
Python contains a module named urllib for handling Uniform Resource Locator (URL)-related tasks. This module is installed in Python 3 by default, and fetches URLs of different protocols via the urlopen() function. Urllib can be used for many purposes, such as reading website content, making HTTP and HTTPS requests, sending request headers, and retrieving response headers. The urllib module contains many other modules for working with URLs, such as urllib.request, urllib.parse, and urllib.error, among others. This tutorial will show you how to use the Urllib module in Python.
Example 1: Opening and reading URLs with urllib.request
The urllib.request module contains the classes and methods required to open and read any URL. The following script shows how to use urllib.request module to open a URL and to read the content of the URL. Here, the urlopen() method is used to open the URL, “https://www.linuxhint.com/.” If the URL is valid, then the content of the URL will be stored in the object variable named response. The read() method of the response object is then used to read the content of the URL.
# Import request module of urllib
import urllib.request
# Open the specific URL for reading using urlopen()
response = urllib.request.urlopen('https://www.linuxhint.com/')
# Print the response data of the URL
print("The output of the URL is:\n\n",response.read())
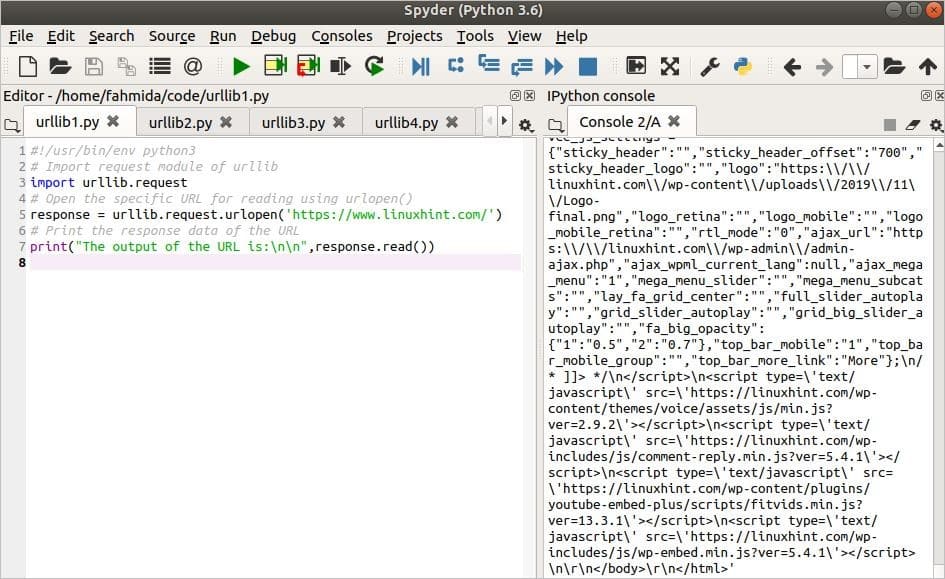
Output
The following output will appear after running the script.
Example 2: Parsing and unparsing URLs with urllib.parse
The urllib.parse module is primarily used to split apart or join together the different components of a URL. The following script shows different uses of the urllib.parse module. The four functions of urllib.parse used in the following script include urlparse, urlunparse, urlsplit, and urlunsplit. The urlparse module works like urlsplit, and the urlunparse module works like urlunsplit. There is only one difference between these functions; that is, urlparse and urlunparse contain an extra parameter named ‘params’ for splitting and the joining function. Here, the URL ‘https://linuxhint.com/play_sound_python/‘ is used for splitting and joining the URL.
