This article will demonstrate the process of using PDF loaders in LangChain.
How to Use PDF Loaders in LangChain?
To use the PDF loader in LangChain, simply follow this simple and easy guide:
Setup Prerequisites
Before starting the process of using PDF loaders, simply install LangChain first to get started with the process:
The next module to install for this process is OpenAI and the following is mentioned the code for its installation:
Method 1: Using PyPDF Library
The first PDF loader which is used to load PDF in LangChain is the PyPDF library and it will convert the PDF into an array of documents. Install PyPDF before importing its library to use it by typing the following code in the Python IDE:
Upload the PDF file using this code in the Google Collaboratory on the cloud:
upload = files.upload()
After running the above code, simply choose the file from the local system and upload it to the cloud:

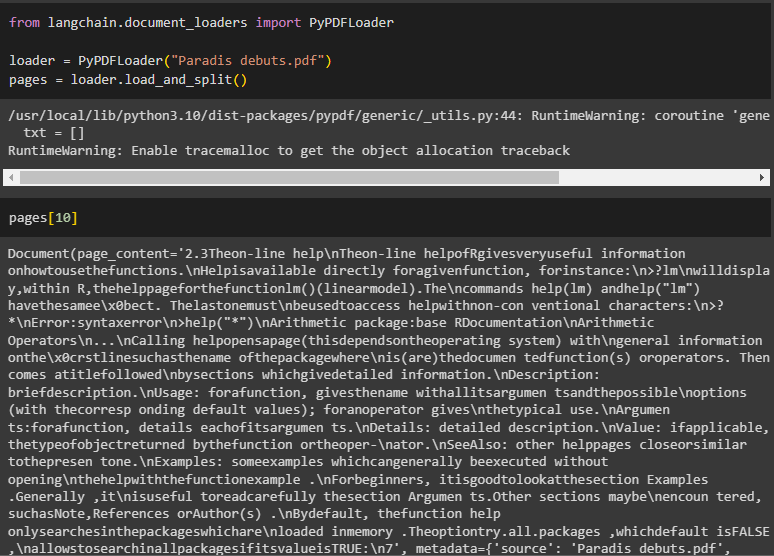
After that, import the PyPDF library from LangChain and load the PDF file to split its pages into an array of documents:
loader = PyPDFLoader("Paradis debuts.pdf")
pages = loader.load_and_split()
Now, simply use the index number to fetch the document from the PDF file:
Method 2: Using OpenAIEmbeddings Library
The next method for using the PDF loader is using the OpenAIEmbedding which requires the installation of the following modules:
- Tiktoken
- FAISS
Run the following code to get the necessary file for using the tiktoken tokenizer to load PDF files using the OpenAIEmbedding:
FAISS is the module to get efficient similarity searches from the pool of data:
