LangChain is used to build Large Language Models or LLMs that understand the prompt in natural language and generate text accordingly. The data can be stored in the vector stores which act like a database for LangChain to manage massive data and use it to train the model. The user can call a retriever to extract data from vector stores and the ensemble retriever uses the list of retrievers and ranks their answers. The major ensemble retrievers in LangChain are BM25 (Sparse retriever), dense retriever, etc.
This post demonstrates the process of using the ensemble retriever in LangChain.
How to Use an Ensemble Retriever in LangChain?
To use the ensemble retriever in LangChain, simply follow this basic guide with a thorough explanation of the process:
Install Prerequisites
Install the LangChain module to start using its resources that allow the use of ensemble retriever:
Install the OpenAI module to apply its embedding library in the process of retrieving data:
FAISS module is used to apply efficient searches like similarity search and display data on the screen:
Install the rank_bm25 module to apply the ranking of all the retrievers and find the list of them:
Install tiktoken tokenizer to split data and embed them using OpenAI embedding:
After installing all the necessary modules, simply provide the OpenAI API key to use the OpenAI account:
import getpassos.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
Create Ensemble Retriever
Simply import libraries like BM25Retriever, EnsembleRetriever, FAISS, and OpenAIEmbeddings from the modules installed previously:
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
Provide the data in the form of a list and apply BM25Retriever and FAISS retrievers to fetch data after embedding the data. After that, simply initialize the ensemble retriever on the BM25Retriever and FAISS retrievers with equal weights:
"I like apples",
"I like oranges",
"Apples and oranges are fruits",
]# initialize the bm25 retriever and faiss retriever
bm25_retriever = BM25Retriever.from_texts(doc_list)
bm25_retriever.k = 2
embedding = OpenAIEmbeddings()
faiss_vectorstore = FAISS.from_texts(doc_list, embedding)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2})
# initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5])
Calling the Ensemble Retriever
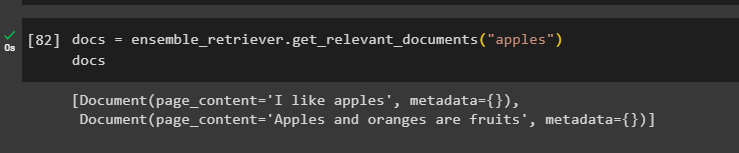
Apply the ensemble retriever function to get relevant data according to the query and display it on the screen using the “docs” variable:
docs
The following screenshot displays the extracted information from the data using the prompt in the ensemble retriever function:
That is all about using the ensemble retriever in LangChain.
Conclusion
To use the ensemble retriever in LangChain, simply install the modules for using the process like LangChain, OpenAI, FAISS, rank_bm25, etc. After that, provide the OpenAI API key and import libraries from the modules installed earlier. Insert data and apply retrievers on the data after embedding it using the OpenAIEmbeddings library and use an ensemble retriever to fetch information. This post demonstrated the process of using the ensemble retriever in LangChain.