# Import parse module of urllib
import urllib.parse
# Parsing URL using urlparse()
urlParse = urllib.parse.urlparse('https://linuxhint.com/play_sound_python/')
print("\nThe output of URL after parsing:\n", urlParse)
# Joining URL using urlunparse()
urlUnparse = urllib.parse.urlunparse(urlParse)
print("\nThe joining output of parsing URL:\n", urlUnparse)
# Parsing URL using urlsplit()
urlSplit = urllib.parse.urlsplit('https://linuxhint.com/play_sound_python/')
print("\nThe output of URL after splitting:\n", urlSplit)
# Joining URL using urlunsplit()
urlUnsplit = urllib.parse.urlunsplit(urlSplit)
print("\nThe joining output of splitting URL:\n",urlUnsplit)
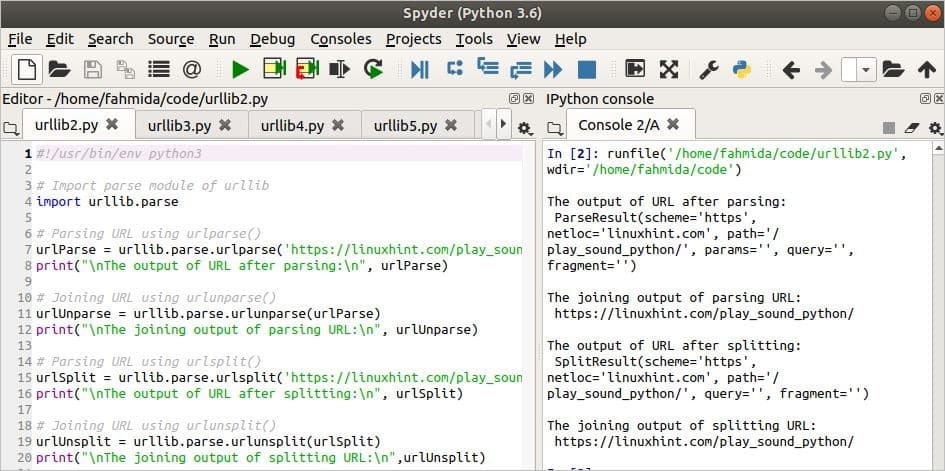
Output
The following four outputs will appear after running the script.
Example 3: Reading response header of HTML with urllib.request
The following script shows how the different parts of the response header of the URL can be retrieved via the info() method. The urllib.request module used to open the URL, ‘https://linuxhint.com/python_pause_user_input/,’ and the header information of this URL is printed via the info() method. The next part of this script will show you how to read each part of the header separately. Here, the Server, Date, and Content-Type values are printed separately.
# Import request module of urllib
import urllib.request
# Open the URL for reading
urlResponse = urllib.request.urlopen('https://linuxhint.com/python_pause_user_input/')
# Reading response header output of the URL
print(urlResponse.info())
# Reading header information separately
print('Response server = ', urlResponse.info()["Server"])
print('Response date is = ', urlResponse.info()["Date"])
print('Response content type is = ', urlResponse.info()["Content-Type"])
Output
The following output will appear after running the script.

Example 4: Reading URL responses line by line
A local URL address is used in the following script. Here, a testing HTML file named test.html is created in the location, var/www/html. The content of this file is read line by line via the for loop. The strip() method is then used to remove the space from both sides of each line. You may use any HTML file from the local server to test the script. The content of the test.html file used in this example is given below.
test.html:
<body>
Testing Page
<body>
</html>
#!/usr/bin/env python3
# Import urllib.request module
import urllib.request
# Open a local url for reading
response = urllib.request.urlopen('http://localhost/test.html')
# Read the URL from response
print ('URL:', response.geturl())
# Read the response text line by line
print("\nReading content:")
for line in response:
print(line.strip())
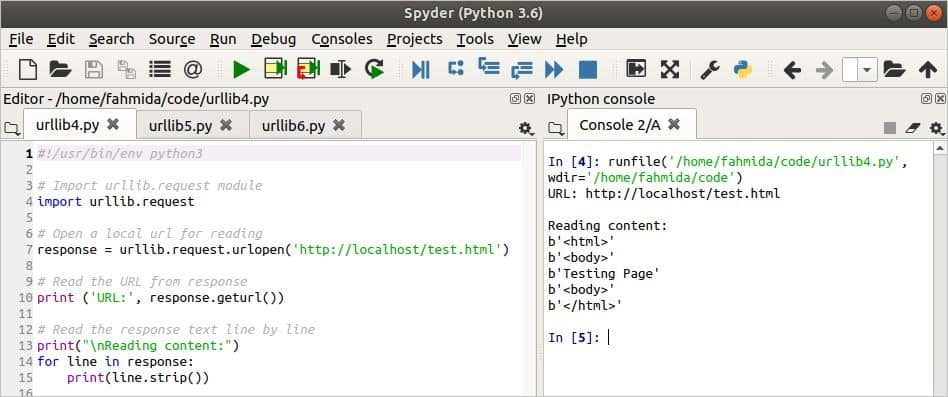
Output
The following output will appear after running the script.