After that, simply provide the OpenAI API key using the get pass library and the os library to access the resources of the operating system:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Now, simply import OpenAIEmbeddings and FAISS from LangChain to create a retriever using the command in the similarity search() function:
from langchain.embeddings.openai import OpenAIEmbeddings
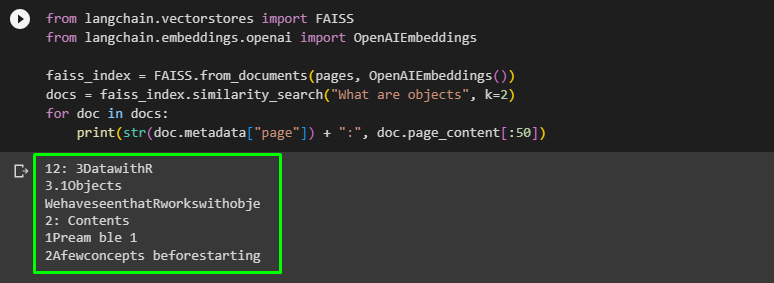
faiss_index = FAISS.from_documents(pages, OpenAIEmbeddings())
docs = faiss_index.similarity_search("What are objects", k=2)
for doc in docs:
print(str(doc.metadata["page"]) + ":", doc.page_content[:50])
The above code searches for the query using the FAISS similarity search to extract information from the document as displayed in the screenshot below:
Method 3: Using Unstructured Library
Install the unstructured module to use this method for loading PDF documents in LangChain:
Install pdf2image module to use its resources while loading the PDF files:
Another module that is required to use this method for loading PDF is pdfminer.six to get its high_level resources:
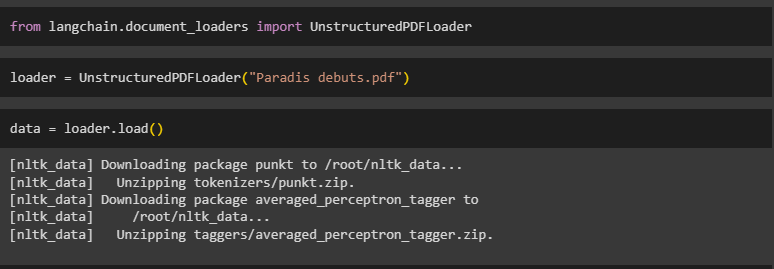
After that, import the UnstructuredPDFLoader library from LangChain:
Load the PDF file using the following code with the name of the PDF uploaded in the first method:
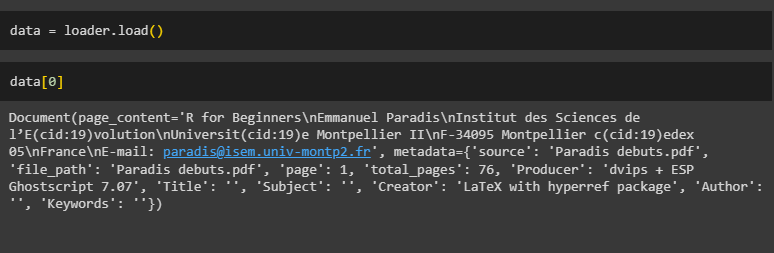
Simply print the data using the loader.load() method containing the contents of the PDF file:
Method 4: Using Unstructured Library While Retaining Elements
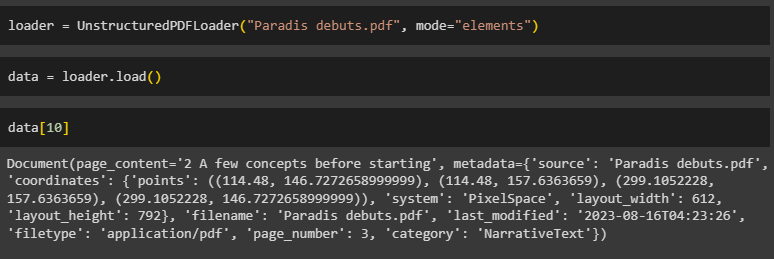
The user can also use the unstructured method to load PDF by retaining elements as the module splits the PDF into small elements. By default, the library combines these elements to display it as a single unit, but the user can simply separate them using the mode=“elements”:
Simply load the PDF in the data variable:
