In this blog, we will discuss how to use the “torch.no_grad” method in PyTorch.
What is the “torch.no_grad” Method in PyTorch?
The “torch.no_grad” method is used for the management of context within the PyTorch developmental framework. Its purpose is to stop the calculation of gradients for the connection between subsequent layers of the deep learning model. The usefulness of this method is when gradients are not required in a particular model then, they can be disabled to allocate more hardware resources for the processing of the training loop of the model.
How to Use the “torch.no_grad” Method in PyTorch?
Gradients are calculated within the backward pass in PyTorch. By default, PyTorch has automatic differentiation activated for all machine learning models. The deactivation of gradient computation is essential for developers who do not have sufficient hardware processing resources.
Follow the steps below to learn how to use the “torch.no_grad” method to disable the calculation of gradients in PyTorch:
Step 1: Launch the Colab IDE
Google Colaboratory is an excellent choice of platform for the development of projects using the PyTorch framework because of its dedicated GPUs. Go to the Colab website and open a “New Notebook” as shown:
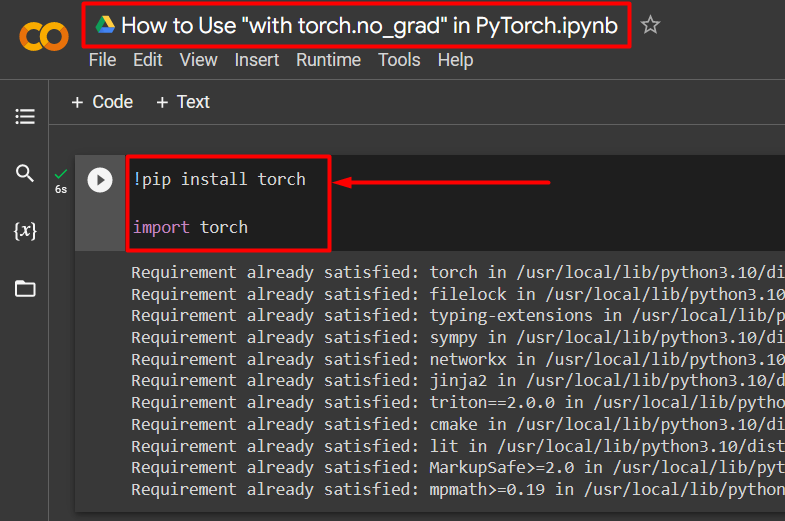
Step 2: Install and Import the Torch Library
All the functionality of PyTorch is encapsulated by the “torch” library. Its installation and import are essential before starting work. The “!pip” installation package of Python is used to install libraries and it is imported into the project using the “import” command:
import torch
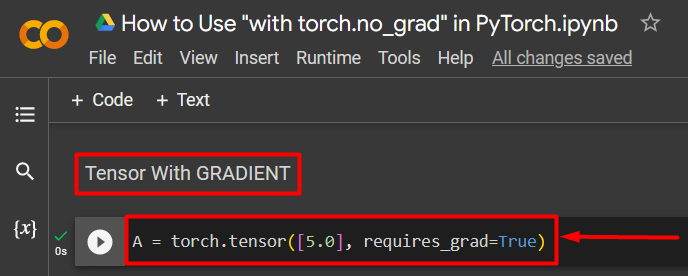
Step 3: Define a PyTorch Tensor with a Gradient
Add a PyTorch tensor to the project using the “torch.tensor()” method. Then, give it a valid gradient using the “requires_grad=True” method as shown in the code below:
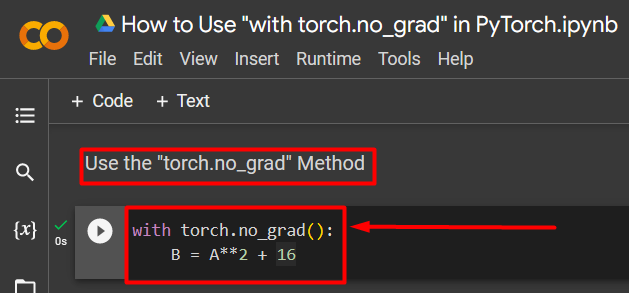
Step 4: Use the “torch.no_grad” Method to Remove the Gradient
Next, remove the gradient from the previously defined tensor using the “torch.no_grad” method:
B = A**2 + 16
The above code works as follows:
- The “no_grad()” method is used inside a “with” loop.
- Every tensor contained within the loop has its gradient removed.
- Lastly, define a sample arithmetic calculation using the previously defined tensor and assign it to the “B” variable as shown above:
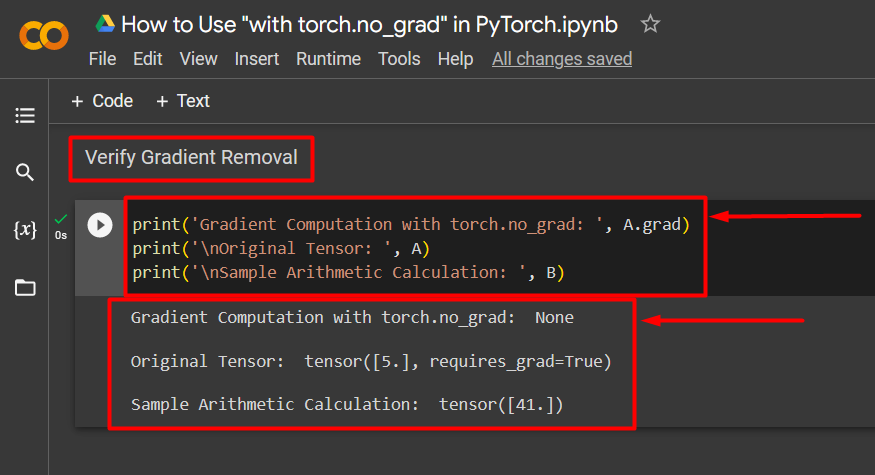
Step 5: Verify the Gradient Removal
The last step is to verify what was just done. The gradient from tensor “A” was removed and it must be checked in the output using the “print()” method:
print('\nOriginal Tensor: ', A)
print('\nSample Arithmetic Calculation: ', B)
The above code works as follows:
- The “grad” method gives us the gradient of tensor “A”. It shows none in the output below because the gradient has been removed using the “torch.no_grad” method.
- The original tensor still shows that it has its gradient as seen from the “requires_grad=True” statement in the output.
- Lastly, the sample arithmetic calculation shows the result of the equation defined previously:
Note: You can access our Colab Notebook at this link.
Pro-Tip
The “torch.no_grad” method is ideal where the gradients are not needed or when there is a need to reduce the processing load on the hardware. Another use of this method is during inference because the model is only used for making predictions based on new data. Since there is no training involved, it makes complete sense to simply disable the calculation of gradients.
Success! We have shown you how to use the “torch.no_grad” method to disable gradients in PyTorch.
Conclusion
Use the “torch.no_grad” method in PyTorch by defining it inside a “with” loop and all tensors contained within will have their gradient removed. This will bring improvements in processing speeds and prevent the accumulation of gradients within the training loop. In this blog, we have showcased how this “torch.no_grad” method can be used to disable the gradients of selected tensors in PyTorch.