
Installing Textract in Linux
You can install textract in Linux from the pip package manager. You can install pip package manager in Ubuntu by running the command below:
Once you have pip manager installed, run the following command to install dependencies for Textract:
Now use pip package manager to install Textract in Ubuntu:
You can install pip package manager in other Linux distributions from the package manager. Alternatively, you can install pip package manager in Linux by following official installation instructions available here. Once the pip package manager is installed, you can either use the pip command specified above or follow further installation instructions available in the official documentation of Textract (only for Linux distributions other than Ubuntu).
Extracting Text from Files
According to the official documentation of Textract, you can use it to extract text from following file formats:

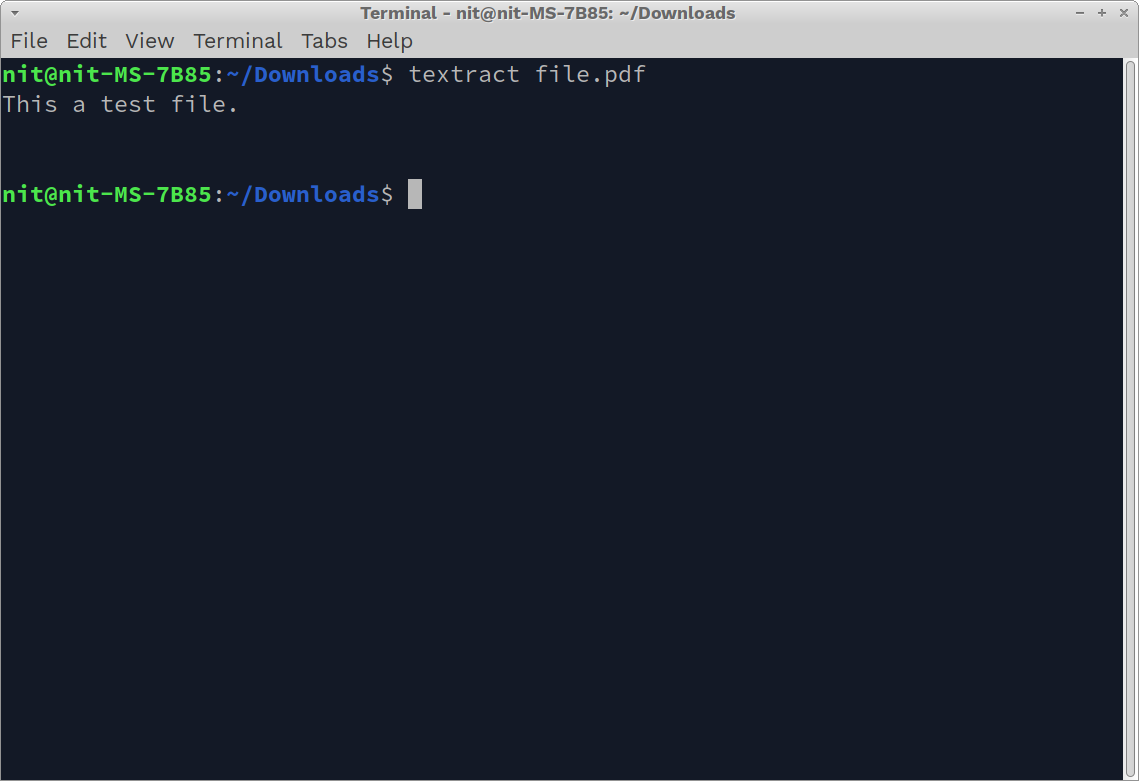
To extract text from any of these supported files and show the output as stdout in terminal, run a command in the following format:
You can replace “file.pdf” with any other file format supported by Textract. Depending on the contents of a file, you should see some output similar to this:
To save the extracted output in another file, run a command in the following format:
You can replace the file names as needed. The “-o” switch is used to specify the name of the output file where extracted text will be stored.
Textract automatically detects file extension type and uses appropriate technology to parse and extract file contents. So to detect and extract text from an image file, you can just use the above mentioned command and supply a supported image file type as an argument. As long as you use the supported file type and correctly specify the filename with extension on the command line, Textract will do all the work for you. For instance, to extract text content from a “PNG” or an “OGG” file, you can simply run these commands:
$ textract file.ogg -o file.txt
To know more about Textract command line usage, run the following command:
Using Textract as a Python Module
You can use Textract in a Python program starting with following code sample:
text = textract.process("file.png")
print (text)
The first statement imports the main textract module. Next, the “process” method is called by supplying it a file name as an argument. Like the command line utility, the process method automatically detects the current file type using its extension name and then uses an appropriate content parser and extractor suitable for the file extension.
You can also manually override file extension using “extension” argument. Here is a code sample:
text = textract.process("file.ogg", extension="ogg")
print (text)
If you want to manually override an automatic extraction method used by Textract, you can use the “method” argument (as shown in the code sample below):
text = textract.process("file.ogg", method="sox")
print (text)
Supported file types and extraction methods are listed here.
To know more about Textract Python methods and their usage, you can view the API documentation available here.
Conclusion
Textract provides a single unified command line interface and Python API for extracting text from a number of different file types. You can even use it to extract content from media files. It is especially suitable in cases where you don’t want to go through a multitude of different command line utilities to handle text extraction and want to use a single API for everything.