Data is a vital part of building efficient artificial intelligence models and it becomes difficult to manage and operate. Vector stores in LangChain are used to place and manage huge data which can be used to train artificial intelligence models. The user can always retrieve these documents or data using vector store-backed retrievers like Maximum Marginal Relevance and similarity score search.
This post demonstrates the process of using vector store-backed retrievers in LangChain.
How to Use Vector Store-Backed Retrievers in LangChain?
To use a vector store-backed retriever in LangChain, simply follow this guide with multiple methods:
Prerequisite: Install Libraries and Upload Data
Before starting the process of using retrievers, simply install LangChain using the following code:
Install the Chroma vector database using the following code which can be used to work with vector stores:
Install the OpenAI library using this code which can be used to embed the data:
Install the FAISS library which is used to efficiently search using the following code:
After that, import the os module and use the “getpass()” method to provide the OpenAI API key:
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
The following screenshot displays the successful installation of the FAISS library and successful usage of the OpenAI API key:
Upload Data
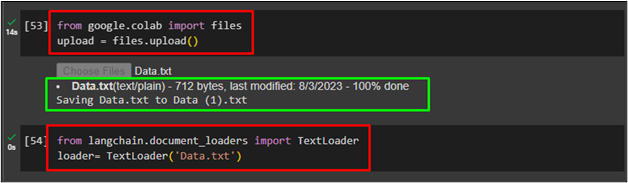
After installing all the necessary modules and libraries, simply upload data from the local system using the following code:
upload = files.upload()
After that, load data in the loader variable using TextLoader() function and the “Data.text” is the data uploaded from the system to be stored in the vector store:
loader= TextLoader('Data.txt')
The following screenshot displays that the data is successfully uploaded:
Method 1: Using a Simple Retriever
Use the following code to import necessary libraries such as CharacterTextSplitter, FAISS, and OpenAIEmbedding to retrieve data from the vector stores. CharacterTextSplitter is used to split data into small chunks, OpenAI embedding is used to embed the data, and FAISS is used to efficiently search to retrieve data:
#Character Text Splitter library to split text in small chunks
from langchain.vectorstores import FAISS
#FAISS library to search data from vector stores
from langchain.embeddings import OpenAIEmbeddings
#OpenAIEmbedding library to embed the data afer splitting
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
#Configure text splitting to create chunks of 100 characters
texts = text_splitter.split_documents(documents)
#Embedding after splitting using OpenAIEmbedding
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(texts, embeddings)
After creating the database or db variable, simply use it to make a retriever using the following code:
![]()
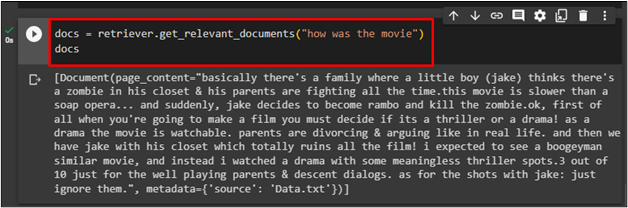
Now, the user can apply the retriever to input command and then display it on the screen:
docs
The following screenshot displays the data retrieved from the docs’ variable:
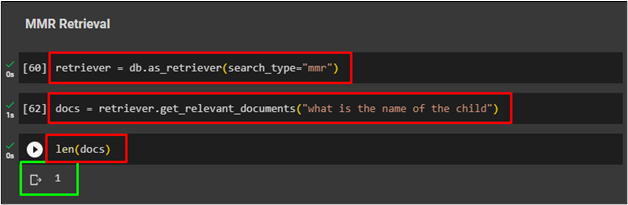
Method 2: Using Maximum Marginal Relevance Retriever
Now use the MMR retriever which is a vector store-backed retriever to get data using the following command:
Using the same variable docs to use the retriever using the command:
After that, simply check the length of retrieved documents from the docs’ variable:
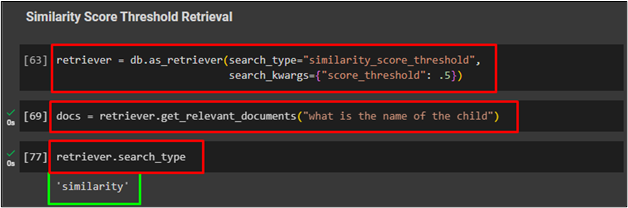
Method 3: Using Similarity Score Threshold Retriever
The second vector store-backed retriever is the similarity score threshold to retrieve documents:
search_kwargs={"score_threshold": .5})
Use the following code to use the input command in the retriever which is using the similarity score threshold vector store-based retriever:
The following code is used to get the type of retriever used to fetch data from the document:
The following screenshot displays the type of search used to get data from documents:
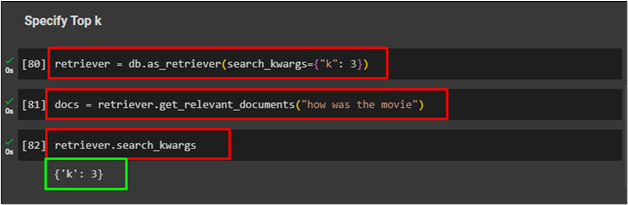
Method 4: Using Top K Search
Another retriever that is used to fetch data from the vector stores is kwargs search with the value of key as mentioned in the following code:
Use the following code to provide the input command using the search_kwargs retriever:
Use the following command to check the value of the K in kwargs retriever:
That’s all about using different vector store-backed retrievers in LangChain.
Conclusion
To use the vector store-backed retriever in LangChain, simply install the LangChain, Chroma, FAISS, and OpenAI framework. There are a couple of vector store-backed retrievers such as MMR and SST to fetch data from the vector stores. This guide demonstrated the process of using both the vector store-backed retrievers and another retriever that is not a vector store-backed retriever.