This guide will demonstrate the process of using Pinecone in LangChain.
How to Use Self-Querying With Pinecone in LangChain?
To use the self-query with Pinecone in LangChain, simply follow this simple and easy guide:
Step 1: Install Prerequisite Modules
The first step to use the self-query is to install the LangChain framework to use its resources:
Install OpenAI modules to access the OpenAIEmbedding library and its functions:
Install the tiktoken tokenizer to split the text into small chunks to create a model:
Now, install the “lark” module with the “pinecone-client” for accessing its indexes:
After installing all the necessary modules, simply connect to the OpenAI using its API key:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Step 2: Create Pinecone Index
After connecting to the OpenAI, simply sign in to the Pinecone and get its API key as displayed in the following screenshot:
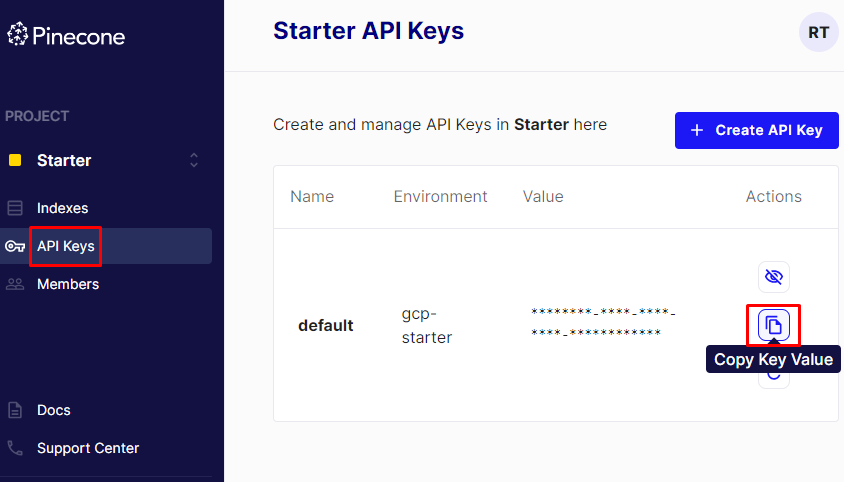
Import the pinecone library and use its function init() to connect it using its API. After that, the “environment” variable is used to create an index in the vector store:
pinecone.init(
api_key='********-****-****-****-********',
environment='gcp-starter'
)
pinecone.create_index("demo", dimension=1536)
The demo index has been created as displayed in the screenshot below:
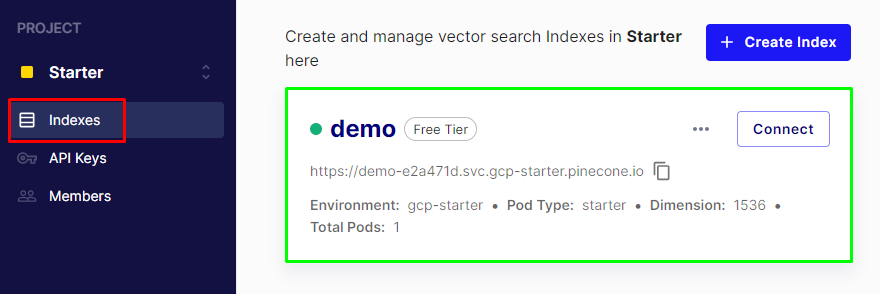
Step 3: Import Libraries
Once the index has been created on Pinecone, simply import libraries to create documents and place them inside the index:
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
Step 4: Insert Data in Pinecone Store
Create the documents containing the information about the movies and their metadata and then access the Pinecone vector store using the index name:
Document(
page_content="Earth is a million years old",
metadata={"year": 2003, "rating": 8.7, "genre": "science fiction"},
),
Document(
page_content="Mark Boucher went to the space and lost his mind",
metadata={"year": 2009, "director": "Ab De-Villiers", "rating": 9.2},
),
Document(
page_content="A doctor gets lost in a series of dreams",
metadata={"year": 2006, "director": "Ben Stokes", "rating": 7.6},
),
Document(
page_content="A bunch of highly talented ladies/women are saving the world",
metadata={"year": 2019, "director": "Sara Taylor", "rating": 8.3},
),
Document(
page_content="Toys cars are fighting for their existing at the racing track",
metadata={"year": 2000, "genre": "animated"},
),
Document(
page_content="prisoners plan to escape but caught",
metadata={
"year": 2009, "director": "Ben Ducket", "genre": "thriller", "rating": 9.9,
},
),
]
vectorstore = Pinecone.from_documents(
docs, embeddings, index_name="demo"
)
Step 5: Create a Self-Query Retriever
After inserting the data in the vector store, simply create a self-query retriever by configuring the LLM to fetch data from the vector store:
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info = [
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="genre",
description="The genre of the movie",
type="string or list[string]",
),
AttributeInfo(
name="director",
description="Director’s name",
type="string",
),
AttributeInfo(
name="rating", description="A 1-10 movie’s rating", type="float"
),
]
#configure the retriever using the LLM in the OpenAI application to get data from the database
document_content_description = "Get basic info about the movie"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm, vectorstore, document_content_description, metadata_field_info, verbose=True
)
Step 6: Test the Retriever
Now, test the self-query by calling the retriever with the prompt inside its braces:
Running the above code has fetched the data from the vector store as displayed in the following screenshot:

Use another prompt with the retriever as the following code suggests:
The retriever has fetched the data according to the query as displayed in the screenshot below:

Step 7: Specifying K Filter
After that, simply specify the K filter to limit the number of objects to be fetched from the store:
llm,
vectorstore,
document_content_description,
metadata_field_info,
enable_limit=True,
verbose=True,
)
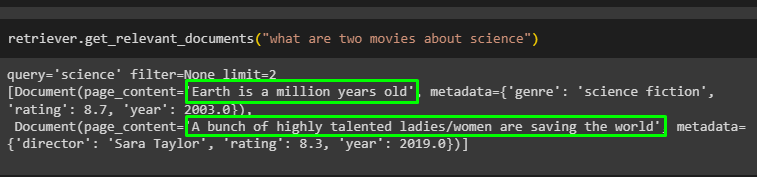
The following code uses the prompt with the limiting value to get two movies from the database:
The retriever has only fetched two movies about the science genre without any filter according to the prompt:
That is all about using the self-query with Pinecone in LangChain.
Conclusion
To use the self-querying with Pinecone in LangChain, simply install LangChain, OpenAI, and Lark with the Pinecone client. After that, import all the necessary libraries to access resources for creating the self-query with Pinecone and then store data in the database. Create a retriever to get data from the database using the prompts inside the retriever and configure the k value to limit the number of objects in the output. This post demonstrated the process of using self-query with Pinecone in LangChain.