
The function of grep is to search the text and apply conditions to them. It is used for searching in more than one file. Grep can identify the text lines in it and decide further to apply different actions which include recursive function or inverse the search and display the line number as output etc. Special characters are the regular expressions used in commands to perform several actions like #, %, *, &, $, @, etc. In this article, we will use special characters. Grep allows the arguments as strings which are specified as a regular expression. It also has the ability to replace a word or a phrase in it. Special characters are not only used as a filename but also as data present inside the file.
Prerequisite
To execute it, we need to have the Linux operating system. For Linux to run, we must have a virtual box pre-installed. After the successful installation of Linux, you will configure it by providing some useful information. The next step is to enter Ubuntu Linux’s homepage. By providing the username and password, you will be able to access all applications —typectrl+alt+t to open the terminal.
Using “$”
To understand the concept of the “$” special character in the grep command, you need to have a file named file21.txt. “$” is used to display all the lines having a character defined behind the “$” which is a semicolon, i.e., ‘;$’. We can show all relevant content using the cat command.

Now, we will use the character in the following command to understand how it works. “-e” helps display the accurate match in the file.

The above output shows all the lines in the file having a semicolon “;” at the end. The respective result is highlighted against each line.
Using ‘ ‘
This is a simple example of a regular expression. In any grep statement, single quotes are used when we want to match any word inside a file. Similarly, we have mentioned this example to make it precise and quite understandable for the user.
The output will contain all the sentences containing the word Aqsa in it since we searched this word in the command.

Using []
The square brackets are used to mention the word that is to be searched between the two pairs of square brackets. These square brackets are followed by the “*” in the command. Moreover, we have used –n –I –w –e in the command to get the output with the line number accurately, ignoring the case sensitivity, and get the accurate match that has occurred more than once in a file. We are going to use a file fileg.txt to display the data present in it. –E is used as an extended regular expression whenever we use any character in the command.

We will now apply the following query.

Where fileg.txt is a concerned file. The output shows the word “the” wherever it is present in the file along with the line number. Only the word is displayed but not the whole sentence because we have used –w and –e to display its occurrence and show accuracy.
Using ‘-‘
‘-‘ is used in the command to find a match in the file. –niw again represents the same meaning as described in the example mentioned above. –m shows the first line containing the word in the existing file.

The output shows the lines containing the word technical. The line number that has the word ‘technical’ is also displayed which is in 1 and 4.
Using “|”
This special character is used in many ways. In general, it is used as an OR operator to make an option between the two given names. In a grep command, it is used to operate so that it will fetch the record of either one or both words separated by “|”. Here, the example shows the fetching of two words present in all the files of the directory.
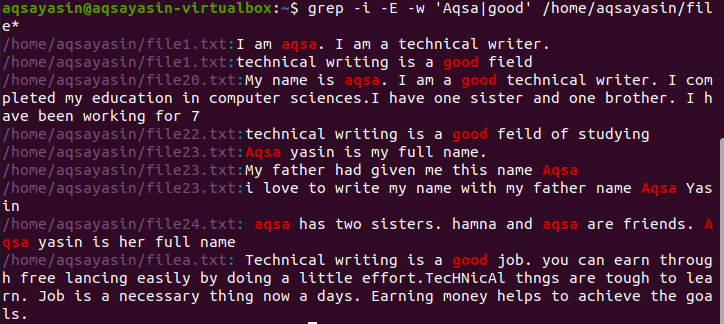
Now, the output shows both words present either in a single file or different files. As we have mentioned in the directory, we will get filenames as well.
Using ‘^()’
Here ‘^()’ act recursively compared to the above example.“^” shows only one of the two given options, i.e., Aqsa and good, that comes first in any file. The output will contain only Aqsa. Egrep is an extended regular expression.
![]()
Using ^$
It shows the matching of blank/empty strings at the end of a line. If any gap is present within the text, it is fetched by the following command.
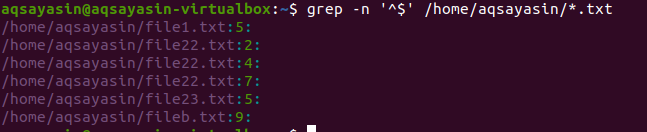
All text files will be searched. The output will contain filenames and also the line number that contains the blank space in the file. We have used –n in the command.

Using [] {}
These two parentheses show how special characters work. [] contains the word to be searched. At the same time, {} describe the matching in file N times. In the proceeding example, we have used {2}, which shows the occurrence of all two possible words of the provided word in the command that is “the”.

Conclusion
In the article as mentioned earlier, we have discussed some basic examples to explain the concept of special characters in a command. We created the file and then fetched the data present in it by using the grep command. I hope after reading this article, you will be familiar with the special characters we have used in our article.