
Unicode started with a fixed two-byte character set but later on, it was changed. Unicode consists of more than a hundred thousand characters and over a hundred languages to handle the vast multitude of different languages including complex characters like emojis, modifiers, and other unknown characters.
If we try to print a special character like an emoji in C language, the compiler will not give the result of printing that emoji. Rather, it returns a code for that emoji which will not be helpful for the user. To resolve this matter, we will practice the Unicode process in C.
Syntax:
To print a Unicode in C language, we use a function named_setmode in which we define the bits of character. In the following figure, we are giving U16 as a parameter, so it prints only the characters with 16 Bit limit. By default, C language only prints 8 Bit characters.
We use the wprintf instead of the printf function to print the line. And we will put L at the start of the statement that we want to print. Apart from the following syntax, we also have to add two includes which are:
#include <locale.h>
Note: Unicode is not a function or method in C, so there is no specific syntax to it. The syntax attached here is just for reference.

Example 1:
We will get a better understanding of the topic by following this example. In the figure, you can understand that we imported two extra libraries into our code. One is <wchar.h> and the other is <locale.h>. The <wchar.h> allows us to create the new datatypes to store the special characters in them. In C language, the <locale.h> header is used to define the location-based settings for example symbols like currencies and different date formats.
In the main function code block, we called a setlocale() function. This is the function of the <locale.h> header. In the setlocale() function, we passed a parameter of LC_CTYPE. This function has many parameters like LC_ALL which sets everything. LC_CTYPE affects all the character functions. It defines the character attributes like case conversion and character classifications.
After that, we declare two variables of wchar_t datatype: star1 and star2. We passed the Unicode for that emoji to our variables. After that, we wrote the values of our variables. We discussed earlier that we use the wprintf for Unicode printing. We can also see in the following code that we used the wprintf instead of printf.
After the successful execution of our C code, we get the following output. We can see that instead of printing the values that we passed to our constants, the system printed two stars. This is because we passed the Unicode for these stars to our variables. Then, because of the setlocale() function and its LC_CTYPE parameter, the system checked the character against that specific code and found a black and white star against that value. We also used the wprintf, so the system printed the character against the passed value of black star and white star.

Example 2:
In the previous example, we used a complex method to let you understand how unicoding works. In this example, we will perform a task to print a Unicode with the help of as less lines of code as possible. Depending upon the Operating System of your computer or machine, you can also print the Unicode characters by simply using the printf function. But for that purpose, you will have to pass a value \U to let the compiler know that it has to print a Unicode character.
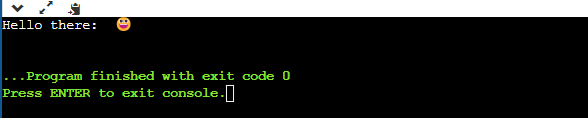
In this example, we try to print a smiley face which is a non-English character. We pass the Unicode value of that emoji to our code. In the following code, we simply printed a message “Hello there” with a smiley at the end of the statement. The code for happy smiley is “0001F600”. So, we passed it starting with \U just like how printing a string \s is passed so that the system understands that it has to print a string.
One thing that you might have noticed is that we have not used the headers which we used in the previous example. This is because we are not using those functions and techniques to let the system read the Unicode characters.
The output of our code after the compilation is as follows. The system prints the character message as it is but it first reads the \U sign and understands that the next value that is passed to it is a Unicode. So, the system will understand that it has to convert the next code into its respective emoji. After converting the value into the Unicode characters, the system will display the smiley face as an output.
Conclusion
We discussed about unicoding in this article. We explained what a Unicode character is, why it is used and what were the reasons that the unicoding standard was introduced. We discussed how to operate with the Unicode characters in C language as C language provides support for only about 256 characters. In the given examples, we explained how we can encode a set of values into a Unicode emoji or character. By the whole explanation that were previously given, we can say that unicoding is a very helpful approach to tackling the communication bridge. With the help of Unicode developers and programmers from every corner of the world, we can code and write the programs in their languages. On top of that, the whole applications can be developed in different languages which helps them to become more understandable and readable for the users. Unicoding helps to change the UI languages of not only the applications but of the whole Operating system as well. So, unicoding is not a specific function or library in the C language. It is an international coding standard that can be applied in any programming language.