This post will demonstrate the process of using the CSVLoader retriever in LangChain.
How to Use a CSVLoader Retriever in LangChain?
The CSVLoader retriever in LangChain is used to load the dataset to train the Machine Learning models or Large Language Models to solve NLP problems. It enables the user to get useful information from the data or generate text from the document according to input provided by the user.
To learn the process of using CSVLoader retriever in LangChain, simply go through this guide:
Step 1: Install Modules
First, install the LangChain module to get started with the process of using the CSVLoader retriever:
After that, install the OpenAI module which can be used to build the LLMs using the CSV documents/dataset:
Step 2: Upload CSV File
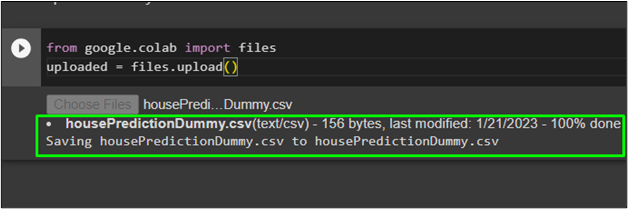
Import the files library to call the upload() method from the Google Collaboratory notebook:
uploaded = files.upload()
After executing the above code, click on the “Choose Files” button to upload the file from the local system:
Step 3: Using CSVLoader
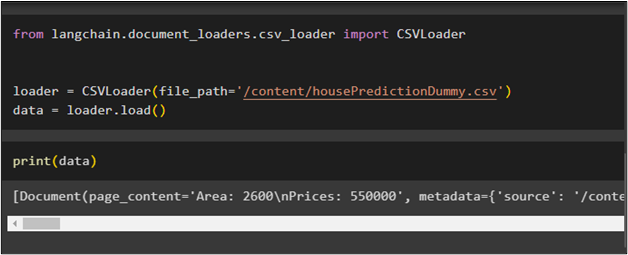
After uploading the CSV file from the local system to the notebook, simply import the CSVLoader to use the file by using its path and store it in the data variable:
loader = CSVLoader(file_path='/content/housePredictionDummy.csv')
data = loader.load()
Now, simply print the content of the CSV file by calling the data variable in the print() method:
Use the actual path of the CSV file for the file_path variable.
Step 4: Customizing CSV Loading
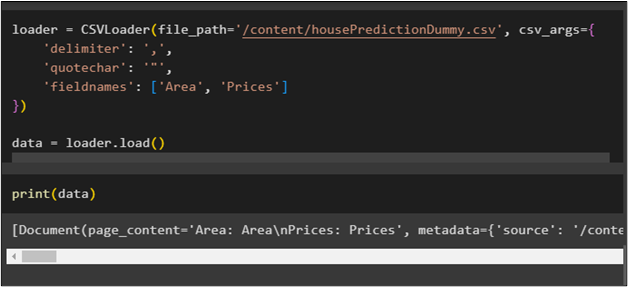
The next step explains the process of using the CSVLoader to get the customized output from the dataset using the name of the fields:
'delimiter': ',',
'quotechar': '"',
'fieldnames': ['Area', 'Prices']
})
data = loader.load()
Now, get the customized output from the dataset using the print() method:
Step 5: Identifying Specific Columns
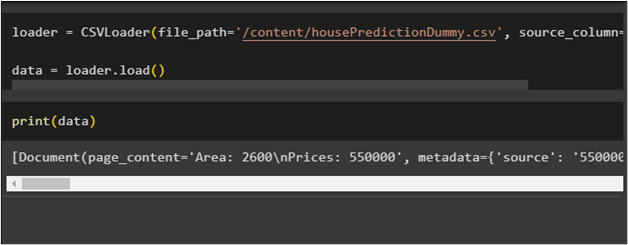
Another use of the CSVLoader() method is to identify a specific field or column from the CSV file using the “source_column” argument:
data = loader.load()
Now, display the source column by printing the values of the CSV file using the data variable:
That is all about using the CSVLoader retriever in LangChain.
Conclusion
To use the CSVLoader retriever in LangChain, get the dependencies or libraries from the LangChain framework by installing it using the “pip” command. Upload the CSV file on the Python Notebook and then import the CSVLoader library that can be used to load and retrieve data from the file. After that, the user can customize the data from the file or get the specific columns using the “source_column” argument. This post has demonstrated the process of using the CSVLoader retriever through LangChain.