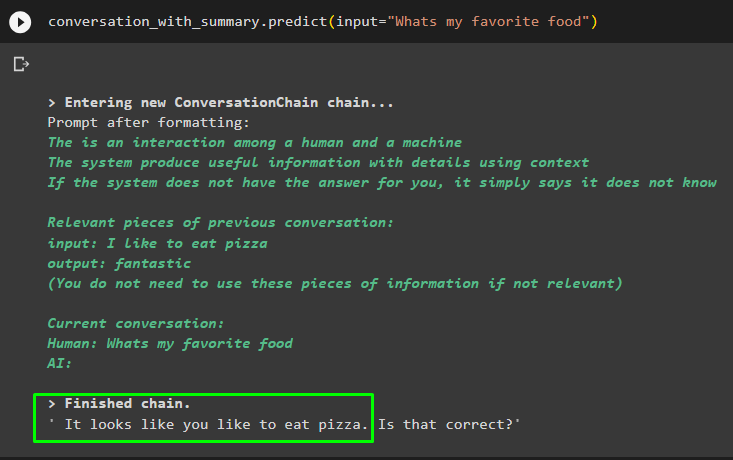
Get the answer provided to the model in one of the previous messages to check how the memory retriever is working with the chat model:
The model has correctly displayed the output using the similarity search from the data stored in the memory:
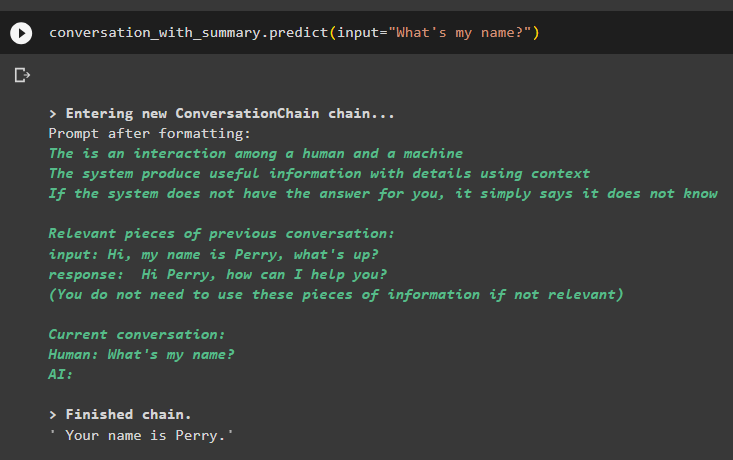
That’s all about using the vector store retriever in LangChain.
Conclusion
To use the memory retriever based on a vector store in LangChain, simply install the modules and frameworks and set up the environment. After that, import the libraries from the modules to build the database using Chroma and then set the prompt template. Test the retriever after storing data in the memory by initiating the conversation and asking questions related to the previous messages. This guide has elaborated on the process of using the VectorStoreRetrieverMemory library in LangChain.