
While this is technically correct but practically, this is very disastrous. The reason is that as the data grows, a lot of redundancies and useless data gets stored. Many of the times, the data may even conflict. Such a thing can be very harmful to any business. The solution is storing the data in a database.
Database Management System or DBMS, in short, is a software that allows the users to manage their database. When dealing with huge chunks of data, a database is used. Database Management System provides you with a lot of critical features. UPSERT is one of these features. UPSERT, as the name, indicates a combination of two words Update and Insert. The first two letters are from Update while the rest four are from Insert. UPSERT allows the Data Manipulation Language (DML’s) author to insert a new row or update an existing row. UPSERT is an atomic operation meaning it is a single-step operation.
MySQL, by default, provides ON DUPLICATE KEY UPDATE option to INSERT, which performs this task. However, other statements can be used to complete this task. These include statements like IGNORE, REPLACE, or INSERT.
You can perform UPSERT using MySQL in three ways.
- UPSERT using INSERT IGNORE
- UPSERT using REPLACE
- UPSERT using ON DUPLICATE KEY UPDATE
Before we move further, I will be using my database for this example, and we will be working in MySQL workbench. I am currently using version 8.0 Community Edition. The name of the database used for this tutorial is Sakila. Sakila is a database containing sixteen tables. We will focus on the store table in this database. This table contains four attributes and two rows. The attribute store_id is the primary key.
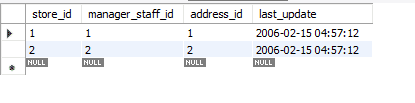
Let’s see how the above ways affect this data.
UPSERT USING INSERT IGNORE
INSERT IGNORE causes MySQL to ignore your execution errors when you perform an insert. So, if you are inserting a new record with the same primary key as one of the records already in the table, you will get an error. However, if you perform this action using INSERT IGNORE, the resulting error will be suppressed.
Here we try to add the new record using the standard MySQL insert statement.
![]()
We receive the following error.

But when we perform the same function using INSERT IGNORE, we receive no error. Instead, we receive the following warning, and MySQL ignores this insert statement. This method is beneficial when you are adding enormous amounts of new records to your table. So, if there are some duplicates, MySQL will ignore them and will add the remaining records to the table.
![]()
UPSERT Using REPLACE:
In some circumstances, you may wish to update your existing records to keep them up to date. Using standard insert here will give you a Duplicate entry for PRIMARY KEY error. In this situation, you can use REPLACE to perform your task. When you use REPLACE any two on the following events take place.
There is an old record that matches this new record. In this case, REPLACE works like a standard INSERT statement and inserts the new record in the table. The second case is that some previous record matches the new record to be added. Here REPLACE updates the existing record.
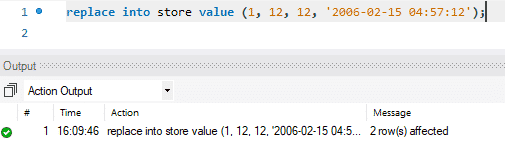
The updating is done in two steps. In the first step, the existing record is deleted. Then the newly updated record is added just like a standard INSERT. So it performs two standard functions, DELETE and INSERT. In our case, we replaced the first row with newly updated data.

In the below picture, you can see how the message says “2 row(s) affected” while we only replaced or updated the values of a single row. During this action, the first record was deleted and then the new record was inserted. Hence the message says, “2 row(s) affected.”
UPSERT Using INSERT …… ON DUPLICATE KEY UPDATE:
So far, we have looked at two UPSERT commands. You may have noticed that each method had its shortfall or limitations if you may. The IGNORE command although ignored the duplicate entry, but it wasn’t updating any records. The REPLACE command, although it was updating, well technically it was not updating. It was deleting and then inserting the updated row.
A more popular and effective option than the first two is the ON DUPLICATE KEY UPDATE method. Unlike REPLACE, which is a destructive method, this method is non-destructive, meaning it doesn’t drop the duplicate rows first; instead, it directly updates them. The former can cause a lot of problems or errors , being a destructive method. Depending on your foreign key constraints, it can cause an error, or in a worst-case scenario, if your foreign key is set to cascade, it can delete the rows from the other linked table. This can be very devastating. So, we use this non-destructive method as it’s a lot safer.
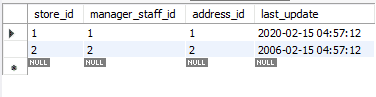
We will change the records updated using REPLACE to their original values. This time we will use the ON DUPLICATE KEY UPDATE method.

Notice how we used variables. These can be useful because you don’t need to add values in the statement, again and again, thus reducing the chances of error. The following is the updated table. To differentiate it from the original table, we changed the last_update attribute.
Conclusion:
Here we learned that UPSERT is a combination of two words Update and Insert. It works on the following principle that, if the new row doesn’t have any duplicates insert it and if it has duplicates perform the appropriate function according to the statement. There are three methods to perform UPSERT. Each method has some limits. The most popular is the ON DUPLICATE KEY UPDATE method. But depending on your requirements, anyone of the above methods can be of more use to you. I hope this tutorial is helpful to you.