Print the data using the index number of the element to display it on the screen:
Method 5: Using OnlinePDFLoader Library
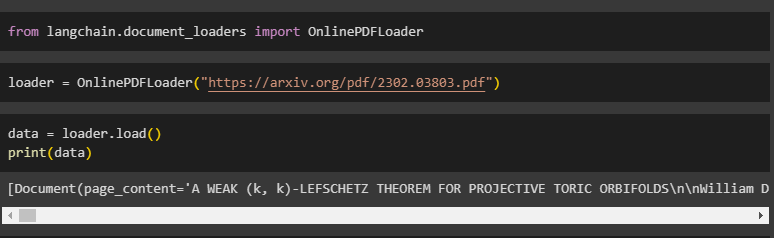
The user can also use an Online PDF loader to load PDFs from the internet using the following code:
Load the data from the internet by providing the path to the PDF file:
Simply print the file using the data variable:
print(data)
Method 6: Using PyPDFium2 Library
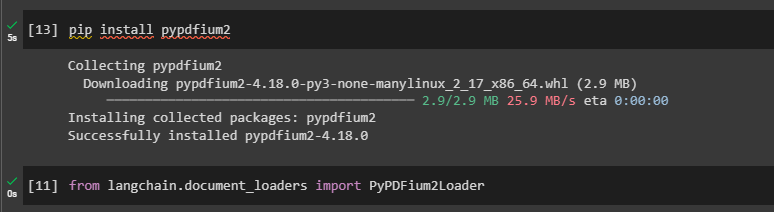
Install the PyPDFium2 module using the following code block to load PDF files:
After the installation, simply import the library to use its resources and methods:
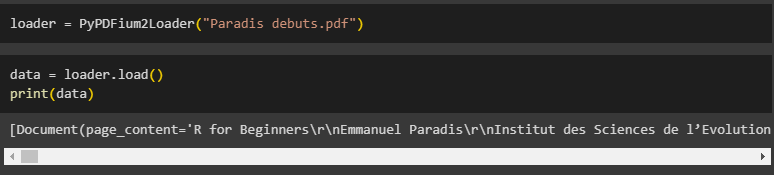
Use the PyPDFium2Loader() method with the name of the file to load it in LangChain:
Simply print the contents of the document using the data variable:
print(data)
Method 7: Using PDFMinerLoader Library
Import the PDFMinerLoader library using its module which was installed in step 3 of this post:
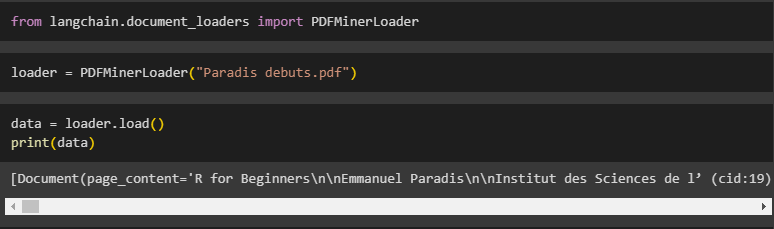
The loader will load the document using its PDFMinerLoader() with the file name uploaded in the first step and the user can upload different files to get data from them:
The PDFMinerLoader loads the data in the data variable, and it can be printed on screen by simply calling data using the print() function:
print(data)
Method 8: Using PDFMinerLoader Library to Get HTML Text
The PDFMinerLoader can also be used to display the PDF as HTML in LangChain by using the PDFMinerPDFasHTMLLoader library:
Simply laid the PDF file using its function:
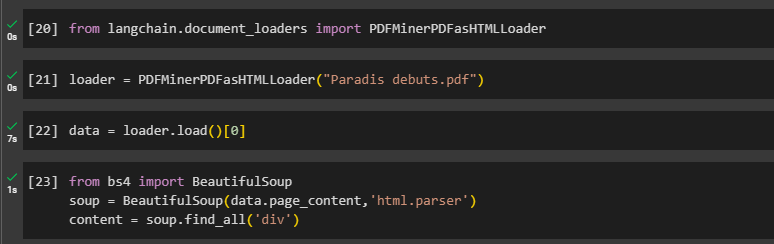
Load the complete data/file as one document:
Using the BeautifulSoup library, the user can get useful insights from the data like its metadata containing the size of the document, the font used in it, etc.