Example 5: Exception handling with urllib.error.URLError
The following script shows how to use the URLError in Python via the urllib.error module. Any URL address can be taken as an input from the user. If the address does not exist, then an URLError exception will be raised and the reason for the error will print. If the value of the URL is in an invalid format, then a ValueError will be raised and the custom error will print.
# Import necessary modules
import urllib.request
import urllib.error
# try block to open any URL for reading
try:
url = input("Enter any URL address: ")
response = urllib.request.urlopen(url)
print(response.read())
# Catch the URL error that will generate when opening any URL
except urllib.error.URLError as e:
print("URL Error:",e.reason)
# Catch the invalid URL error
except ValueError:
print("Enter a valid URL address")
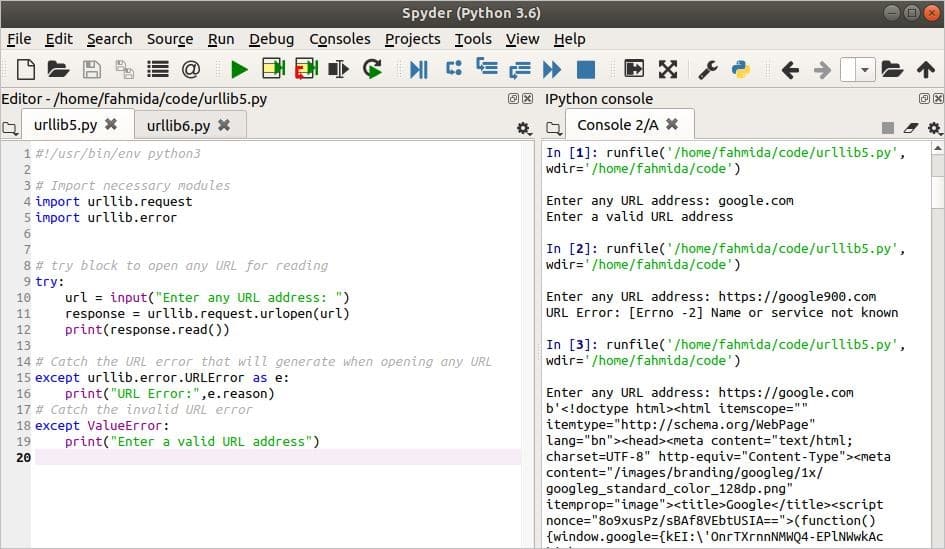
Output
The script is executed three times in the following screenshot. In the first iteration, the URL address is given in an invalid format, generating a ValueError. The URL address given in the second iteration does not exist, generating a URLError. A valid URL address is given in the third iteration, and so the content of the URL is printed.
Example 6: Exception handling with urllib.error.HTTPError
The following script shows how to use the HTTPError in Python via the urllib.error module. An HTMLError generates when the given URL address does not exist.
# Import necessary modules
import urllib.request
import urllib.error
# Take input any valid URL
url = input("Enter any URL address: ")
# Send request for the URL
request = urllib.request.Request(url)
try:
# Try to open the URL
urllib.request.urlopen(request)
print("URL Exist")
except urllib.error.HTTPError as e:
# Print the error code and error reason
print("Error code:%d\nError reason:%s" %(e.code,e.reason))
Output
Here, the script is executed two times. The first URL address taken as the input exists and the module has printed a message. The second URL address taken as the input does not exist and the module has generated the HTTPError.

Conclusion
This tutorial discussed many important uses of the urllib module by using various examples to help the readers to know the functions of this module in Python.