This post will demonstrate the process of using retrievers in LangChain.
How to Use Retrievers in LangChain?
Retrievers act as the interface between models and humans so they can use it to get the desired output using the input provided in natural languages. Vector stores are used to store data which can be used to get/extract information/data from.
However, the retrievers are more general than these databases. They do not store any data and are only used to get or retrieve data for the users. To learn the process of building and using the retrievers through LangChain, look at the following steps:
Step 1: Install Modules
First, install the required modules like LangChain to get its libraries and dependencies to go on with the process:
Install chromadb vector store which can be used to database data for the retriever to fetch data from the store:
Now, install OpenAI framework to get its libraries for using the text embedding before building a retriever:
After installing all the required modules, simply set up the environment using the OpenAI API key:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Step 2: Upload Dataset
Now, execute the following code to click on the “Choose Files” button and upload the document or file from the local system:
uploaded = files.upload()
Step 3: Import Libraries
Import the required libraries to build and use the retrievers in LangChain such as “List”, “Callbacks”, and many more:
from typing import Any, List
from langchain.schema import Document
from langchain.callbacks.manager import Callbacks
Step 4: Create One Line Index Creation
This step creates the index for the retriever that can be used to get the data to form the vector store by importing the required libraries:
from langchain.llms import OpenAI
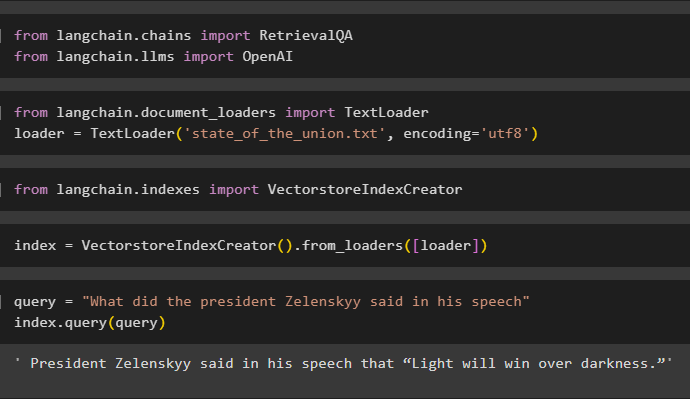
Here, load the data using the TextLoader() method with the path of the file uploaded in step 2:
loader = TextLoader('state_of_the_union.txt', encoding='utf8')
Import library VectorstoreIndexCreator from LangChain to build an index for the database:
Define the index variable using the VectorstoreIndexCreator() method using the loader variable:
Apply the query to test the index by fetching data from the document:
index.query(query)
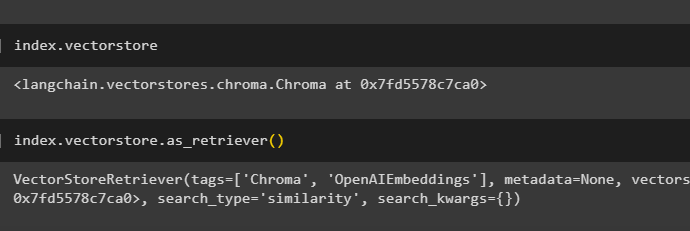
Get the details of the index as to which database has the index using the following code:
The following code will explain all the details about the index, its type, and database:
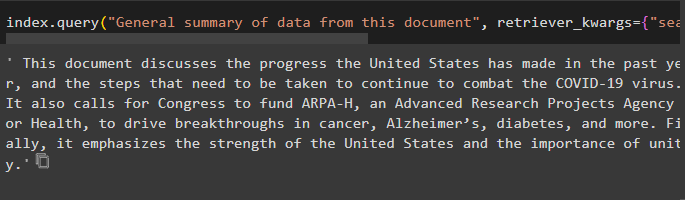
Use the index with query() method asking for the summary of the document using the source argument to use the name of the document:
Step 5: Create Embeddings
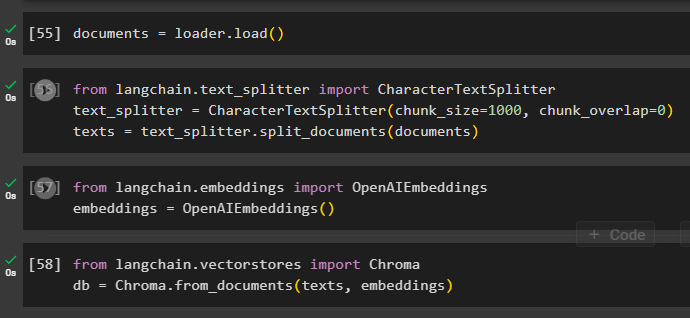
Load the document for creating its embedding and store the text in the numerical form using the vector store:
Start the process of embedding using the text_splitter with the chunks size and overlap arguments:
#using text_splitter to create small chunks of the document to use retriever
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
Apply OpenAIEmbeddings() method that can be imported from LangChain:
embeddings = OpenAIEmbeddings()
Use the chromadb store to store the embeddings created from the document:
db = Chroma.from_documents(texts, embeddings)
Step 6: Test the Retriever
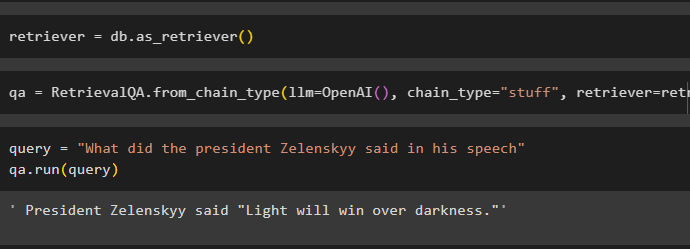
Once the embeddings are created and stored in the database simply define the retriever variable:
Call the chains using the RetrievalQA() method with the OpenAI() function and retriever as its arguments:
Provide the input to test the retriever using the query variable inside the qa.run() method:
qa.run(query)
Simply customize the VectorstoreIndexCreator() using its arguments to set different values:
vectorstore_cls=Chroma,
embedding=OpenAIEmbeddings(),
text_splitter=CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
)
That is all about the process of getting started with retrievers in LangChain.
Conclusion
To use the retrievers in LangChain, simply install the dependencies required to set up the OpenAI environment and then upload the document to test the retrievers. After that, build the retriever using an abstract base class or ABC library and then create the index for the database to retrieve the data. Configure the embeddings for the document and run the retriever to get comparable results from the database. This post has elaborated on the process of using the retrievers in LangChain.