This guide will illustrate the process of using a conversation summary buffer in LangChain.
How to Use a Conversation Summary Buffer in LangChain?
Conversation can comprise multiple messages that are like an interaction between human and machine and the buffer can store the most recent messages. The ConversationSummaryBufferMemory library is used to combine both concepts like storing the most recent messages and extracting their summary.
To learn the process of using the conversation summary buffer in LangChain, simply go through the following guide:
Step 1: Install Modules
First, install the LangChain module using the pip command to get the required libraries:
Install the tiktoken tokenizer which can be used to split the text documents into small chunks:
After that, install the OpenAI modules that can be used to build the language models like LLMs and chains:
Now, set up the environment by getting the API key from the OpenAI account and using it in the model:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Step 2: Using Conversation Summary Buffer
Start the process of using the conversation summary buffer by importing the libraries to build the LLM using the OpenAI() method:
from langchain.llms import OpenAI
llm = OpenAI()
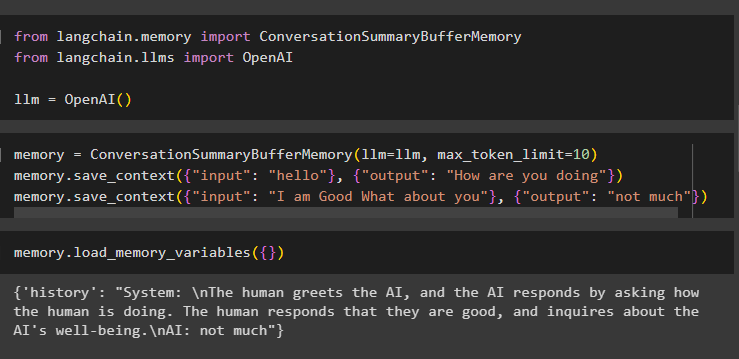
Build the memory using the ConversationSummaryBufferMemory() method and then store the conversation in the memory:
memory.save_context({"input": "hello"}, {"output": "How are you doing"})
memory.save_context({"input": "I am Good What about you"}, {"output": "not much"})
Now, execute the memory by calling the load_memory_variables() method to extract messages from the memory:
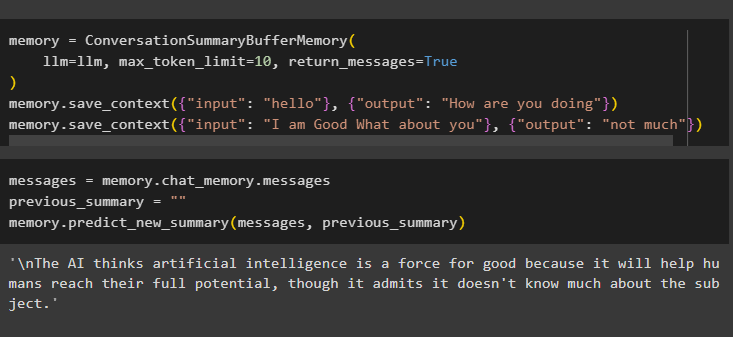
Now, use the buffer summary of the conversation to configure the buffer by limiting the number of messages to be stored in the buffer. After that, extract the summary of these messages stored in the buffer and then store the conversation in the memory:
llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hello"}, {"output": "How are you doing"})
memory.save_context({"input": "I am Good What about you"}, {"output": "not much"})
Get the summary of the previous messages stored in the buffer memory using the following code:
previous_summary = ""
memory.predict_new_summary(messages, previous_summary)
Step 3: Using Conversation Summary Buffer in a Chain
Build the chains using the ConversationChain() method containing the value for the buffer memory to store the message in it:
conversation_with_summary = ConversationChain(
llm=llm,
memory=ConversationSummaryBufferMemory(llm=OpenAI(), max_token_limit=40),
verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
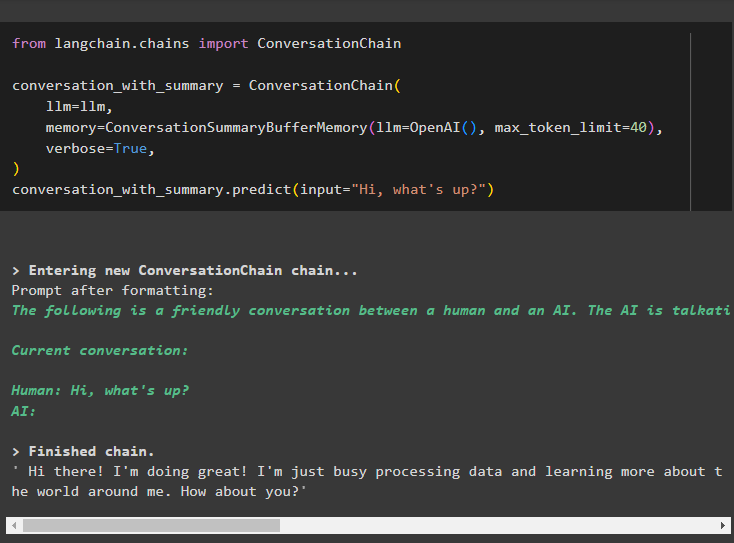
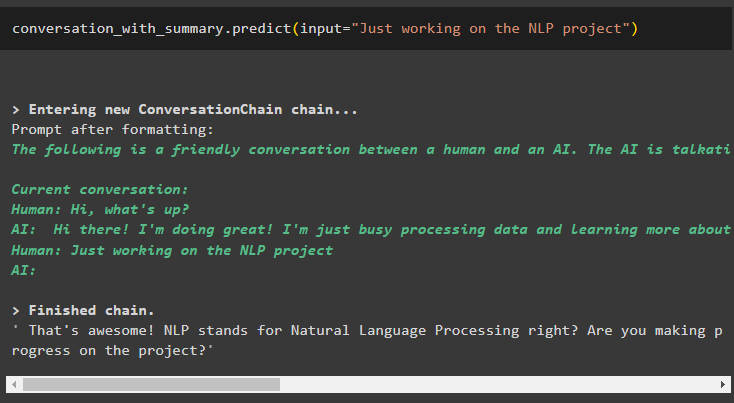
Provide the input in the form of the text using the predict() method to get the summary of the conversation:
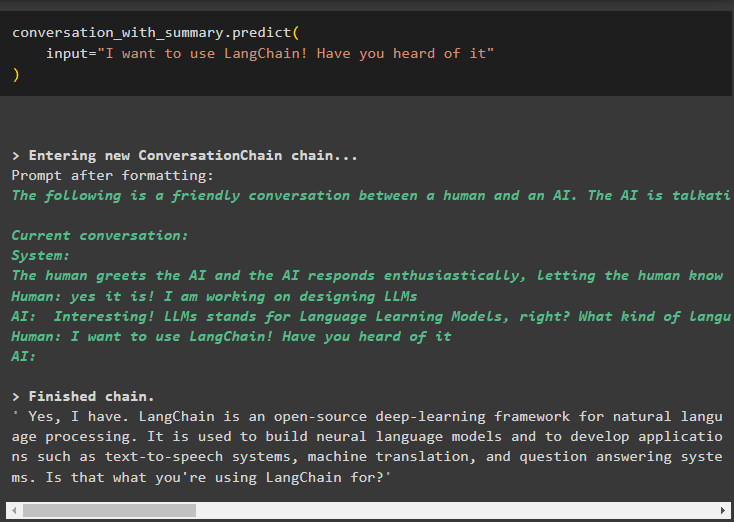
Use the output from the model and add more data using the messages in the buffer memory and display its summary:
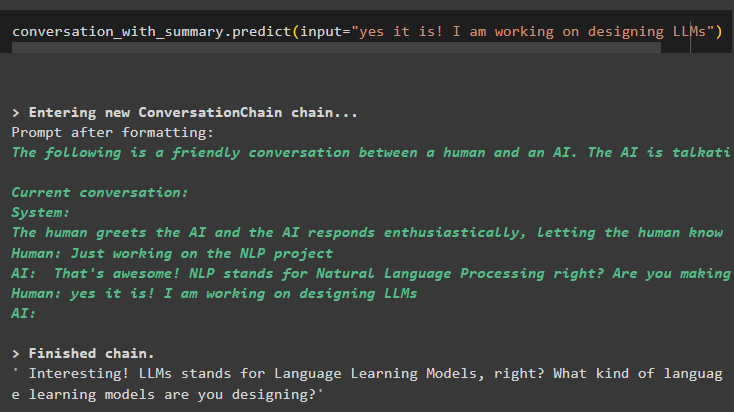
The summary is the output will be easily understandable and more human-friendly and is more suitable for chatbots:
input="I want to use LangChain! Have you heard of it"
)
That is all about using the conversation summary buffer in LangChain.
Conclusion
To use the conversation summary buffer memory in LangChain, simply install the modules or frameworks to get the required libraries. Once the libraries are imported, build the LLMs or chatbots to use the ConverstaionSummaryBufferMemory() function to get the summary of the conversation. The buffer memory is used to limit the number of messages stored in the memory to use for extracting the summary. This post has elaborated on the process of using the conversation summary buffer memory in LangChain.