soup = BeautifulSoup(data.page_content,'html.parser')
content = soup.find_all('div')
Configure the style of output to be displayed about the PDF file like snippets with the same font size and find duplicates in the document to identify the headers and footers:
cur_fs = None
cur_text = ''
snippets = []
for c in content:
sp = c.find('span')
if not sp:
continue
st = sp.get('style')
if not st:
continue
fs = re.findall('font-size:(\d+)px',st)
if not fs:
continue
fs = int(fs[0])
if not cur_fs:
cur_fs = fs
if fs == cur_fs:
cur_text += c.text
else:
snippets.append((cur_text,cur_fs))
cur_fs = fs
cur_text = c.text
snippets.append((cur_text,cur_fs))
Provide some more configurations to identify more specific details like the size of the heading and its content concerning changes in their sizes and another formatting:
cur_idx = -1
semantic_snippets = []
for s in snippets:
if not semantic_snippets or s[1] > semantic_snippets[cur_idx].metadata['heading_font']:
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
continue
if not semantic_snippets[cur_idx].metadata['content_font'] or s[1] <=
semantic_snippets[cur_idx].metadata['content_font']:
semantic_snippets[cur_idx].page_content += s[0]
semantic_snippets[cur_idx].metadata['content_font'] = max(s[1], semantic_snippets[cur_idx].metadata['content_font'])
continue
metadata={'heading':s[0], 'content_font': 0, 'heading_font': s[1]}
metadata.update(data.metadata)
semantic_snippets.append(Document(page_content='',metadata=metadata))
cur_idx += 1
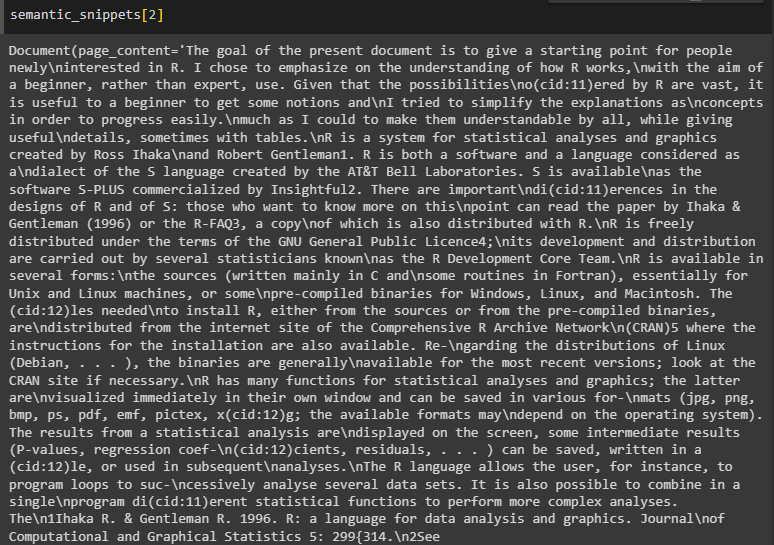
Simply use the semantic_snippets with the index number of the element:
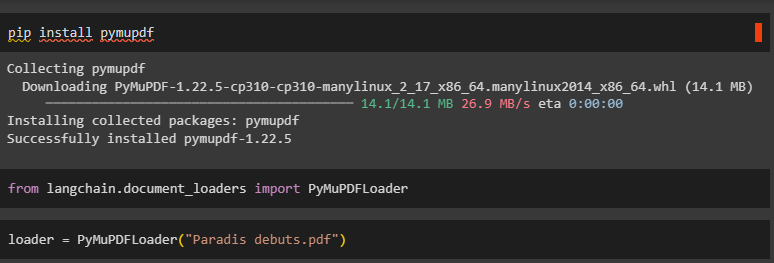
Method 9: Using PyMuPDFLoader Library
