Data is stored and managed in LangChain to build Natural Language Processing or NLP models and retrievers are used to access that data. Vector stores are built to place the data in LangChain, and the user can fetch data/objects from it, and it keeps track of all the data accessed with timestamp. The retrievers can be built by applying time weights to get the time for using the retriever from its memory.
This post demonstrates the process of using a time-weighted vector store retriever in LangChain.
How to Use Time-Weighted Vector Store Retrievers in LangChain?
To use the time-weighted vector store retriever in LangChain, simply follow this simple guide explaining multiple methods of time-weighted retriever:
Algorithm Syntax
The following is the syntax to score the algorithm using semantic similarity and time decay:
The above-mentioned code depicts that the retriever uses the combination of semantic_similarity and decay_rate which is followed by the hours_passed that determines the last access of the object in the retriever.
Installing Prerequisites
Before getting started with using time-weighted vector store retrievers in LangChain, simply install the LangChain module using the following code:
After that, simply install OpenAI using the following command:
FAISS is also required to install which is used to search data efficiently:
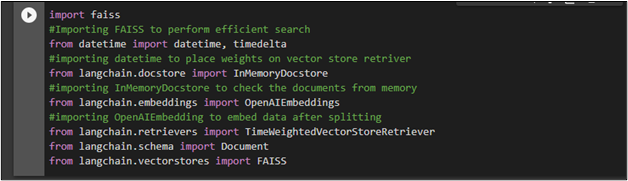
After installing the frameworks which are used below to import libraries to use time-weighted vector store retrievers in LangChain:
#Importing FAISS to perform efficient search
from datetime import datetime, timedelta
#importing datetime to place weights on vector store retriever
from langchain.docstore import InMemoryDocstore
#importing InMemoryDocstore to check the documents from memory
from langchain.embeddings import OpenAIEmbeddings
#importing OpenAIEmbedding to embed data after splitting
from langchain.retrievers import TimeWeightedVectorStoreRetriever
from langchain.schema import Document
from langchain.vectorstores import FAISS
Method 1: Use Low Decay Rate Vector Store Retriever
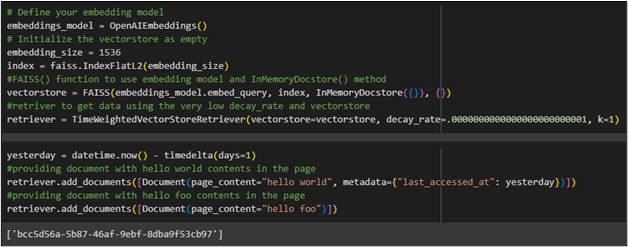
To build and configure the embedding model for the vector store, retrieve data using time-weighted retrievers. After that, configure the model using the “TimeWeightedVectorStoreRetriver()” function containing the parameters like decay_rate and value of kwargs:
embeddings_model = OpenAIEmbeddings()
# Initialize the vectorstore as empty
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
#FAISS() function to use embedding model and InMemoryDocstore() method
vectorstore = FAISS(embeddings_model.embed_query, index, InMemoryDocstore({}), {})
#retriver to get data using the very low decay_rate and vectorstore
retriever = TimeWeightedVectorStoreRetriever(vectorstore=vectorstore, decay_rate=.0000000000000000000000001, k=1)
Configure the time weight for the retriever using the following code and initialize objects to get the object with the lowest decay rate:
#providing document with hello world contents in the page
retriever.add_documents([Document(page_content="hello world", metadata={"last_accessed_at": yesterday})])
#providing document with hello foo contents in the page
retriever.add_documents([Document(page_content="hello foo")])
The following code is used to get the contents of the document which has the lowest decay rate and is the “hello world” document:
The following screenshot displays the contents of the “hello world” document with its metadata:

Method 2: Use High Decay Rate Vector Store Retriever
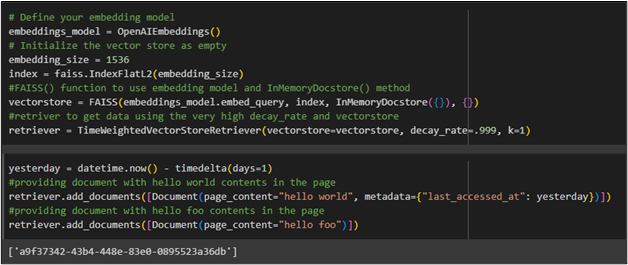
To configure the model, use the following code and fetch the document with a high decay rate. In this way, the memory will remember it longer:
embeddings_model = OpenAIEmbeddings()
# Initialize the vector store as empty
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
#FAISS() function to use embedding model and InMemoryDocstore() method
vectorstore = FAISS(embeddings_model.embed_query, index, InMemoryDocstore({}), {})
#retriver to get data using the very high decay_rate and vectorstore
retriever = TimeWeightedVectorStoreRetriever(vectorstore=vectorstore, decay_rate=.999, k=1)
The following code is used to add multiple documents which are fetched by retrievers to get their timestamp:
#providing document with hello world contents in the page
retriever.add_documents([Document(page_content="hello world", metadata={"last_accessed_at": yesterday})])
#providing document with hello foo contents in the page
retriever.add_documents([Document(page_content="hello foo")])
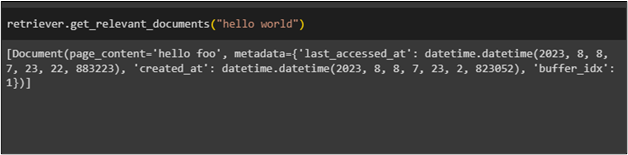
The document with a high decay rate will be returned using the following code as the memory will remember it for longer period of time:
The following screenshot displays the contents of the document with its metadata:
Method 3: Use Virtual Time Vector Store Retriever
The following code is used to import the “mock_now” library that allows the user to replace the original documents with the new ones:
import datetime
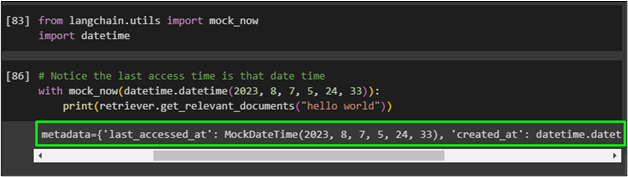
Use the following code to get the virtual time by changing the parameter values in the “datetime()” function from the previous methods:
with mock_now(datetime.datetime(2023, 8, 7, 5, 24, 33)):
print(retriever.get_relevant_documents("hello world"))
The following screenshot displays the metadata of the function which was created with the timestamp provided in the above code:
That is all about using time-weighted vector store retrievers in LangChain.
Conclusion
To use the time-weight vector store retriever in LangChain, simply install the necessary modules or frameworks like LangChain, FAISS, etc. After that, simply import libraries from these modules and build embedding models to use time-weighted vector store retrievers. The user can use a low decay rate, a high decay rate, and virtual time retrievers to fetch the contents and metadata of the files. This post demonstrated the process of using the time-weighted vector store retrievers in LangChain.