This guide will illustrate the process of using a conversation token buffer in LangChain.
How to Use a Conversation Token Buffer in LangChain?
The ConversationTokenBufferMemory library can be imported from the LangChain framework to store the most recent messages in the buffer memory. The tokens can be configured to limit the number of messages stored in the buffer and the earlier messages will be flushed automatically.
To learn the process of using the conversation token buffer in LangChain, utilize the following guide:
Step 1: Install Modules
First, install the LangChain framework containing all the required modules using the pip command:
Now, install the OpenAI module to build the LLMs and chains using the OpenAI() method:
After installing the modules, simply use the OpenAI’s API key to set up the environment using the os and getpass libraries:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Step 2: Using Conversation Token Buffer Memory
Build the LLMs using the OpenAI() method after importing the ConversationTokenBufferMemory library from the LangChain framework:
from langchain.llms import OpenAI
llm = OpenAI()
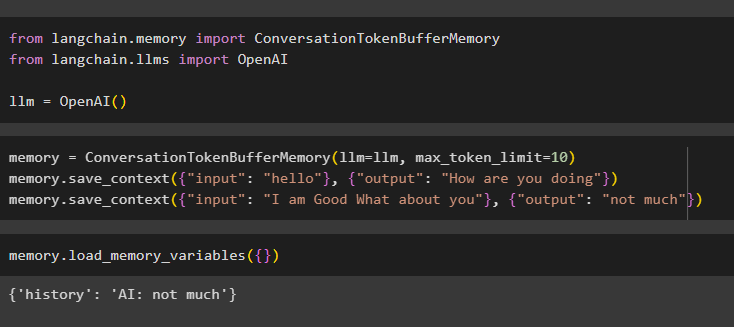
Configure the memory to set the token, it flushes the old messages and stores them in the buffer memory. After that, store the messages from the conversation and get the most recent ones for using them as the context:
memory.save_context({"input": "hello"}, {"output": "How are you doing"})
memory.save_context({"input": "I am Good What about you"}, {"output": "not much"})
Execute the memory to get the data stored in the buffer memory using the load_memory_variables() method:
Step 3: Using Conversation Token Buffer Memory in a Chain
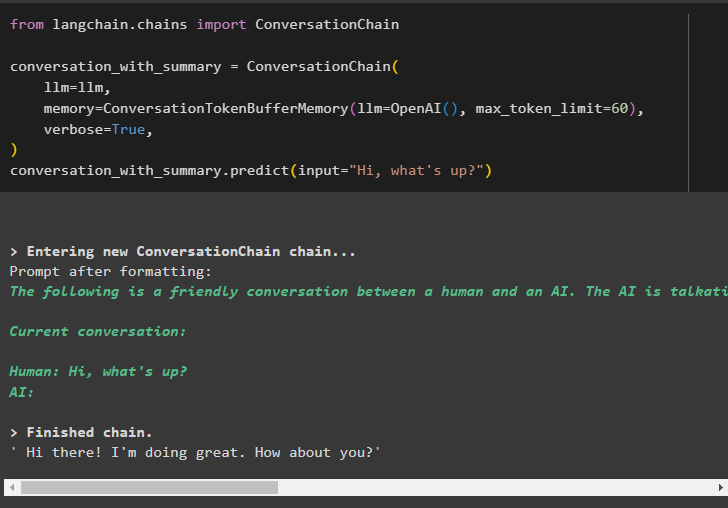
Build the chains by configuring the ConversationChain() method with multiple arguments to use the conversation token buffer memory:
conversation_with_summary = ConversationChain(
llm=llm,
memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60),
verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
Now, get the conversation going by asking questions using the prompts written in natural language:
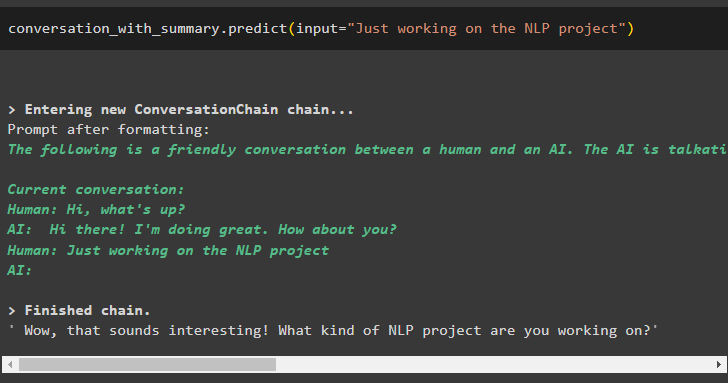
Get the output from the data stored in the buffer memory using the number of tokens:
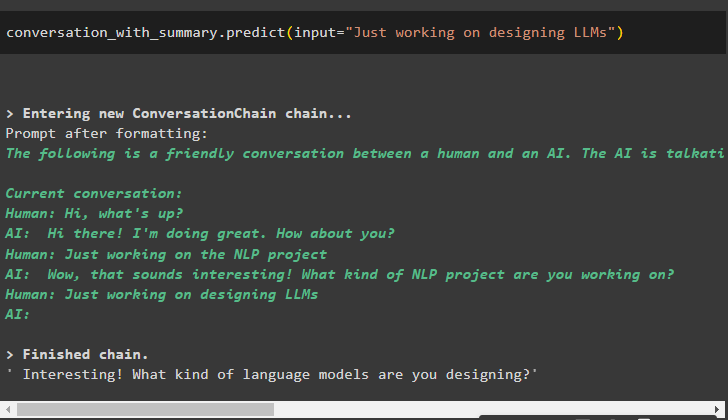
The buffer keeps updating with each new input as the previous messages are being flushed regularly:
input="LLM using LangChain! Have you heard of it"
)
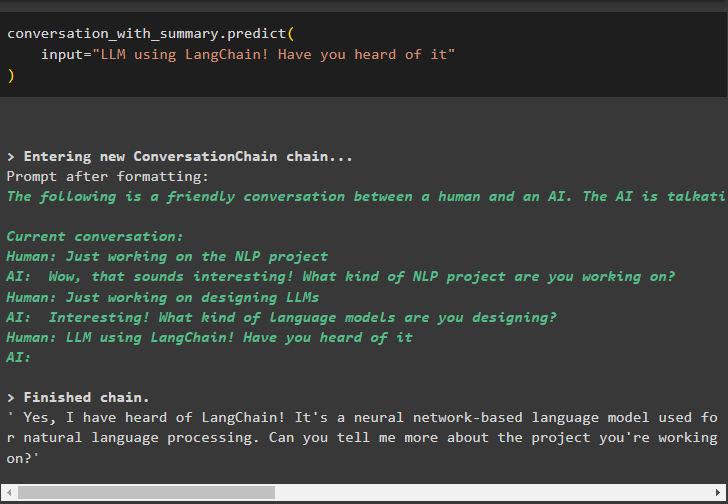
That is all about using the conversation token buffer in LangChain.
Conclusion
To use the conversation token buffer in LangChain, simply install the modules to set up the environment using the API key from the OpenAI account. After that, import the ConversationTokenBufferMemory library using the LangChain module to store the conversation in the buffer. The buffer memory can be used in a chain to flush the older messages with every new message in the chat. This post has elaborated on using the conversation token buffer memory in LangChain.