This post will demonstrate the process of using the parent document retriever in LangChain.
How to Use a Parent Document Retriever in LangChain?
Parent document retriever in LangChain can be used by splitting the documents into smaller chunks so they do not lose their meaning at the moments of embedding. The parent document can be said to be the whole document or the larger chunk from which the smaller chunks are extracted.
To learn the process of using the parent document retriever in LangChain, simply check out this guide:
Step 1: Install Modules
First, start using the parent document retriever by installing the LangChain framework using the pip command:
Install the Chroma database module to save the embeddings of the document and retrieve data from it:
To install tiktoken which is a tokenizer that gets the tokens of the document by creating small chunks:
Get the OpenAI module by executing the following command on the Python notebook to get its dependencies and libraries:
Step 2: Setup Environment & Upload Data
The next step is to set up the environment using the API key from the OpenAI account:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Now, upload the documents from the local system after importing the files library and then call the upload() method:
uploaded = files.upload()
Step 3: Import Libraries
The next step contains the code for importing the required libraries for using the parent document retrievers using the LangChain framework:
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders import TextLoader
Load the document to build the retriever using the TextLoader() methods with the path of the files:
TextLoader('Data.txt'),
TextLoader('state_of_the_union.txt'),
]
docs = []
for l in loaders:
Step 4: Retrieving Complete Documents
Once the documents/files are loaded to the model, simply build the embeddings of the documents, and store them in the vector stores:
vectorstore = Chroma(
collection_name="full_documents",
embedding_function=OpenAIEmbeddings()
)
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
Now, call the add_documents() method using the retriever to get the retriever to the documents:
The following code extracts the embeddings of the documents that have been stored in the database for the uploaded files:
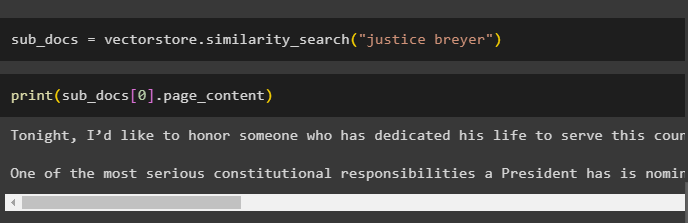
After getting the embeddings of the documents, call the similarity_search() method with the query to get the small chunks from the document:
Call the print() method to display the chunks called in the previous code based on the query:
Call the complete the retriever() function to get all the tokens stored in the database using the following code:
Printing all the documents would take a huge time and processing power, so simply get the length of documents retrieved previously:
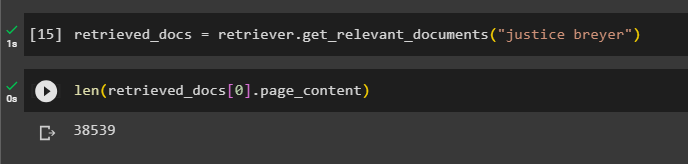
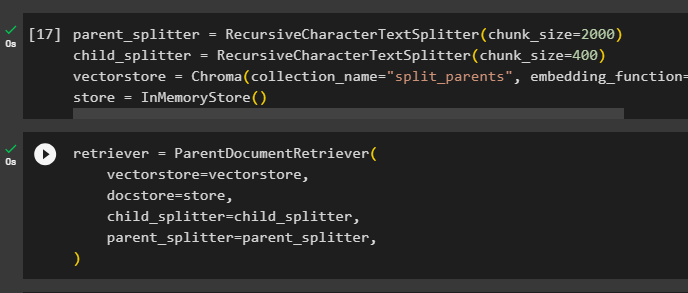
Step 5: Retrieving Larger Chunks
This step will not take the whole document; however, it would take a bigger chipmunk from the document and retrieve a smaller chunk from it:
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="split_parents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
Configure the retriever to get the smaller token from the huge pool of data stored in the “vectorstore” variable:
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
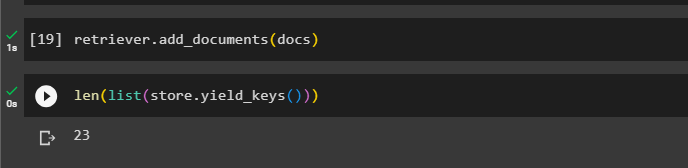
Call the retriever to get the larger chunks from the vector stores using the docs variable in the argument of the function:
Get the length of these documents from the docs variable via the below command:
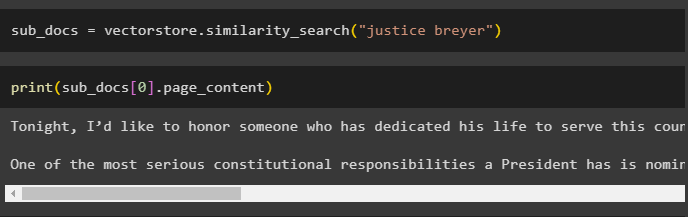
Simply get a smaller chunk from a bigger one as the previous screenshot displays that there are 23 documents stored in the vector store. The query is used to get the relevant data using the similarity_search() method to retrieve data from the vector store:
Print the smaller chunks using the query mentioned in the previous code to display them on the screen:
Now, use the retriever on the complete dataset stored in the database using the query as the argument of the function:
Get the length of the complete chunks created and stored in the database:
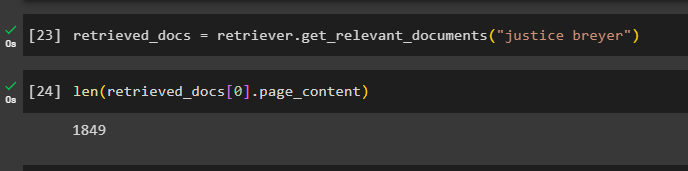
We cannot display all the chunks, but the first chunk with the index number 0 is displayed using the following code:
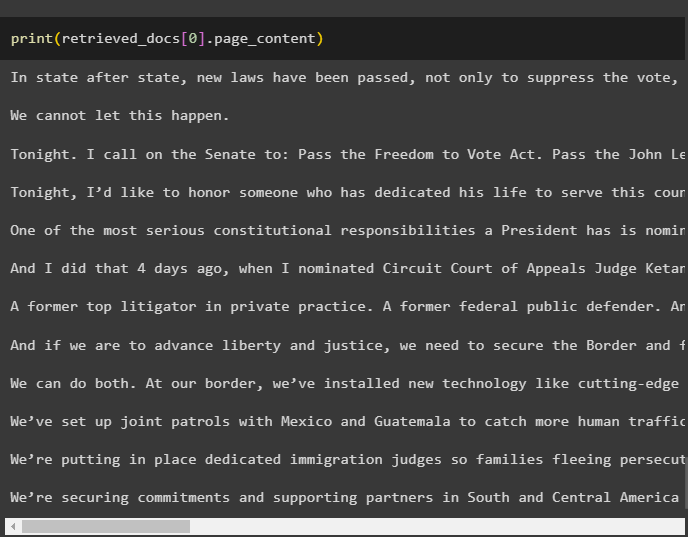
That is all about the process of using the parent document retriever in LangChain.
Conclusion
To use the parent document retriever in LangChain, simply install the modules and set up the OpenAI environment using its API key. After that, import the required libraries from LangChain for using the parent document retriever, and then load the documents for the model. The user can use parent documents as the whole document or the large chunk and get a smaller chunk using the query. This post has elaborated on the process of using the parent document retriever in LangChain.