This guide will explain the process of using the vector stores in LangChain.
How to Use Vector Stores in LangChain?
To use the vector stores in LangChain, simply follow this guide with easy steps:
Example 1: Using Vector Stores in LangChain
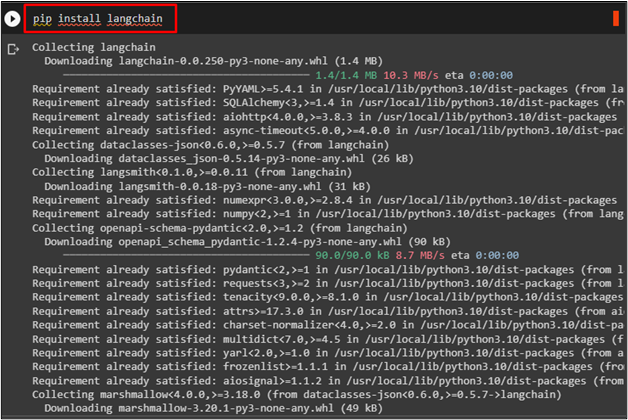
Start the process of using the vector stores in LangChain by installing the framework using the following code:
The following screenshot displays the successful installation of the LangChain framework:
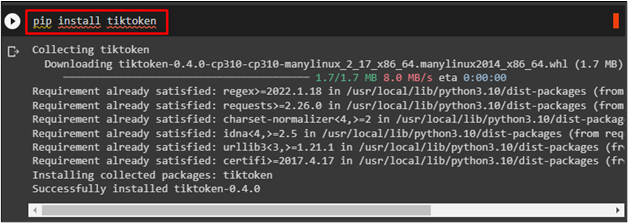
After that, install the “tiktoken” tokenizer using this command:
Using Chroma Vector Database
This guide uses the Chroma database vector to create and use the vector stores in LangChain:
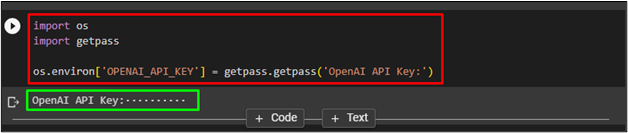
Now, import the “os” and “getpass” libraries to use OpenAI. It is because of an API key from the OpenAI platform:
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
Use the following code to upload data on the Google Collaboratory from the local system:
upload = files.upload()

Split Data Using Tokenizer
After importing the data, simply split the data using the “CharacterTextSplitter” function inside the Chroma vector database:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
raw_documents = TextLoader('Data.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=5, chunk_overlap=1)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
The Data.txt is loaded using the “TextLoader” function that is uploaded in the previous step that is used to store in the vector store:
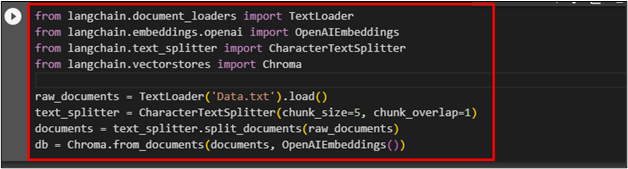
Querying Vector Stores
After splitting the text, use the query to get data from the vector stores:
docs = db.similarity_search(query)
print(docs[0].page_content)
Running the above code displays the result from the data as displayed in the screenshot below:

Example 2: Embedding the Vector Stores
To apply embedding on the vector stores, use the OpenAIEmbedding function. Then, simply use a similarity search on the embedding vector to get the data:
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
The following screenshot displays the embedding is applied in the vector space to fetch data:
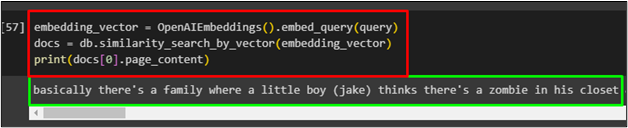
Example 3: Create Index in Vector Stores
To create indexes and a class, use the following command after importing libraries. For instance, the class name “BaseRetriever” is used by passing the “ABC” value:
from typing import Any, List
from langchain.schema import Document
from langchain.callbacks.manager import Callbacks
class BaseRetriever(ABC):
...
def get_relevant_documents(
self, query: str, *, callbacks: Callbacks = None, **kwargs: Any
) -> List[Document]:
async def aget_relevant_documents(
self, query: str, *, callbacks: Callbacks = None, **kwargs: Any
) -> List[Document]:
...
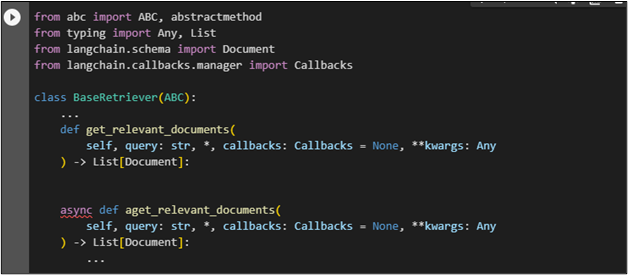
The following code block imports libraries to retrieve data using question/answering and OpenAI libraries:
from langchain.llms import OpenAI
Load text or document using the TextLoader from LangChain:
loader = TextLoader('Data.txt', encoding='utf8')
Import library to create indexes in the vector spaces and retrieve data from the indexes:
Create an index using the following code and load data in the index using the loader variable:
Query the data using the following code to get data using the index:
index.query(query)
The following screenshot displays the data retrieved according to the query:
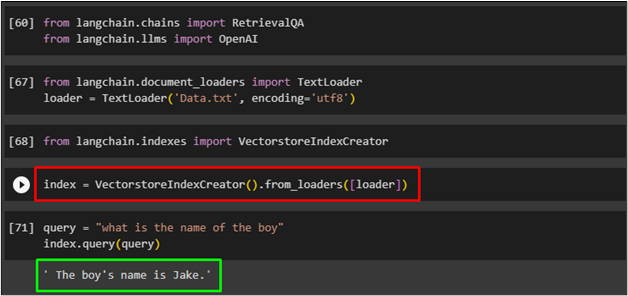
That is all about the process of using the vector stores in LangChain.
Conclusion
To use a vector store in LangChain, simply install LangChain and the required frameworks to get started with the process. This guide uses the Chroma vector database and then uploads data into small chunks in the vector store. After that, embedding and index creation are used to get data from the dataset, and to get answers from the query, respectively. This post demonstrated the process of using vector spaces in the LangChain framework.