Text splitting is an important aspect of LangChain to build Large Language Models or LLMs to interact efficiently with humans. One of the techniques to split the text into small chunks is using the MarkdownHeaderTextSplitter which is used to split text based on file headers. The user can simply get the file organized by headers and create chunks within specified headers to split the markdown file.
This guide will demonstrate the process of using MarkdownHeaderTextSplitter in LangChain.
How to Use MarkdownHeaderTextSplitter in LangChain?
To use the MarkdownHeaderTextSplitter in LangChain, simply follow this simple and thorough guide:
Install and Import Libraries
To get started with the guide, simply install the LangChain framework. This guide uses this framework to split text using the markdown header:
Import the MarkdownHeaderTextSplitter library from the “langchain.text_splitter” which is a LangChain library:
Example 1: Using Markdown Splitter
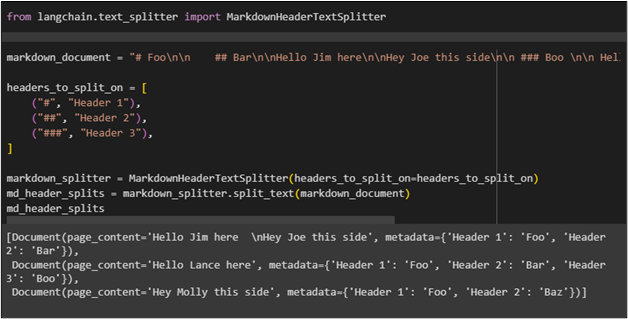
Configure the “markdown_document” variable with the content using the headers and then split the data based on these headers. Split the headers into three chunks with the number of hash signs as configured in the following code. After that, split the markdown document using the imported library and then print the document on the screen:
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
After executing the above code, the split document has displayed in three chunks:
Execute the following command to get the type of document located at the index 0 in the md_header_splits variable:

Example 2: Using Multiple Text Splitters
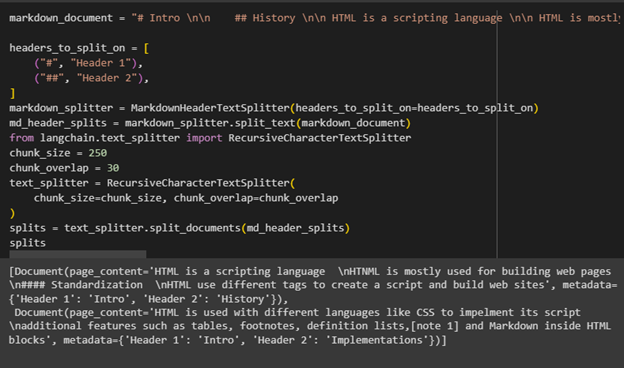
This example uses multiple splitters such as markdown_splitter and Character level splitter. They use the markdown header text splitter. Before using these splitters, simply insert data with headers and set the number of chunks to print their chunks:
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 250
chunk_overlap = 30
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(md_header_splits)
splits
The following screenshot displays the number of documents split into small chunks:
That is all about using the MarkdownHeaderTextSplitter in LangChain.
Conclusion
To use the MarkdownHeaderTextSplitter library in LangChain, simply install LangChain modules to get the library which can be used to split text into small chunks. After that, configure the data with the specified header to use the markdown splitter and make smaller documents from it. The second example in this guide explains the use of multiple splitters in the MarkdownHeaderTextSplitter in LangChain.