PDF loaders have their respective advantages as PyMuPDFLoader is the fastest to load PDF files and fetches useful information like metadata of the content. Simply install the module to use its libraries and methods in LangChain:
Import the library to laid PDF files using its module installed previously:
Load the dataset containing PDF style document:
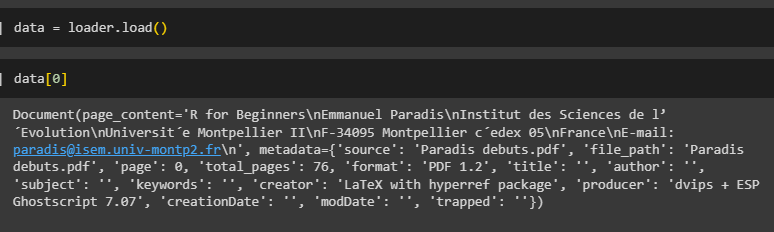
Load the file and initialize it using the data variable:
Simply use the index number of the data as the PuMuPDFLoader returns one document per page:
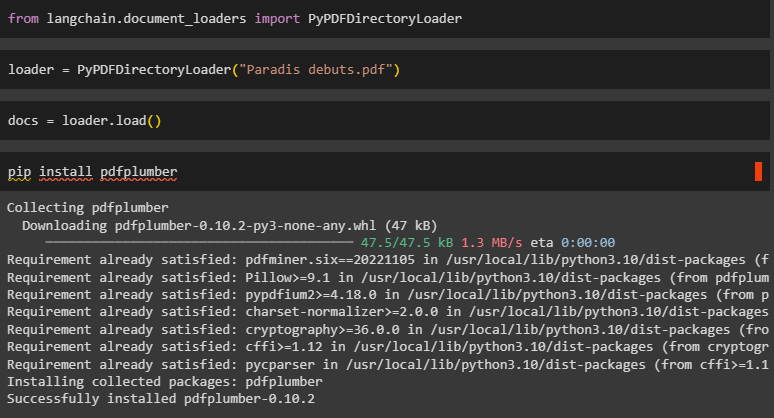
Method 10: Using PyPDFDirectoryLoader Library
To load the PDF from the directory, simply import the PyPDFDirectoryLoader library using the PyPDF installed in the first method:
Load the PDF file uploaded earlier using its method for loading PDF files:
Load the data in the “docs” variable by initializing it with the PDF file:
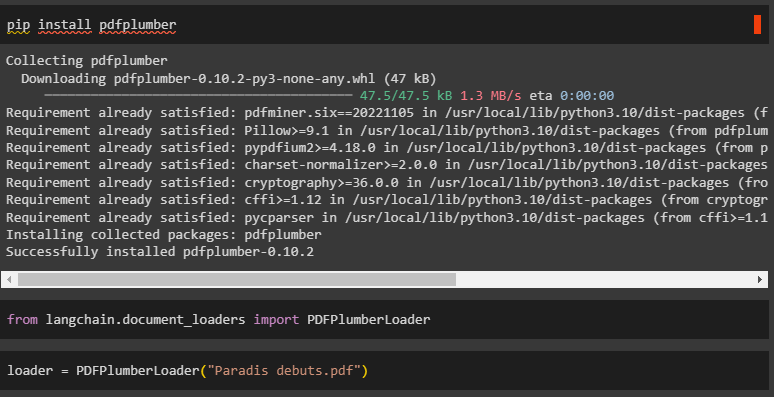
Method 11: Using PDFPlumberLoader Library
The PDFPlumberLoader is another method that can be used to load PDF files in LangChain:
Simply import the PDFPlumberLoader library to use its functions to laid PDF files:
Load the PDF file using the PDSPlumberLoader() function:
Simply load the data in the data variable using the loader.load() method:
Print the data variable using the index number of the document to be displayed on the screen:
That is all about using the PDF loaders in LangChain to fetch data from PDF files/documents.
Conclusion
To use the PDF loaders in LangChain, simply install LangChain and OpenAI modules to get started with the process. LangChain allows multiple processes to use PDF loaders as this guide explains eleven of them in detail with their code and explanations. This guide has demonstrated the process of using the PDF loaders in LangChain to get data from the portable document format.