LangChain allows the issuer to build Large Language Models or LLMs to answer the queries in natural language. The user can question the bots from multiple datasets, and the models must differentiate between the datasets and queries related to them. LangChain framework uses MultiQueryRetrievers to get data from multiple vector stores for multiple queries at the same time to work simultaneously.
This guide will explain the process of using the MultiQueryRetriever in LangChain.
How to Use MultiQueryRetriever in LangChain?
To use the MultiQueryRetriever in LangChain, simply follow this simple and easy guide:
Setup Prerequisites
Install LangChain using the following code to start the process of using the MultiQueryRetriever in LangChain:
Install OpenAI to build the LLMs using its functions to embed the texts in vector stores which makes them more manageable:
Install Chromadb which is a vector store for the LangChain to store datasets for the AI models:
Install the FAISS framework to make the similarity search more efficient:
The following code uses os and getpass() libraries to enter the API key for the OpenAI account:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")

Import Libraries
After providing the API key, simply import the MultiRetrievalQAChain from LangChain and OpenAI from LLMs
from langchain.llms import OpenAI
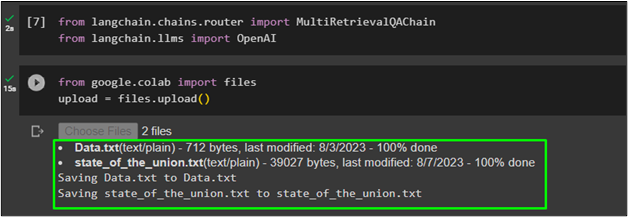
After importing the libraries, simply upload the data to create retrievers based on the datasets:
upload = files.upload()
The datasets uploaded are named Data.txt which contains an essay related to the child and his family and state_of_the_union.txt which contains the data about the state of the union addresses:
Create Retriever
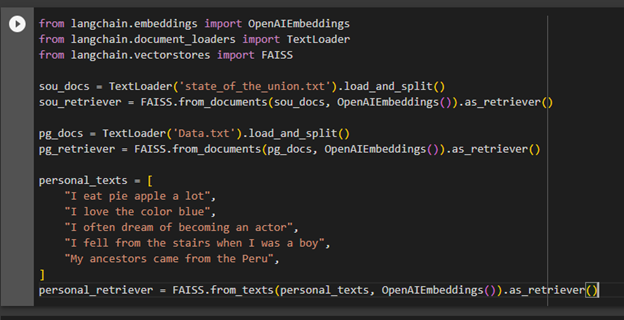
After uploading the data, simply create a retriever using two uploaded datasets and one self-created text in the query to train the retrievers based on all of them:
from langchain.document_loaders import TextLoader
from langchain.vectorstores import FAISS
sou_docs = TextLoader('state_of_the_union.txt').load_and_split()
sou_retriever = FAISS.from_documents(sou_docs, OpenAIEmbeddings()).as_retriever()
pg_docs = TextLoader('Data.txt').load_and_split()
pg_retriever = FAISS.from_documents(pg_docs, OpenAIEmbeddings()).as_retriever()
personal_texts = [
"I eat pie apple a lot",
"I love the color blue",
"I often dream of becoming an actor",
"I fell from the stairs when I was a boy",
"My ancestors came from the Peru",
]
personal_retriever = FAISS.from_texts(personal_texts, OpenAIEmbeddings()).as_retriever()
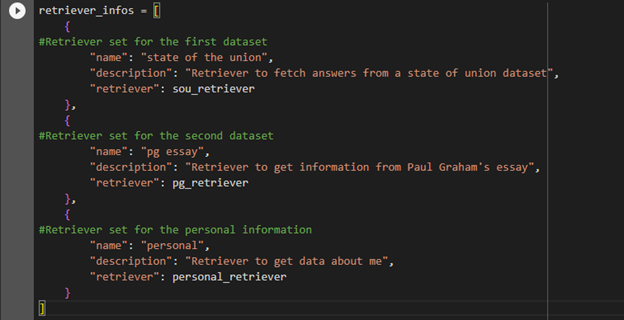
The retriever’s information code explains the three datasets and their queries to make the LLM enable for handling all kinds of queries from the data provided earlier:
{
#Retriever set for the first dataset
"name": "state of the union",
"description": "Retriever to fetch answers from a state of union dataset",
"retriever": sou_retriever
},
{
#Retriever set for the second dataset
"name": "pg essay",
"description": "Retriever to get information from Paul Graham's essay",
"retriever": pg_retriever
},
{
#Retriever set for the personal information
"name": "personal",
"description": "Retriever to get data about me",
"retriever": personal_retriever
}
]
Test the MultiQueryRetriever
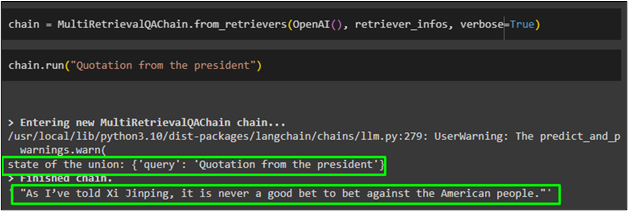
Once the retriever is created, simply use the variable named chain to run the MultiQueryQAChain library imported from LangChain:
Simply run the chain with the query related to any of the given datasets:
The retriever has successfully detected the query from the dataset and retrieved the answer from that database:
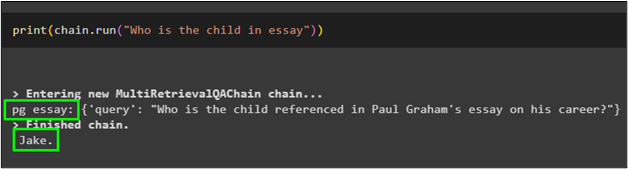
Again, ask the question using a chain.run() function from the dataset:
The MultiQueryRetriever also detected this from the essay and provide the answer accordingly:
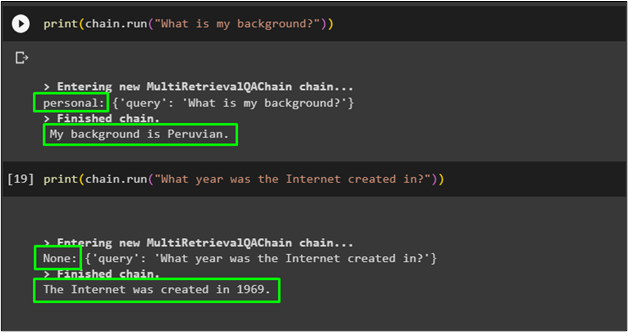
The following code uses the query from the personal information about the background:
The chain has retrieved the answer from the personal dataset loaded with the retriever.
The following code asks the query which not related to either dataset:
The following screenshot displays that the MultiRetriever provided the answer but also shows that the query was not from any dataset:
That is all about using MultiQueryRetriever in LangChain.
Conclusion
To use the MultiQueryRetriver in LangChain, simply install all the necessary frameworks for building a multi-query retriever and then set up the OpenAI PAI key. After that, import the functions and libraries like MultiRetrieverQAChain to build the retrievers using the multiple datasets and then train it on these datasets. In the end, simply test the retriever by asking questions related to these datasets and also ask which does not belong to any data. This post has demonstrated the process of creating and using the MultiQueryRetriever in LangChain.